表示应用程序,包含一个 Driver Program 和若干 Executor。(编写的spark代码)
Spark 中的 Driver 即运行上述 Application 的 main()函数并且创建 SparkContext,其中创建 SparkContext 的目的是为了准备 Spark 应用程序的运行环境。由 SparkContext 负责与 ClusterManager 通信,进行资源的申请,任务的分配和监控等。程序执 行完毕后关闭 SparkContext。
在 Standalone 模式中即为 Master(主节点),控制整个集群,监控 Worker。 在 YARN 模式中为资源管理器(resourcemanager)。
整个应用的上下文,控制应用程序的生命周期,负责调度各个运算资源, 协调各个 Worker 上的 Executor。初始化的时候,会初始化 DAGScheduler 和 TaskScheduler 两个核心组件。
Spark 的基本计算单元,一组 RDD 可形成执行的有向无环图 RDD Graph。
将application拆分成多个job,对于每一个job构建成一个DAG,将这个DAG划分成多个stage,最终把stage提交给TaskScheduler。
将DAGScheduler提交过来的stage,拆分成多个task集合,然后将 TaskSet 提交给 Worker(集群)运行,每个 Executor 运行什么 Task 就 是在此处分配的。
集群中可以运行 Application 代码的节点。在 Standalone 模式中指的是通过 slave 文件配置的 worker 节点,在 Spark on Yarn 模式中指的就是 NodeManager 节点。(即运行Executor的节点)
某个 Application 运行在 Worker 节点上的一个进程,该进程负责运行某些 task, 并且负责将数据存在内存或者磁盘上。在 Spark on Yarn 模式下,其进程名称为 CoarseGrainedExecutorBackend,一个 CoarseGrainedExecutorBackend 进程有且仅有一个 executor 对象,它负责将 Task 包装成 taskRunner,并从线程池中抽取出一个空闲线程运行 Task, 这样,每个 CoarseGrainedExecutorBackend 能并行运行 Task 的数据就取决于分配给它的 CPU 的个数。
每个 Job 会被拆分很多组 Task,每组作为一个 TaskSet,其名称为 Stage
包含多个 Task 组成的并行计算,是由 Action 行为触发的,触发一次action,就是一个job
线程级别的上下文,存储运行时的重要组件的引用。SparkEnv 内创建并包含 如下一些重要组件的引用:
MapOutPutTracker:负责 Shuffle 元信息的存储。
BroadcastManager:负责广播变量的控制与元信息的存储。
MapOutPutTracker:负责存储管理、创建和查找块.
MetricsSystem:监控运行时性能指标信息。
SparkConf:负责存储配置信息。
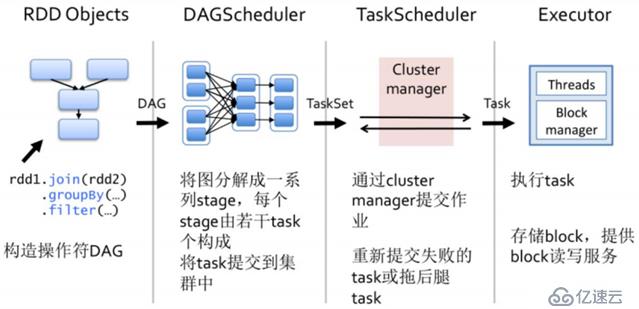
第一步(构建DAG):使用算子操作RDD进行各种transformation 操作,最后通过action算子触发spark的作业提交。提交后,spark会根据转化过程中所产生的RDD之间依赖关系构建DAG有向无环图。
第二步(DAG的切割):DAG 切割主要根据 RDD 的依赖是否为宽依赖来决定切割节点,当遇到宽依赖就将任务划分 为一个新的调度阶段(Stage)。每个 Stage 中包含一个或多个 Task。这些 Task 将形成任务集 (TaskSet),提交给底层调度器进行调度运行。
