jvm file.encodingеұһжҖ§еј•иө·зҡ„HBaseд№ұз Ғй—®йўҳжҖҺд№Ҳи§ЈеҶі
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңjvm file.encodingеұһжҖ§еј•иө·зҡ„HBaseд№ұз Ғй—®йўҳжҖҺд№Ҳи§ЈеҶівҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁjvm file.encodingеұһжҖ§еј•иө·зҡ„HBaseд№ұз Ғй—®йўҳжҖҺд№Ҳи§ЈеҶій—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқjvm file.encodingеұһжҖ§еј•иө·зҡ„HBaseд№ұз Ғй—®йўҳжҖҺд№Ҳи§ЈеҶівҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
1гҖҒй—®йўҳпјҡ
жңҖиҝ‘еңЁеҫҖ HBase еҶҷдёӯж–Үзҡ„ж—¶еҖҷпјҢеҸ‘зҺ° hbase жҹҘеҮәжқҘзҡ„ж•°жҚ®дјҡжңүйғЁеҲҶдёӯж–Үд№ұз ҒдәҶпјҢиҖҢйғЁеҲҶдёӯж–ҮеҸҲжҳҜжӯЈеёёзҡ„пјҢжҢүзҗҶжқҘиҜҙпјҢдёҖиҲ¬зҡ„д№ұз Ғй—®йўҳиҰҒд№Ҳе…Ёд№ұпјҢиҰҒд№ҲдёҚд№ұгҖӮиҖғиҷ‘еҲ°еҮәзҺ°дёӯж–Үзҡ„ең°ж–№йғҪжҳҜжқҘжәҗдәҺ hdfs дёҠзҡ„дёҖдёӘй…ҚзҪ®ж–Ү件пјҢиҖҢиҝҷдёӘй…ҚзҪ®ж–Ү件еҸҜд»ҘзЎ®е®ҡжҳҜ utf-8 зј–з Ғзҡ„пјҢйӮЈжҺ’йҷӨдәҶеҺҹе§Ӣж–Ү件еҜјиҮҙзҡ„д№ұз ҒпјҢжғіжғі MR д»Јз ҒйҮҢд№ҹжІЎжңүиҪ¬з Ғзҡ„йҖ»иҫ‘пјҢд№ҹжҺ’йҷӨдәҶд»Јз Ғзҡ„й—®йўҳпјҢйӮЈе°ұеҸӘжңүдёҖз§ҚеҸҜиғҪпјҡHadoop йӣҶзҫӨзҡ„зі»з»ҹзҺҜеўғжҳҜејӮжһ„зҡ„пјҢиҝҷйҮҢйқўеҸҜиғҪж¶үеҸҠеҲ° linux гҖҒjava зҡ„зҺҜеўғеҸҳйҮҸгҖҒй…ҚзҪ®зҡ„й—®йўҳгҖӮ
2гҖҒжҺ’жҹҘпјҡ
пјҲ1пјүжү“еҚ°дәҶж•ҙдёӘйӣҶзҫӨзҡ„ echo $LANGгҖҒecho $LC_ALL зӯүlinuxзі»з»ҹеҸҳйҮҸпјҢеҸ‘зҺ°йғҪжҳҜдёҖиҮҙзҡ„пјҢжҺ’йҷӨдәҶ os зҺҜеўғзҡ„й—®йўҳгҖӮ
пјҲ2пјүеү©дёӢзҡ„йҮҚзӮ№ж”ҫеңЁдәҶ java зҺҜеўғдёҠпјҢеңЁд»Јз ҒйҮҢеҠ дёҠеҰӮдёӢдёӨеҸҘпјҢжү“еҚ°жҜҸжқЎи®°еҪ•зҡ„ ip е’Ң jvm зј–з ҒпјҢ然еҗҺзңӢзңӢд№ұз Ғзҡ„и®°еҪ•жҳҜйӮЈеҸ°жңәеҷЁдә§з”ҹзҡ„пјҢ并且еҪ“ж—¶ jvm child зҡ„зј–з Ғжғ…еҶөпјҡ
java.net.InetAddress test = java.net.InetAddress.getByName("localhost");
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ip"), Bytes.toBytes(test.getLocalHost().getHostAddress()));
