这篇文章主要讲解了“机器学习的K-NN算法是怎么工作的”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“机器学习的K-NN算法是怎么工作的”吧!
K最近邻(k-Nearest Neighbor,KNN)是数据挖掘分类技术中最简单的方法之一,是机器学习中唯一一个不需要训练过程的算法。K最近邻,即每个样本都可以用它最近的k个邻居代表。核心思想是如果两个样本的特征足够相似,它们就有更高的概率属于同一个类别,并具有这个类别上样本的特性。比较通俗的说法就是“近朱者赤近墨者黑”。
优点是简单,易于理解,易于实现,无需估计参数,无需训练;适合对稀有事件进行分类;特别适合于多分类问题, kNN比SVM的表现要好。
缺点是算法复杂度高,每一个待分类的样本都要计算它到全体已知样本的距离,效率较低;预测结果不具有可解释性,无法给出像决策树那样的规则;
kNN算法的过程如下:
1、选择一种距离计算方式, 通过数据所有的特征计算新数据与已知类别数据集中数据点的距离;
2、按照距离递增次序进行排序, 选取与当前距离最小的 k 个点;
3、对于离散分类, 返回 k 个点出现频率最多的类别作为预测分类; 对于回归, 返回 k 个点的加权值作为预测值。
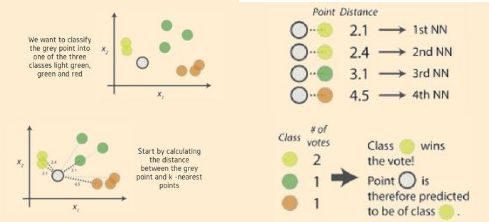
如上图中,对灰色圆点进行分类,划分其属于绿、黄、红何种类型。首先需要计算灰点和近邻电之间的距离,确定其k近邻点,使用周边数量最多的最近邻点类标签确定对象类标签,本例中,灰色圆点被划分为黄色类别。
距离越近,表示越相似。距离的选择有很多,通常情况下,对于连续变量, 选取欧氏距离作为距离度量; 对于文本分类这种非连续变量, 选取汉明距离来作为度量. 通常如果运用一些特殊的算法来作为计算度量, 可以显著提高 K 近邻算法的分类精度,如运用大边缘最近邻法或者近邻成分分析法。
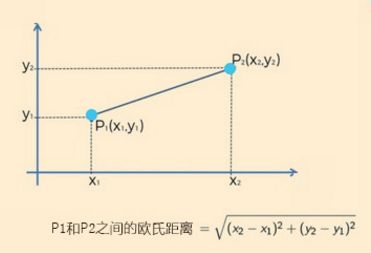
欧氏距离
切比雪夫距离
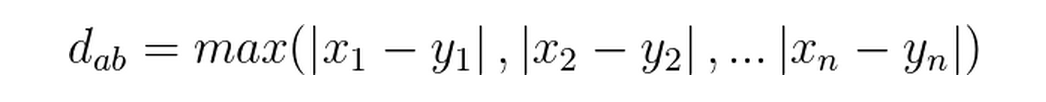
马氏距离
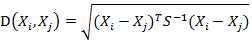
夹角余弦距离
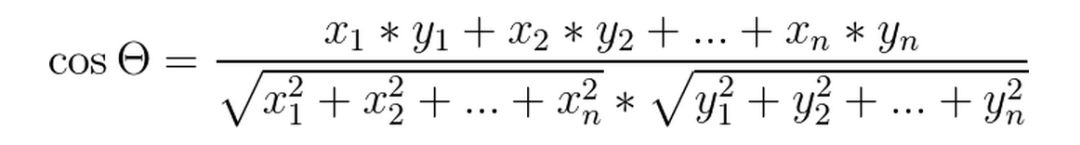
切比雪夫距离
曼哈顿(Manhattan)距离
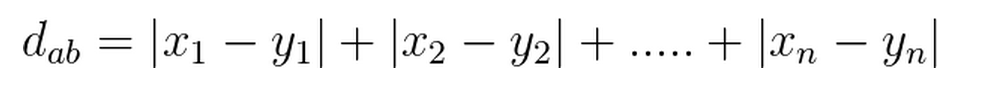
感谢各位的阅读,以上就是“机器学习的K-NN算法是怎么工作的”的内容了,经过本文的学习后,相信大家对机器学习的K-NN算法是怎么工作的这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





