еҹәдәҺAnyproxyrhrh дҪҝз”Ё"дёӯй—ҙдәәж”»еҮ»"зҲ¬еҸ–е…¬дј—еҸ·жҺЁйҖҒ
жң¬зҜҮж–Үз« дёәеӨ§е®¶еұ•зӨәдәҶеҹәдәҺAnyproxyrhrh дҪҝз”Ё"дёӯй—ҙдәәж”»еҮ»"зҲ¬еҸ–е…¬дј—еҸ·жҺЁйҖҒпјҢеҶ…е®№з®ҖжҳҺжүјиҰҒ并且容жҳ“зҗҶи§ЈпјҢз»қеҜ№иғҪдҪҝдҪ зңјеүҚдёҖдә®пјҢйҖҡиҝҮиҝҷзҜҮж–Үз« зҡ„иҜҰз»Ҷд»Ӣз»ҚеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
д»ҘеүҚеҚҡе®ўдёҖзӣҙдҪҝз”Ёзҡ„жҳҜеҲ«дәәеҲ¶дҪңзҡ„жЎҶжһ¶пјҢtypechoгҖҒWordPressзӯүйғҪжңүдҪҝз”ЁиҝҮпјҢдҪҶз”ұдәҺжҳҜеҲ«дәәзҡ„жЎҶжһ¶пјҢе§Ӣз»ҲдёҚзҹҘйҒ“е…¶еҶ…йғЁиҝҗдҪңзҡ„еҺҹзҗҶгҖӮиҝҷж¬ЎдҪҝз”ЁNode.jsе®Ңе…ЁйҮҚжһ„дәҶдёҖйҒҚпјҢдҪҝеҫ—жҲ‘еҜ№ж•ҙдёӘеҚҡе®ўзҡ„иҝҗдҪңеҺҹзҗҶжё…жҷ°дәҶи®ёеӨҡпјҢд»ҘеүҚзңӢиө·жқҘеҫҲеӨҚжқӮзҡ„дёңиҘҝпјҲWordPress з•ҷдёӢзҡ„第дёҖеҚ°иұЎпјҢиҷҪ然WordPressе…¶е®һдёҚе…ЁжҳҜз”ЁжқҘеҒҡеҚҡе®ўзҡ„пјүпјҢзҺ°еңЁзңӢиө·жқҘз«ҹжҳҜиҝҷд№Ҳз®ҖеҚ•пјҢеҰӮжһңжңүз”ЁжЎҶжһ¶жҗӯе»әеҚҡе®ўзҡ„жңӢеҸӢпјҢе»әи®®е®Ңе…ЁиҮӘе·ұеҒҡдёҖдёӘиҜ•иҜ•гҖӮеҪ“然пјҢиҝҷдәӣйғҪдёҚжҳҜжң¬ж¬ЎжҺЁйҖҒзҡ„йҮҚзӮ№пјҢеҚҠиҮӘеҠЁеҢ–зҲ¬еҸ–иҮӘе·ұзҡ„е…¬дј—еҸ·жҺЁйҖҒжүҚжҳҜйҮҚзӮ№гҖӮ
зҲ¬еҸ–жүҖйңҖиҰҒзҡ„зҺҜеўғдёҺе·Ҙе…·пјҡ
еҗҺз«ҜпјҡNode.js + MongoDB
д»ЈзҗҶжңҚеҠЎеҷЁпјҡAnyproxy
дёҖдёӘе®үеҚ“жЁЎжӢҹеҷЁ
жңҚеҠЎеҷЁзҺҜеўғпјҡ
Node.js + MongoDB