put.add(Bytes.toBytes("cf"), Bytes.toBytes("ec"), Bytes.toBytes(System.getProperty("file.encoding")));еҗҢж—¶д№ҹзӣҙжҺҘ System.out.println еҮәзӣёеә”зҡ„дёӯж–Үеӯ—ж®өпјҢзңӢжҳҜеҶҷиҝӣ hbase д№ӢеүҚиҝҳжҳҜд№ӢеҗҺд№ұжҺүзҡ„гҖӮ
и·‘дәҶдёҖд»ҪжөӢиҜ•ж•°жҚ®еҗҺпјҢеҸ‘зҺ° hbase йҮҢзҡ„ ipгҖҒjvm зј–з ҒжҳҜжІЎжңү规еҫӢзҡ„пјҢ然еҗҺжҹҘзңӢ syso жү“еҚ°зҡ„ log еҸ‘зҺ°пјҢеңЁеҶҷ hbase д№ӢеүҚе·Із»Ҹе°ұе·Із»Ҹд№ұз ҒдәҶпјҢ然еҗҺжғіжғі hbase йҮҢзҡ„ж•°жҚ®д№ұз Ғд№ӢжүҖд»ҘжІЎжңү规еҫӢжҳҜеӣ дёә map еҗҺиҰҒ shuffleгҖҒreduce жүҚиғҪеҲ° hbaseгҖӮPSпјҡsysoutжң¬иә«ж— зј–з ҒжҰӮеҝөпјҢзұ»дјј linux дёӢзҡ„ catгҖҒheadгҖҒmore зӯүгҖӮ
然еҗҺеҶҚж¬ЎжҠҠ ipгҖҒjvmзј–з Ғ з»ҹи®Ўд»Јз Ғж”ҫеҲ° map йҳ¶ж®өиҫ“еҮәпјҢжһңзңҹеҸ‘зҺ°дәҶ规еҫӢпјҢйӣҶзҫӨдёӯжңүдёӨеҸ°жңәеҷЁзҡ„ jvm зј–з ҒдёҚдёҖиҮҙпјҢдёҚжҳҜ utf-8 зҡ„пјҡ
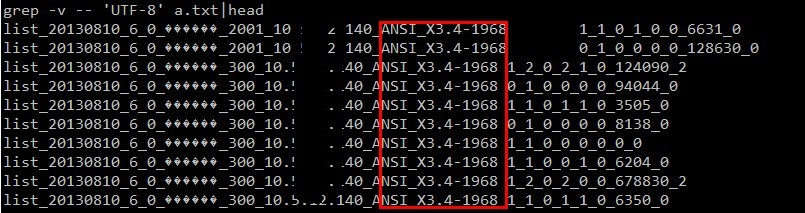
еҲ°иҝҷйҮҢжҲ‘们еҸҜд»ҘзҹҘйҒ“еҺҹеӣ дәҶпјҡз”ұдәҺйӣҶзҫӨдёӯдёӨеҸ°жңәеҷЁзҡ„ jvm еҸӮж•°пјҲfile.encodingпјүдёҚдёҖиҮҙеҜјиҮҙдәҶйғЁеҲҶдёӯж–Үз»“жһңзҡ„д№ұз ҒгҖӮ
3гҖҒи§ЈеҶіж–№жЎҲпјҡ
зҹҘйҒ“еҺҹеӣ дәҶпјҢйӮЈе°ұзңӢеҰӮдҪ•и§ЈеҶідәҶпјҢзӣ®зҡ„е°ұжҳҜиҰҒж”№еҸҳ file.encoding зҡ„еҖј гҖӮ
пјҲ1пјүж°ёд№…ж–№жЎҲпјҡ
з”ұдәҺиҝҷдёӘеҸӮж•°жҳҜ jvm зҡ„еҗҜеҠЁеҸӮж•°пјҢиҝҗиЎҢж—¶дёҚеҸҜиў«жӣҙж”№пјҲдҪ еҸҜд»ҘзҗҶи§ЈдёәиҝҷдёӘеҸӮж•°жҳҜдёӘе…ЁеұҖеҸӮж•°пјҢиҖҢдё”иў«зј“еӯҳдәҶпјҢеҰӮжһңдёҖж—ҰиҝҗиЎҢж—¶жӣҙж”№дәҶпјҢ еҸҜиғҪдјҡйҖ жҲҗж•ҙдёӘ jvm йҮҢйқўзҡ„зЁӢеәҸеҘ”жәғпјүпјҢдҪ еҸӘиғҪдҝ®ж”№зі»з»ҹзҡ„charset, жҲ–иҖ…jvmзҡ„еҗҜеҠЁеҸӮж•°йҮҢеҠ дёҠ -Dfile.encoding="UTF-8">пјҢдҪ иҝҗиЎҢж—¶ setProperty("file.encoding","ISO-8859-1"); иҝҷж ·жҳҜжІЎз”Ёзҡ„пјҢsoпјҢж°ёд№…зҡ„и§ЈеҶіеҠһжі•жҳҜпјҡе•Ҙж—¶еҖҷжҠҠиҝҷдёӨеҸ°жңәеҷЁoffline ж”№зј–з ҒеҗҺеҶҚonlineпјҢ然еҗҺеҶҚжүӢеҠЁжү§иЎҢдёӢ data balanceгҖӮ
