这篇文章给大家介绍如何进行条件logistic回归分析,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
条件logistic回归分析
在流行病的病例—对照研究中,为控制一些重要的混杂因素,常把病例组和对照组按照年龄、性别等因素进行配对,该法能很好地控制混杂因素对研究结果的影响。
一般地,病例组与对照组的匹配形式为1:n (n<=3),常见的为 1:1 。
案例分析
某北方城市研究喉癌发病的危险因素,用1:2 配对的病例-对照研究方法进行了调查。现选取了6个可能的危险因素并截取了25对数据。
数据赋值情况
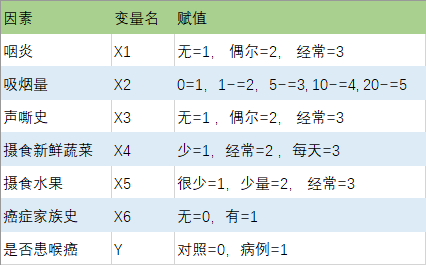
数据视图
问题分析
①数据类型:因变量Y为二分类变量,6个自变量均为分类变量。
②病例:对照 为1:2
③分析方法:SPSS中无专门处理条件logistic回归分析的菜单操作,但很多学者推荐采用cox回归分析(后期我们将介绍SAS的处理方法)。


【1】生成新变量TIME,
转换——计算变量——{TIME = 2 - y },这是常用的一种方法,使得病例组生存时间为1,对照组生存时间为2 。
【2】进行 { cox 回归分析 }
详细过程 ▶▶▶ Cox回归分析
【3】分析——生存函数——cox回归
【4】TIME选入“时间”,y选入“状态”——定义事件的单值为1,计算方法选用“向前 Wald”,需将配对号 i 选入 “层”
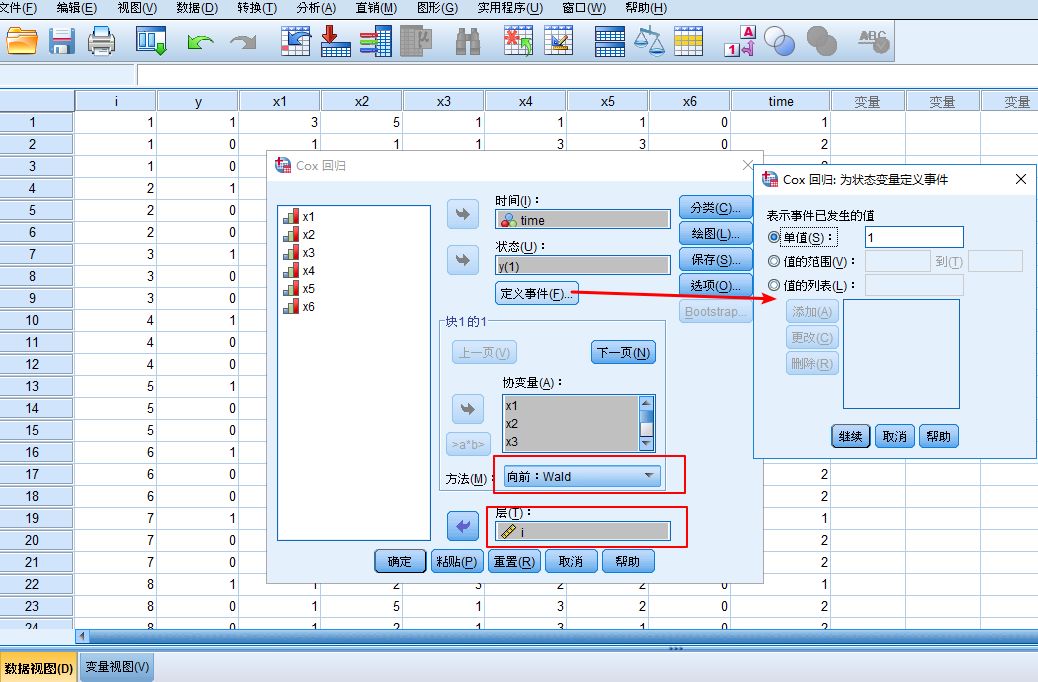
详细解析可参考{ Cox回归分析 }
①模型系数的似然比检验
-2lnL = 16.112 , 模型似然比检验卡方值为28.397,P<0.001,模型有统计学意义,可以认为所建立的logistic回归方程有意义。

②条件logistic回归分析的参数估计等

步骤4:
以检验水准 α = 0.05 , 自变量 X2、X3、X4、X6最终被选入模型,且X2、X3、X6为危险因素,X4为保护因素。X6的显著性与检验水准很接近,实际研究中可以适当放宽要求或根据临床经验是否纳入。以自变量X6为例 ,P=0.052,,OR=37.793,即有癌症家族史是无癌症家族史患喉癌风险的37.793倍。
关于如何进行条件logistic回归分析就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