йҰ–е…Ҳд»Ӣз»ҚдёҖдёӢAnyproxy, иҝҷжҳҜдёҖдёӘеҹәдәҺNode.jsзҡ„д»ЈзҗҶжңҚеҠЎеҷЁпјҢжң¬йЎ№зӣ®дёӯпјҢAnyproxyзҡ„дҪңз”ЁеҰӮдёӢпјҡиӢҘжҠҠжҲ‘们жң¬жңәеҪ“еҒҡд»ЈзҗҶжңҚеҠЎеҷЁпјҢжүӢжңәжЁЎжӢҹеҷЁдёӯзҡ„еҫ®дҝЎеҪ“жҲҗе®ўжҲ·з«ҜпјҢйӮЈд№Ҳе…¶иҝҗдҪңеҺҹзҗҶеҸҜд»ҘеҰӮдёӢеӣҫжүҖзӨәгҖӮжүӢжңәе®ўжҲ·з«Ҝ(Client)еҸ‘йҖҒиҜ·жұӮз»ҷд»ЈзҗҶжңҚеҠЎеҷЁ(ServerпјҢеҚіжң¬жңә)пјҢжң¬жңәеҶҚе°ҶиҝҷдёӘиҜ·жұӮеҸ‘йҖҒз»ҷеҫ®дҝЎжңҚеҠЎеҷЁпјҢеҫ®дҝЎжңҚеҠЎеҷЁиҝ”еӣһдҝЎжҒҜйңҖиҰҒз»ҸиҝҮжң¬жңәпјҢеҶҚз”ұжң¬жңәдј йҖ’з»ҷжүӢжңәе®ўжҲ·з«ҜгҖӮ
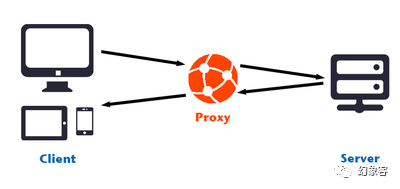
еңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢжң¬жңәжүҝжӢ…дёӯй—ҙдәәзҡ„дҪңз”ЁпјҢиҖҢжҺҘеҸ—еҲ°еҫ®дҝЎиҝ”еӣһзҡ„дҝЎжҒҜеҗҺпјҢжҲ‘们еҸҜд»ҘеҜ№йӮЈдёӘдҝЎжҒҜжӨҚе…Ҙи„ҡжң¬пјҢеҶҚеҸ‘йҖҒз»ҷжүӢжңәе®ўжҲ·з«ҜгҖӮиҝҷе°ұжҳҜдёӯй—ҙдәәж”»еҮ»гҖӮ
еҜ№дәҶпјҢдҪҝз”ЁAnyproxyиҝҳжңүдёҖдёӘеҘҪеӨ„е°ұжҳҜпјҢе®ғж”ҜжҢҒHTTPSпјҢе®ғиғҪеӨҹз”ҹжҲҗиҜҒд№ҰпјҢдҪҝеҫ—е®ўжҲ·з«Ҝе’Ңд»ЈзҗҶжңҚеҠЎеҷЁз«Ҝдә’зӣёдҝЎд»»пјҢд»ҺиҖҢиғҪжҺҘ收HTTPSиҜ·жұӮе’ҢеӣһеӨҚпјҢиҖҢе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜдёӯпјҢи®ёеӨҡиҜ·жұӮйғҪжҳҜHTTPSзҡ„гҖӮ
жӯҘйӘӨеҰӮдёӢпјҲеҸӮиҖғиҮӘ пјҡhttps://zhuanlan.zhihu.com/p/24302048пјү
1.ж–°е»әдёҖдёӘNode.jsйЎ№зӣ®пјҢж–°е»әMongoDBж•°жҚ®еә“пјҲеҸҜе…ҲеңЁжң¬ең°дёҠиҝӣиЎҢи°ғиҜ•пјүпјҢж–°е»әдёҖдёӘеҗҚдёәblogзҡ„еә“пјҢеҗҚдёәarticlesзҡ„Collections.