жҲ–иҖ…еҸҜд»ҘеңЁжҸҗдәӨдҪңдёҡзҡ„ж—¶еҖҷи®ҫзҪ®дҪңдёҡеҸӮж•°пјҡ вҖ“Dmapred.child.env="LANG=en_US.UTF-8,LC_ALL=en_US.UTF-8"
пјҲ2пјүдёҙж—¶е·Ҙж–№жЎҲпјҡ
дёҚжғіиҝҷд№ҲеӨ§еҠЁе№ІжҲҲпјҢжғіиҰҒдёҙж—¶и§ЈеҶіж–№жЎҲпјҢд№ҹиЎҢпјҢйӮЈе°ұйңҖиҰҒеңЁе’ұ们иҮӘе·ұзҡ„дёҡеҠЎд»Јз ҒйҮҢз»•ејҖ jvm жҸҗдҫӣзҡ„й»ҳи®Ө file.encoding зј–з ҒпјҢиҮӘе·ұжҢҮе®ҡзј–з Ғпјҡ
BufferedReader in = new BufferedReader(new FileReader(path.toString()));
жҚўжҲҗпјҡ
BufferedReader in = new BufferedReader((new InputStreamReader(new FileInputStream(path.toString()),"utf-8")));
дёҠйқўдёҖеҸҘжҳҜжҲ‘д№ӢеүҚд№ұз Ғзҡ„д»Јз ҒпјҢеҰӮжһңдҪ жІЎжңүжҢҮе®ҡиҜ»еҸ–зј–з ҒпјҢйӮЈд№Ҳ jvm дјҡдҪҝз”ЁиҮӘе·ұзҡ„ file.encodingпјҢиҝҷж ·е°ұдјҡйҖ жҲҗеңЁжҹҗдәӣжңәеҷЁдёҠиҜ»еҸ–ж–Ү件е°ұд№ұжҺүдәҶгҖӮдёӢйқўдёҖеҸҘжҳҜиҮӘе·ұжҢҮе®ҡзј–з ҒпјҢиҝҷж ·з»•ејҖдәҶ jvm зҡ„й»ҳи®Өзј–з ҒпјҢдёҺ jvm д»ҺжӯӨеҪўеҗҢйҷҢи·Ҝ~
PSпјҡFileReader иІҢдјјжІЎжңүжҸҗдҫӣжҢҮе®ҡзј–з Ғзҡ„жһ„йҖ ж–№жі•пјҢжүҖд»ҘжҚўжҲҗдәҶдёӢйқўзҡ„зұ»гҖӮ
пјҲ3пјүз–‘й—®пјҡ
дёәд»Җд№Ҳд№ӢеүҚдёҖзӣҙйғҪжІЎд№ұз ҒпјҢиҖҢиҝҷж¬ЎиҜ»ж–Ү件еҚҙд№ұз ҒдәҶе‘ўпјҹ
йӮЈжҳҜеӣ дёә hbase зҡ„ BytesгҖҒmap зҡ„ fileinputformat key/valueгҖҒmapreduce зҡ„ context.write й»ҳи®ӨйғҪжҳҜиҮӘе·ұзЎ¬зј–з ҒдәҶ utf-8пјҢеҒҡеҲ°дәҶ е’Ң jvm зј–з Ғж— е…іпјҢжүҖд»ҘдёҚдјҡйҒҮеҲ°дёҠиҝ°й—®йўҳгҖӮ
4гҖҒж·ұе…ҘзҗҶи§Ј jvm зҡ„ -Dfile.encoding еҸӮж•°
дёҠйқўиҜҙдәҶиҝҷд№ҲеӨҡпјҢеҸҜиғҪжңүеҗҢеӯҰиҝҳжҳҜдёҚеӨ§жҳҺзҷҪпјҡjvm зҡ„иҝҷеҸӮж•°жңүжҜӣз”Ёе•ҠпјҹдёәжҜӣд№ӢеүҚйғҪжІЎеҗ¬иҝҮиҝҷзҺ©ж„Ҹе‘ўпјҹ
жҒ©пјҢжІЎеҗ¬иҝҮжӯЈеёёпјҢд№ӢеүҚжҲ‘д№ҹжІЎеҗ¬иҝҮе“Ҳ~
д»Һжәҗз ҒејҖе§ӢиҝҪиёӘ
еңЁJDK 1.6.0_20зҡ„src.zipж–Ү件дёӯ,жҹҘжүҫеҢ…еҗ«file.encodingеӯ—зңјзҡ„ж–Ү件.
