介绍:正常情况下,一个RDD是不包含真实数据的,只包含描述这个RDD元数据信息,如果对这个RDD调用cache方法,那么这个RDD的数据,依然没有真实数据,直到第一次调用一个action的算子触发了这个RDD的数据生成,那么cache操作就会把数据存储在内存中,所以第二次重复利用这个RDD的时候,计算速度将会快很多。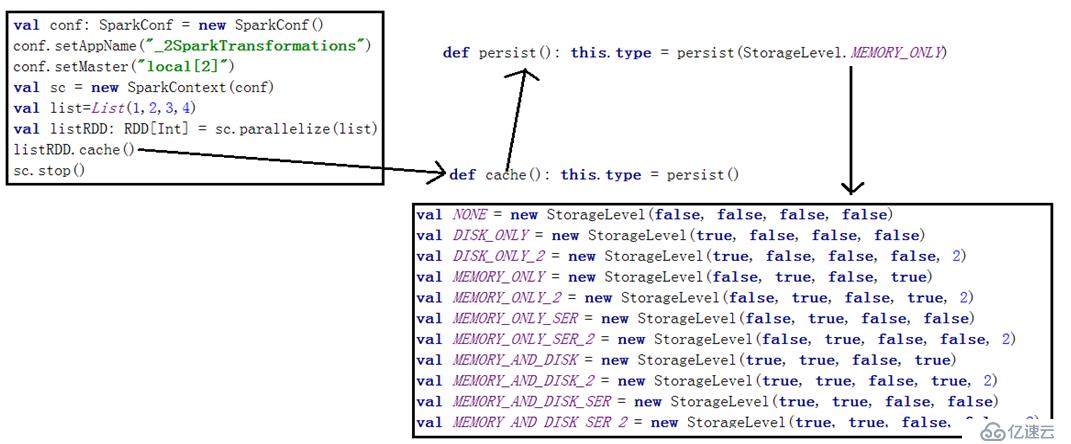
其中最主要的储存级别为:
//不存储在内存也不在磁盘
val NONE = new StorageLevel(false, false, false, false)
//存储在磁盘
val DISK_ONLY = new StorageLevel(true, false, false, false)
//存储在磁盘,保存2份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
//存储在内存
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//存储在内存 保存2份
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
//存储在内存并序列化
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
//内存磁盘结合使用
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
//存储在堆外内存
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)相应的操作:
//设置持久化
listRDD.cache()
//移除持久化
listRDD.unpersist()
介绍:在 Spark 程序中,当一个传递给 Spark 操作(例如 map 和 reduce)的函数在远程节点上面运行 时,Spark 操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读 写变量是低效的,但是,Spark 还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(Broadcast Variable)和累加器(Accumulator)。
在不使用广播变量的时候:
object SparktTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("SparktTest")
conf.setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val list = List(("math", 18), ("hbase", 18), ("hive", 22), ("hive", 18))
val listRDD: RDD[(String, Int)] = sc.parallelize(list)
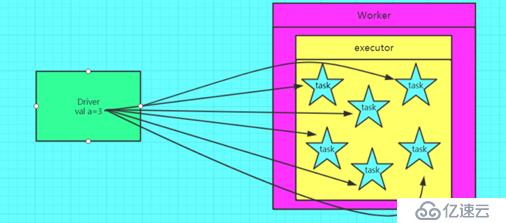
//这一句代码是在 driver中执行的,相当于这个变量是在driver进程中的。
val a=3
/**
* kv._2+a这句代码是在executor中执行的,
* 其中a这个变量会在和f序列化的过程中,会携带过去。
* 并且每一个task都会复制一份,可想而知如果这个a变量是一个大对象,那就是一个灾难
*/
listRDD.map(kv=>(kv._1,kv._2+a))
}
}
使用广播变量的时候:
object SparktTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("SparktTest")
conf.setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
val list = List(("math", 18), ("hbase", 18), ("hive", 22), ("hive", 18))
val listRDD: RDD[(String, Int)] = sc.parallelize(list)
//这一句代码是在 driver中执行的,相当于这个变量是在driver进程中的。
val a=3
//设置广播变量,每一个executor中的task共享一个广播变量
val broadcast: Broadcast[Int] = sc.broadcast(a)
listRDD.map(kv=>{
//获取广播变量
val aa=broadcast.value
(kv._1,kv._2+aa)
})
}
}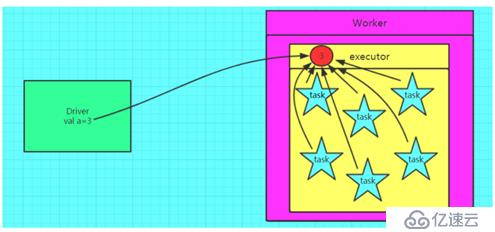
总结:如果 executor 端用到了 Driver 的变量,如果不使用广播变量在 Executor 有多少 task 就有 多少 Driver 端的变量副本。如果 Executor 端用到了 Driver 的变量,如果使用广播变量在每个 Executor 中都只有一份 Driver 端的变量副本。
使用的广播变量的条件:
- 广播变量只能在driver端定义,不能在executor中定义
- 在 Driver 端可以修改广播变量的值,在 Executor 端无法修改广播变量的值。
- 广播变量的值越大,使用广播变量的优势越明显
- task个数越多,使用广播变量的优势越明显
介绍:在 Spark 应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会在 driver 端进行全局汇总,即在分布式运行时每个 task 运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
案例:
object SparktTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("SparktTest")
conf.setMaster("local[2]")
val sc: SparkContext = new SparkContext(conf)
//统计文件有多少行
val hdfsRDD: RDD[String] = sc.textFile("/data/word.txt")
//设置累加器
val mysum: LongAccumulator = sc.longAccumulator("Mysum")
hdfsRDD.map(line=>{
mysum.add(1)
line
}).collect() //触发提交操作
//获取累加器的值
println(mysum.value)
//重置累加器
mysum.reset()
}
}使用累加器的注意事项
- 累加器在 Driver 端定义赋初始值,累加器只能在 Driver 端读取最后的值,在 Excutor 端更新。
- 累加器不是一个调优的操作,因为如果不这样做,结果是错的。
- 累加器不是一个调优的操作,因为如果不这样做,结果是错的。
- 累加器不是一个调优的操作,因为如果不这样做,结果是错的。
- 如果系统自带的累加器不能满足要求,还可以自定义累加器
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





