本篇内容介绍了“如何用python爬虫抓豆瓣电影数据”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
#生成代理池子,num为代理池容量
def proxypool(num):
n = 1
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP')
fp = open('host.txt', 'r')
proxys = list()
ips = fp.readlines()
while n<num:
for p in ips:
ip = p.strip('\n').split('\t')
proxy = 'http:\\' + ip[0] + ':' + ip[1]
proxies = {'proxy': proxy}
proxys.append(proxies)
n+=1
return proxys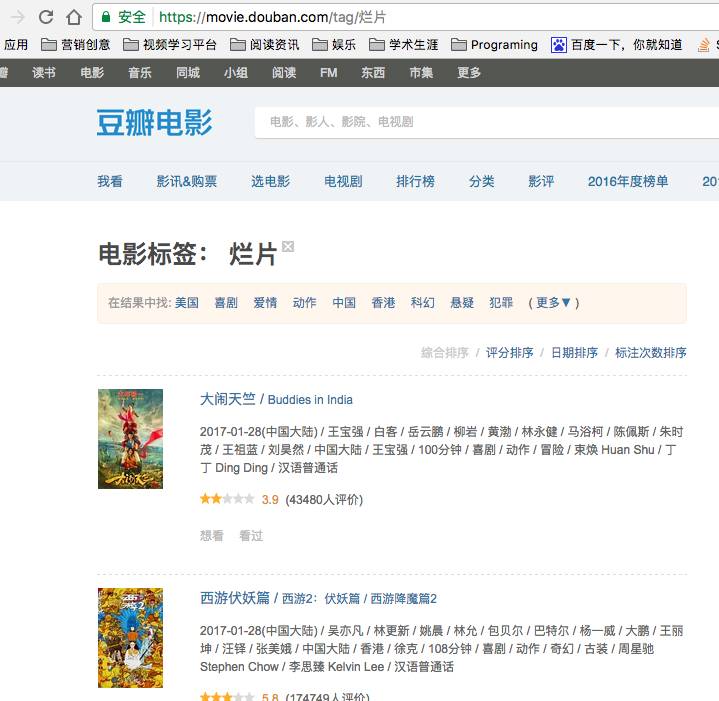
#爬豆瓣电影的代码
def fetch_movies(tag, pages, proxys):
os.chdir(r'/Users/apple888/PycharmProjects/proxy IP/豆瓣电影')
url = 'https://movie.douban.com/tag/爱情?start={}'
headers = { 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/'
'537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Mobile Safari/537.36'}
#用csv文件保存数据
csvFile = open("{}.csv".format(tag), 'a+', newline='', encoding='utf-8')
writer = csv.writer(csvFile)
writer.writerow(('name', 'score', 'peoples', 'date', 'nation', 'actor'))
for page in range(0, pages*(20+1), 20):
url = url.format(page)
try:
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
while respones.status_code!=200:
respones = requests.get(url, headers=headers, proxies=random.choice(proxys))
soup = BeautifulSoup(respones.text, 'lxml')
movies = soup.find_all(name='div', attrs={'class': 'pl2'})
for movie in movies:
movie = BeautifulSoup(str(movie), 'lxml')
movname = movie.find(name='a')
# 影片名
movname = movname.contents[0].replace(' ', '').strip('\n').strip('/').strip('\n')
movInfo = movie.find(name='p').contents[0].split('/')
# 上映日期
date = movInfo[0][0:10]
# 国家
nation = movInfo[0][11:-2]
actor_list = [act.strip(' ').replace('...', '')
for act in movInfo[1:-1]]
# 演员
actors = '\t'.join(actor_list)
# 评分
score = movie.find('span', {'class': 'rating_nums'}).string
# 评论人数
peopleNum = movie.find('span', {'class': 'pl'}).string[1:-4]
writer.writerow((movname, score, peopleNum, date, nation, actors))
except:
continue
print('共有{}页,已爬{}页'.format(pages, int((page/20))))执行上面函数的代码
import timestart = time.time()
proxyPool= proxypool(50)
fetch_movies('烂片', 111, proxyPool)end = time.time()
lastT = int(end-start)
print('耗时{}s'.format(lastT))
“如何用python爬虫抓豆瓣电影数据”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