е…ұжүҫеҲ°4дёӘ, еҲҶеҲ«жҳҜ:
пјҲaпјүе…ҲдёҠйҮҚеӨҙжҲҸ java.nio.Charsetзұ»:
public static Charset defaultCharset() {
if (defaultCharset == null) {
synchronized (Charset.class) {
java.security.PrivilegedAction pa = new GetPropertyAction("file.encoding");
String csn = (String) AccessController.doPrivileged(pa);
Charset cs = lookup(csn);
if (cs != null)
defaultCharset = cs;
else
defaultCharset = forName("UTF-8");
}
}
return defaultCharset;
}еңЁjavaдёӯпјҢеҰӮжһңжІЎжңүжҢҮе®ҡcharsetзҡ„ж—¶еҖҷпјҢжҜ”еҰӮnew String(byte[] bytes), йғҪдјҡи°ғз”ЁCharset.defaultCharset()зҡ„ж–№жі•пјҢжҲ‘们еҸҜд»Ҙжё…жҘҡзҡ„зңӢеҲ°defaultCharsetжҳҜеҸӘиғҪиў«еҲқе§ӢеҢ–дёҖж¬ЎпјҢиҝҷйҮҢиҝҳжҳҜжңүзӮ№е°Ҹй—®йўҳзҡ„пјҢеңЁеӨҡзәҝзЁӢ并еҸ‘и°ғз”Ёзҡ„ж—¶еҖҷиҝҳжҳҜдјҡеҲқе§ӢиҜқеӨҡж¬ЎпјҢеҪ“然еҗҺйқўйғҪжҳҜд»ҺcacheпјҲlookupзҡ„еҮҪж•°пјүйҮҢиҜ»еҮәжқҘзҡ„пјҢй—®йўҳд№ҹдёҚеӨ§гҖӮ
еҪ“жҲ‘们еңЁж”№еҸҳSystem.getPropertiesйҮҢзҡ„file.encoding зҡ„ж—¶еҖҷпјҢdefaultCharsetе·Із»Ҹиў«еҲқе§ӢеҢ–иҝҮдәҶпјҢжүҖд»ҘдёҚдјҡеңЁи°ғз”ЁеҲқе§ӢеҢ–зҡ„д»Јз ҒгҖӮ
еҪ“jvm еҗҜеҠЁзҡ„ж—¶еҖҷпјҢload class, жңҖеҗҺи°ғз”ЁmainеҮҪж•°д№ӢеүҚпјҢdefaultCharsetе·Із»ҸеҲқе§ӢеҢ–еҘҪпјҢиҖҢеҫҲеӨҡеҮҪж•°йҮҢйғҪжҺүз”ЁдәҶиҝҷдёӘж–№жі•иұЎString.getBytes, иҝҳжңү InputStreamReaderпјҢ InputStreamWriter йғҪжҳҜи°ғз”ЁдәҶ Charset.defaultCharset()зҡ„ж–№жі•гҖӮ
пјҲbпјүjava.net.URLEncoderзҡ„йқҷжҖҒжһ„йҖ ж–№жі•, еҪұе“ҚеҲ°зҡ„ж–№жі• java.net.URLEncoder.encode(String)
жҒ©пјҢиҝҷйҮҢд№ҹйңҖиҰҒжіЁж„ҸпјҢд№ӢеүҚе·Із»ҸжңүеҗҢеӯҰжҺүеқ‘йҮҢеҺ»дәҶпјҢиҜ·дҪҝз”Ёпјҡencode(String s, String enc) ж–№жі•пјҢжӯӨжі•ж— дҫ§жјҸпјҢдёҖи§үзқЎеҲ°еӨ§еӨ©дә®~
пјҲcпјүcom.sun.org.apache.xml.internal.serializer.Encodingзҡ„getMimeEncodingж–№жі•(209иЎҢиө·)
пјҲdпјүжңҖеҗҺдёҖдёӘjavax.print.DocFlavorзұ»зҡ„йқҷжҖҒжһ„йҖ ж–№жі•
еҸҜд»ҘзңӢеҲ°,зі»з»ҹеҸҳйҮҸfile.encodingеҪұе“ҚеҲ°
1. Charset.defaultCharset() JavaзҺҜеўғдёӯжңҖе…ій”®зҡ„зј–з Ғи®ҫзҪ®
2. URLEncoder.encode(String) WebзҺҜеўғдёӯжңҖеёёйҒҮеҲ°зҡ„зј–з ҒдҪҝз”Ё
3. com.sun.org.apache.xml.internal.serializer.Encoding еҪұе“ҚеҜ№ж— зј–з Ғи®ҫзҪ®зҡ„xmlж–Ү件зҡ„иҜ»еҸ–
4. javax.print.DocFlavor еҪұе“Қжү“еҚ°зҡ„зј–з Ғ
еҲ°жӯӨпјҢе…ідәҺвҖңjvm file.encodingеұһжҖ§еј•иө·зҡ„HBaseд№ұз Ғй—®йўҳжҖҺд№Ҳи§ЈеҶівҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ





