这篇文章主要为大家展示了“如何在Perl中使用正则表达式”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“如何在Perl中使用正则表达式”这篇文章吧。
⑴匹配模式
我们已知在Perl中正则表达式被称为模式,这种模式(也即正则表达式)可以放在由成对符号(例如()、<>、{}等)或者一对不成对的符号(例如//、!!、^^等)组成的界定符内,并在界定符前用小写字母指定模式的种类。当然我们不希望界定符和正则表达式的符号有所冲突(如果实在有冲突可以使用反斜杠转义),事实上最常用的界定符为双斜杠//。在Perl中有很多处理模式,其中最简单的为匹配模式m//,或者也可以理解为查找模式。由于正则表达式本身就有匹配的含义,以双斜杠作为定界符时m可以省略。其他处理模式详见下一小节。
$_ = "yabba dabba doo";if (/y(.)(.)\2\1/) { print "It matched!\n";}
运行结果如下所示:

$_ = "yabba dabba doo";if ($_ =~ /y(.)(.)\2\1/) { print "It matched!\n";}
其中=~是表示内容匹配的绑定操作符,其返回值为表示是否成功匹配的布尔值,基于上面的写法我们可以根据实际需要随意改变要匹配的变量名称。
⑵模式修饰符
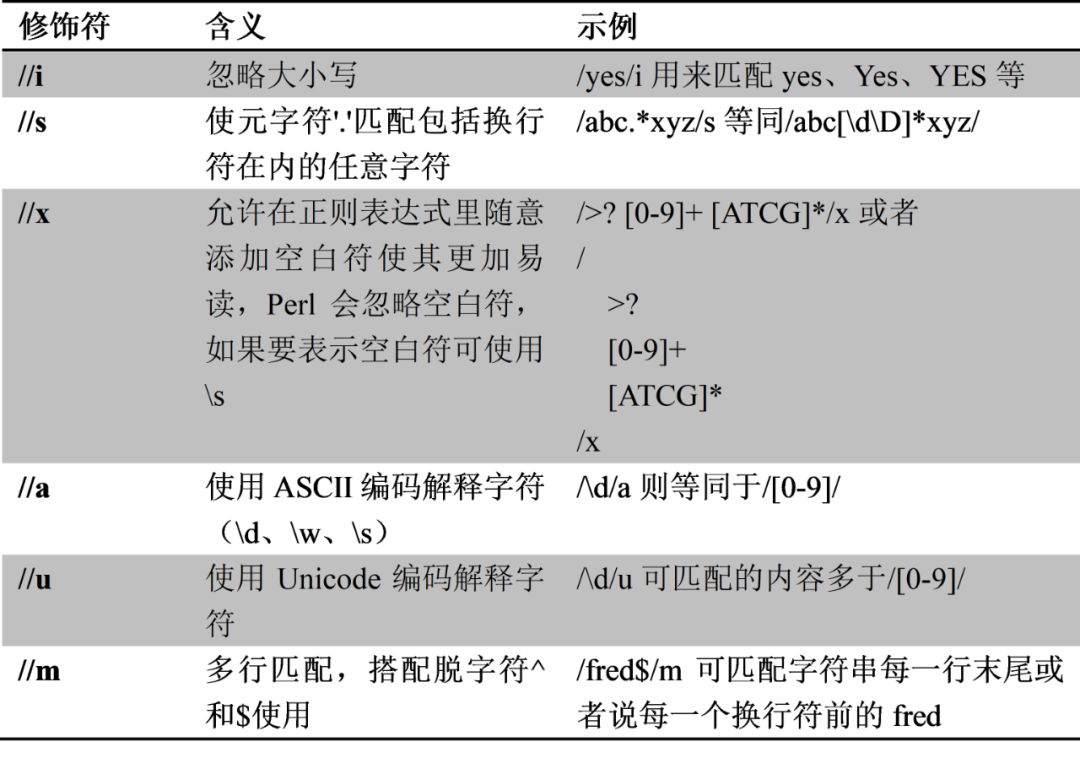
/abc.*xyz/is #忽略大小写并使点号匹配任意字符
⑶锚位
$_ = "This is the wilma linebarney is on another linebut this ends in fred";if (/^barney/m) { print "It matched!\n";}
/\Abarney/ #匹配字符串绝对开头位置的barney/fred\z/ #匹配字符串绝对末尾位置的fred/fred\Z/ #匹配行尾也即换行符前的fred/\A\s*\Z/ #匹配一个空行
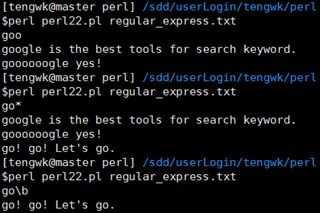
/\bfred\b/ #会匹配fred、fred's但是不会匹配afred、fred_s
此外\B则会锚定非单词边界,如下所示
/\bfred\B/ #会匹配fred_s 但是不会匹配fred、fred's、afred
⑷变量内插
my $what = <STDIN>;chomp $what;while (<>) { if (/\A($what)/) { print "$_"; }}
⑸捕获变量
$_ = "Hello there, neighbor";if (/(\S+).*,\s(\w+)/) { print "What I said is:\n$1 $2!\n";}

这些捕获变量在下一次正则表达式成功匹配之前都是有效的,如果某次匹配失败,那么捕获变量里储存的仍是上一次成功匹配时的数据,这里的匹配成功指的是整个模式的匹配而非捕获组的匹配,这也是模式匹配以及捕获变量的使用一般在if和while等布尔值控制结构里面的原因。如果想永远使用某次捕获的内容,则可以使用捕获变量为自定义标量变量赋值。
$_ = "Hello there, neighbor";if (/(?<name1>\S+).*,\s(?<name2>\w+)/) { print "What I said is:\n$+{name1} $+{name2}!\n";}
以上是“如何在Perl中使用正则表达式”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