第三步(任务调度):每一个 Spark 任务调度器只为一个 SparkContext 实例服务。当任务调度器收到任务集后负责 把任务集以 Task 任务的形式分发至 Worker 节点的 Executor 进程中执行,如果某个任务失败, 任务调度器负责重新分配该任务的计算。
第四步(执行任务):当 Executor 收到发送过来的任务后,将以多线程(会在启动 executor 的时候就初始化好了 一个线程池)的方式执行任务的计算,每个线程负责一个任务,任务结束后会根据任务的类 型选择相应的返回方式将结果返回给任务调度器。(cluster manager)。
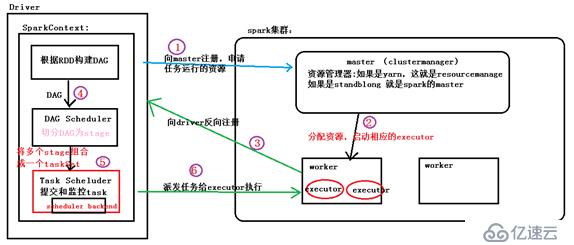
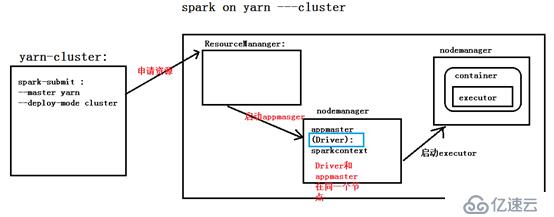
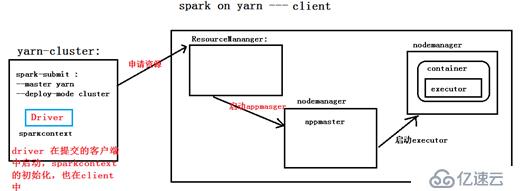
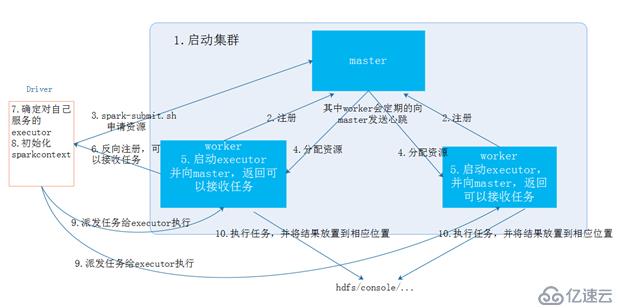
根据上图的信息:
- 启动spark集群,通过spark-shell启动spark集群中的相应的master和worker。master是集群的管理者,清楚集群中的从节点的个数、从节点的资源情况,以及从节点是否存活。
- worker节点的注册,当worker进程启动之后,向master进程发送注册消息,所以worker是一个基于AKKA actor的事件驱动模型,master同样也是。worker注册成功之后,也会向master发送心跳,监听主节点是否存在,以及汇报心跳。
-driver提交作业:driver向spark集群提交作业,就是向master提交作业,注册spark应用需要的资源,说白了就是向master申请应用程序运行的资源。
- master分配资源:当driver提交作业请求之后,mater接收到相应的请求,会向worker节点指派相应的作业任务,就是在worker节点中启动相应的executor进程,executor维护一个线程池,线程池中的线程是真正去执行task任务。
- worker启动executor:当worker节点接收到master启动executor之后,会相应的启动一个或者多个executor,并向master汇报启动成功信息,表示可以接收任务。
- 向 driver的反向注册:当worker节点启动executor成功之后,会向driver反向注册,告诉driver哪些executor可以接收任务,执行spark任务。
- driver接收worker的注册:driver接收到worker的注册信息之后,就初始化相应的 executor_info信息,根据worker发送过来的executorid,可以确定,哪些executor对自己服务。
- driver初始化sparkcontext:sparkcontext构建RDD,然后通过DAGscheduler将RDD切分成多个stage,然后分装成为taskset交给task schdeluder。
- taskscheduler向worker中的executor发送task执行相应的任务
- executor执行任务:当executor进程接收到了driver发送过来的taskset之后,进行反序列化然后将这些task分装到一个叫taskrunner的线程中,然后放入到本地的线程池中调度相应的作业执行。当执行完毕之后,将所得到的结果进行落地(返回给driver/打印输出/保存到本地/保存到hdfs...)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