2.иҝҗиЎҢз»Ҳз«Ҝжү§иЎҢдёӢйқўиҝҷдёӘе‘Ҫд»Өе®үиЈ…Anyproxyпјҡ
sudo npm -g install anyproxy
3.з”ҹжҲҗиҜҒд№ҰпјҢдҪҝе…¶ж”ҜжҢҒhttps
sudo anyproxy --root
4.еҗҜеҠЁAnyproxy, иҝҗиЎҢ
sudo anyproxy -i
5.еңЁе®үеҚ“жЁЎжӢҹеҷЁдёӯе®үиЈ…иҜҒд№Ұпјҡ
еҗҜеҠЁAnyproxy, еңЁжөҸи§ҲеҷЁдёӯи®ҝй—® localhost:8002/qr_root еҸҜд»ҘиҺ·еҸ–иҜҒд№Ұи·Ҝеҫ„зҡ„дәҢз»ҙз ҒпјҢ移еҠЁз«Ҝе®үиЈ…ж—¶дјҡжҜ”иҫғдҫҝжҚ·пјҢдҪҝз”Ёеҫ®дҝЎиҜҶеҲ«дәҢз»ҙз ҒеҚіеҸҜе®ҢжҲҗе®үиЈ…гҖӮ
6.и®ҫзҪ®д»ЈзҗҶпјҢжү“ејҖжЁЎжӢҹеҷЁзҡ„WiFiпјҢдҝ®ж”№WiFi-дҪҝз”Ёд»ЈзҗҶпјҢд»ЈзҗҶжңҚеҠЎеҷЁең°еқҖе°ұжҳҜиҝҗиЎҢanyproxyзҡ„з”өи„‘зҡ„ipең°еқҖгҖӮд»ЈзҗҶжңҚеҠЎеҷЁй»ҳи®Өз«ҜеҸЈжҳҜ8001гҖӮ
зҺ°еңЁеҫ®дҝЎдёҠд»»дҪ•иҒ”зҪ‘ж“ҚдҪңпјҢеңЁиҝҗиЎҢAnyproxyзҡ„з»Ҳз«ҜдёӯжҲ–жү“ејҖ http://localhost:8002 еә”иҜҘйғҪеҸҜд»ҘзңӢеҲ°жңҚеҠЎеҷЁиҝ”еӣһзҡ„дҝЎжҒҜдәҶгҖӮеҰӮеӣҫжүҖзӨәпјҡ
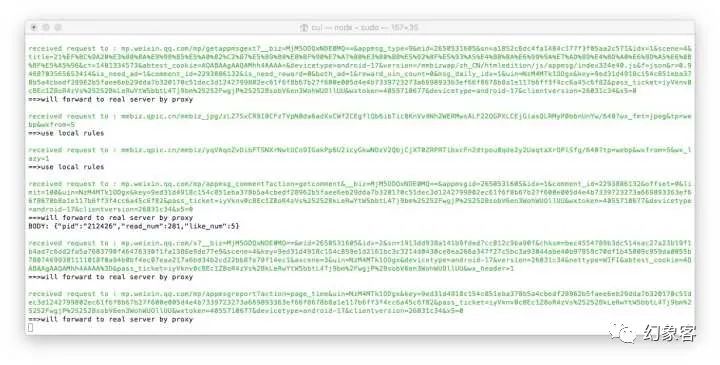
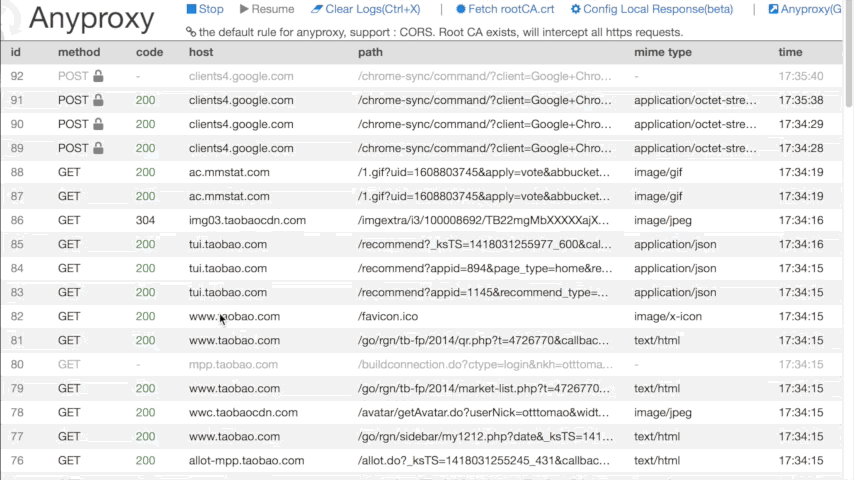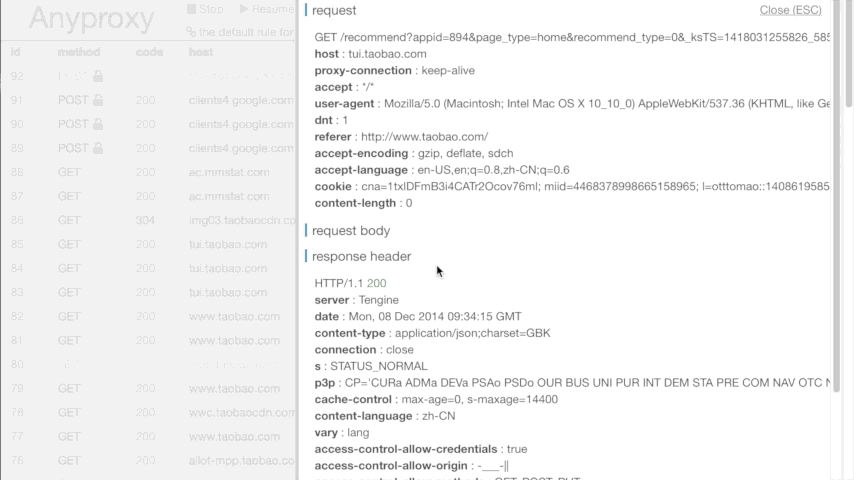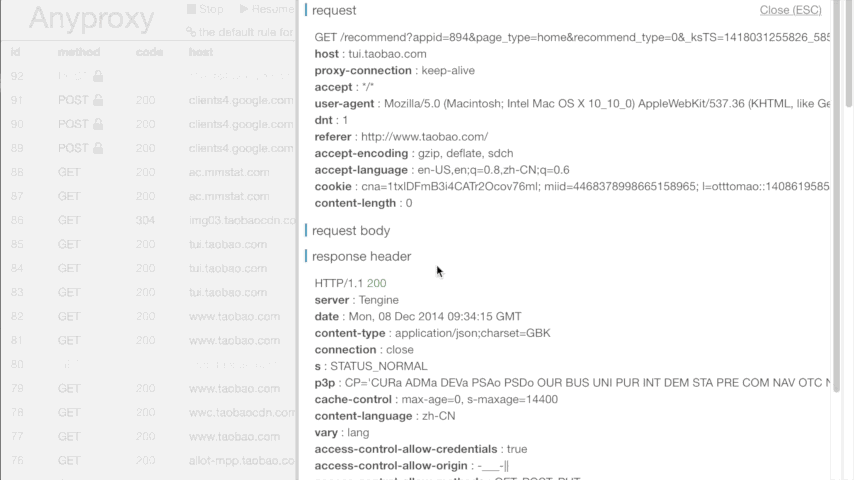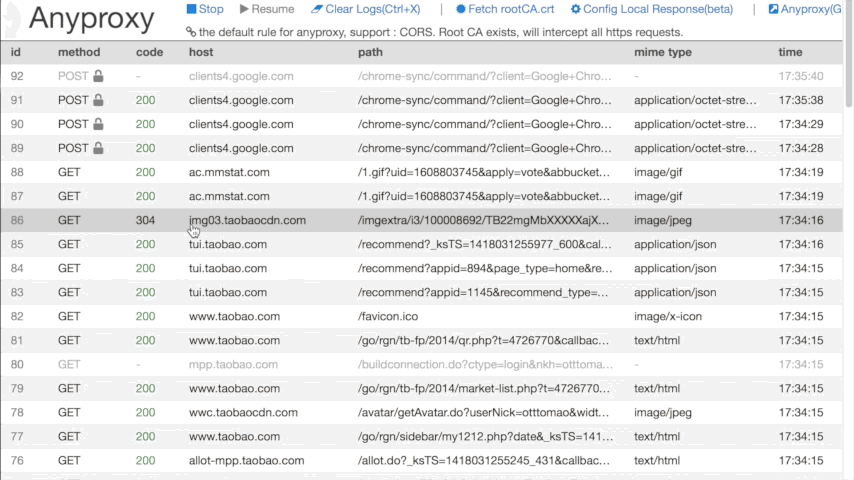
еңЁиҝҷиҝҮзЁӢдёӯпјҢиӢҘдҪ жңүд»»дҪ•з–‘й—®пјҢеҸҜи§ҒжңҖдёҠйқўж„ҹи°ўзҡ„йӮЈзҜҮж–Үз« гҖӮ
жҺҘдёӢжқҘжӨҚе…Ҙи„ҡжң¬пјҢжӨҚе…Ҙи„ҡжң¬жҲ‘们жҳҜйҖҡиҝҮдҝ®ж”№й…ҚзҪ®ж–Ү件е®һзҺ°зҡ„гҖӮ
й…ҚзҪ®ж–Ү件ең°еқҖпјҡ
MacеңЁ /usr/local/lib/node_modules/anyproxy/lib/.
WindowsжҚ®иҜҙеңЁ APPdata\RoamingпјҲиӢҘдёҚжҳҜзҡ„иҜқиҜ·жүҫдёҖдёӢWindows npmй»ҳи®Өе…ЁеұҖе®үиЈ…зҡ„дҪҚзҪ®пјүгҖӮ
жҲ‘们еҸӘйңҖиҰҒдҝ®ж”№rule_default.jsеҶ…зҡ„replaceServerResDataAsync:function(req,res,serverResData,callback) еҮҪж•°
з”ұдәҺйӮЈзҜҮж–Үз« йҮҢжҳҜеӨ§еһӢзҲ¬иҷ«д»Јз ҒпјҢжҲ‘еҸӘйңҖиҰҒзҲ¬еҸ–дёӘдәәе…¬дј—еҸ·зҡ„пјҢеӣ жӯӨеҜ№е…¶иҝӣиЎҢдәҶдҝ®ж”№пјҢ并иҪ¬жҚўжҲҗдәҶjsд»Јз ҒгҖӮд»Јз Ғе°ұе…ҲдёҚиҙҙдәҶпјҢжңүе…ҙи¶ЈеҸҜд»Ҙи§ҒGitHubеә“пјҡhttps://github.com/Ckend/GzhToBlogпјҢе–ңж¬ўиҜ·starдёҖдёӢпјҢи®©жҲ‘жңүеҠЁеҠӣжӣҙж–°гҖӮ
жӯҘйӘӨеҰӮдёӢпјҡ
1.еҗҜеҠЁAnyproxy, жү“ејҖе…¬дј—еҸ·зҡ„еҺҶеҸІж¶ҲжҒҜеҲ—иЎЁпјҢеңЁ localhost:8002 и§ӮеҜҹAnyproxyжҺҘ收еҲ°зҡ„дҝЎжҒҜдёӯе“ӘдёҖдёӘжҳҜж¶ҲжҒҜеҲ—иЎЁзҡ„гҖӮжңҖеҗҺеҸ‘зҺ°еёҰжңүprofile-extзҡ„й“ҫжҺҘзҡ„жҳҜж¶ҲжҒҜеҲ—иЎЁзӣёе…ізҡ„гҖӮ
жҸ’еҸҘйўҳеӨ–иҜқпјҢprofile-extйҮҢзҡ„-е…¶е®һжҳҜ_жүҚеҜ№пјҢдҪҶжҳҜе…¬дј—еҸ·жҺЁйҖҒжЈҖжөӢж–Үз« йҮҢжҳҜеҗҰеј•з”ЁдәҶеҲ«зҡ„е…¬дј—еҸ·зҡ„ж–Үз« з«ҹ然е°ұжҳҜйҖҡиҝҮиҝҷдёӘе…ій”®иҜҚпјҢжғҠдәҶдёӘе‘ҶпјҢзҹҘйҒ“жҲ‘жөӘиҙ№дәҶеҚҠе°Ҹж—¶жқҘжүҫиҝҷзҜҮж–Үз« зҡ„й”ҷпјҢжңҖеҗҺеҸ‘зҺ°жҳҜиҝҷйҮҢзҡ„иЎЁжғ…жҳҜжҖҺж ·зҡ„еҗ—гҖӮ
2.дәҺжҳҜеҜ№еёҰжңүprofile-extзҡ„й“ҫжҺҘзҡ„еӣһеӨҚпјҲжңүдёӨз§ҚпјҢдёҖз§ҚжҳҜйЎөйқўж јејҸпјҢдёҖз§ҚжҳҜjson(第дәҢйЎөд»ҘеҗҺе°ұжҳҜjson)пјүиҝӣиЎҢжӨҚе…Ҙи„ҡжң¬гҖӮе°Ҷе…¶иҝ”еӣһзҡ„жүҖжңүдҝЎжҒҜеӯҳе…Ҙд№ӢеүҚжүҖеҲӣе»әзҡ„MongoDBж•°жҚ®еә“blogйҮҢзҡ„CollectionsдёӯпјҲи§ҒGitHubйҮҢrule_default.jsж–Ү件зҡ„getToMongodb()еҮҪж•°пјҢе»әи®®е…ҲиҝһжҺҘжң¬ең°зҡ„MongoDBпјҢжҲҗеҠҹеҗҺеҶҚиҝһжҺҘжңҚеҠЎеҷЁзҡ„пјүгҖӮ
3.еңЁжЁЎжӢҹеҷЁдёҠеҫҖдёӢжӢ–пјҢдҝқеӯҳжүҖжңүзҡ„жҺЁйҖҒгҖӮ
4.ж–°е»әдёҖдёӘjsж–Ү件пјҢиҙҹиҙЈйҖҡиҝҮеүҚйқўжүҖзҲ¬еҸ–еҲ°зҡ„articlesйҮҢзҡ„ж–Үз« й“ҫжҺҘзҲ¬еҸ–ж–Үз« е№¶дҝқеӯҳеҲ°ж•°жҚ®еә“дёӯ(GitHubйҮҢеҜ№еә”crawl.js)гҖӮ
5.еӨ§еҠҹе‘ҠжҲҗпјҢжҺҘдёӢжқҘе°ұе·®еүҚз«ҜжёІжҹ“ж•°жҚ®еұ•зҺ°еҚҡе®ўдәҶгҖӮ
дёҠиҝ°еҶ…е®№е°ұжҳҜеҹәдәҺAnyproxyrhrh дҪҝз”Ё"дёӯй—ҙдәәж”»еҮ»"зҲ¬еҸ–е…¬дј—еҸ·жҺЁйҖҒпјҢдҪ 们еӯҰеҲ°зҹҘиҜҶжҲ–жҠҖиғҪдәҶеҗ—пјҹеҰӮжһңиҝҳжғіеӯҰеҲ°жӣҙеӨҡжҠҖиғҪжҲ–иҖ…дё°еҜҢиҮӘе·ұзҡ„зҹҘиҜҶеӮЁеӨҮпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ





