spark streaming窗口及聚合操作后怎么管理offset,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
spark streaming经过窗口的集合操作之后,再去管理offset呢?
对于spark streaming来说窗口操作之后,是无法管理offset的,因为offset的存储于HasOffsetRanges,只有kafkaRDD继承了该特质,经过转化的其他RDD都不支持了。所以无法通过其他RDD转化为HasOffsetRanges来获取offset,以便自己管理。
kafkaRDD的继承关系如下:
private[spark] class KafkaRDD[K, V]( sc: SparkContext, val kafkaParams: ju.Map[String, Object], val offsetRanges: Array[OffsetRange], val preferredHosts: ju.Map[TopicPartition, String], useConsumerCache: Boolean) extends RDD[ConsumerRecord[K, V]](sc, Nil) with Logging with HasOffsetRanges {
HasOffsetRanges只有kafkaRDD继承了他,所以假如我们对KafkaRDD进行了转化之后就无法再获取offset了。
HasOffsetRanges就是一个OffsetRange的数组:
trait HasOffsetRanges { def offsetRanges: Array[OffsetRange]}
再看一下,OffsetRange的实现:
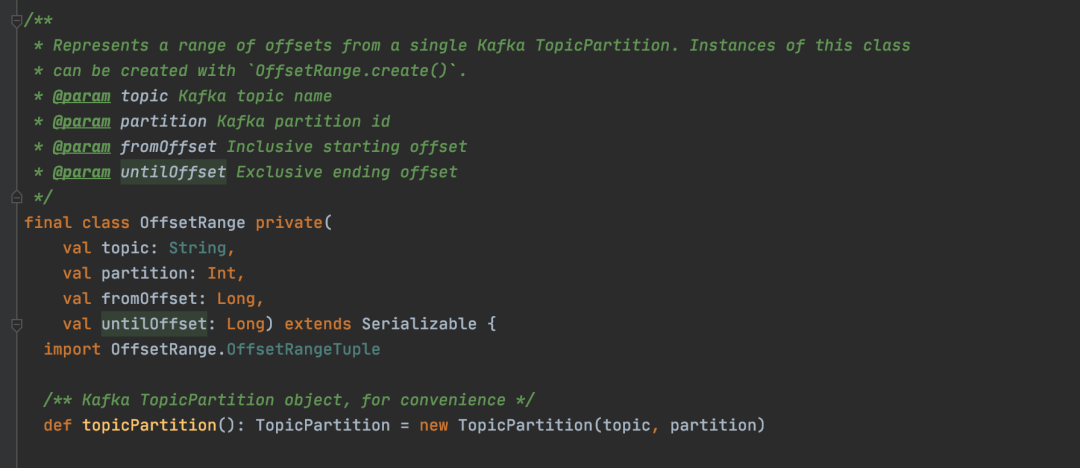
窗口操作会包含若干批次的RDD数据,窗口操作也往往带有聚合操作,所以KafkaRDD肯定会被转化为其他类型的RDD的,那么之后就无法转化为hasoffsetranges了,也是管理offset变得很麻烦的。
实际上,无论是窗口是否有重叠和包含聚合,其实我们只关心本次处理窗口的kafkardds 的offset范围[fromOffset, toOffset),由于fromOffset是上次提交成功的,那么本次处理完只需要提交的toOffset即可,即使处理失败也可以从fromOffset开始重新处理。也就实现了数据的最少一次处理,假如能与结果一起管理,也可以实现仅一次处理。那么提交offset我们只需要提交最近的那个批次的kafkaRDD的toOffset即可。
那么如何获取最新的kafkaRDD的toOffset呢?
其实,我们只需要在driver端记录kafkardd转化的hasoffsetrange存储的offset即可。
回顾一下,对于spark 来说代码执行位置分为driver和executor,我们希望再driver端获取到offset,等处理完结果后,再提交offset到kafka或者直接与结果一起管理offset。
那么窗口操作之前获取offset方法是什么呢?
就是利用transform操作,完成下面的步骤:
var A:mutable.HashMap[String,Array[OffsetRange]] = new mutable.HashMap()val offsetRanges = r.asInstanceOf[HasOffsetRanges].offsetRangesA += ("rdd1"->offsetRanges)
上述步骤就完成了,只记录最新kafkardd的hasoffsetranges里存储的offset功能。
总结一下:driver端通过使用transform获取到offset信息,然后在输出操作foreachrdd里面完成offset的提交操作。
package bigdata.spark.SparkStreaming.kafka010import java.util.Propertiesimport org.apache.kafka.clients.consumer.{Consumer, ConsumerRecord, KafkaConsumer}import org.apache.kafka.common.TopicPartitionimport org.apache.kafka.common.serialization.StringDeserializerimport org.apache.spark.rdd.RDDimport org.apache.spark.streaming.kafka010._import org.apache.spark.streaming.{Seconds, StreamingContext}import org.apache.spark.{SparkConf, TaskContext}import scala.collection.JavaConverters._import scala.collection.mutableobject kafka010NamedRDD {def main(args: Array[String]) {// 创建一个批处理时间是2s的context 要增加环境变量val sparkConf = new SparkConf().setAppName("DirectKafkaWordCount").setMaster("local[*]")val ssc = new StreamingContext(sparkConf, Seconds(5))ssc.checkpoint("/opt/checkpoint")// 使用broker和topic创建DirectStreamval topicsSet = "test".split(",").toSetval kafkaParams = Map[String, Object]("bootstrap.servers" -> "mt-mdh.local:9093","key.deserializer"->classOf[StringDeserializer],"value.deserializer"-> classOf[StringDeserializer],"group.id"->"test4","auto.offset.reset" -> "latest","enable.auto.commit"->(false: java.lang.Boolean))// 没有接口提供 offsetval messages = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams,getLastOffsets(kafkaParams ,topicsSet)))//var A:mutable.HashMap[String,Array[OffsetRange]] = new mutable.HashMap()val trans = messages.transform(r =>{val offsetRanges = r.asInstanceOf[HasOffsetRanges].offsetRangesA += ("rdd1"->offsetRanges)r}).countByWindow(Seconds(10), Seconds(5))trans.foreachRDD(rdd=>{if(!rdd.isEmpty()){val offsetRanges = A.get("rdd1").get//.asInstanceOf[HasOffsetRanges].offsetRangesrdd.foreachPartition { iter =>val o: OffsetRange = offsetRanges(TaskContext.get.partitionId)println(s"${o.topic} ${o.partition} ${o.fromOffset} ${o.untilOffset}")}println(rdd.count())println(offsetRanges)// 手动提交offset ,前提是禁止自动提交messages.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)}// A.-("rdd1")})// 启动流ssc.start()ssc.awaitTermination()}def getLastOffsets(kafkaParams : Map[String, Object],topics:Set[String]): Map[TopicPartition, Long] ={val props = new Properties()props.putAll(kafkaParams.asJava)val consumer = new KafkaConsumer[String, String](props)consumer.subscribe(topics.asJavaCollection)paranoidPoll(consumer)val map = consumer.assignment().asScala.map { tp =>println(tp+"---" +consumer.position(tp))tp -> (consumer.position(tp))}.toMapprintln(map)consumer.close()map}def paranoidPoll(c: Consumer[String, String]): Unit = {val msgs = c.poll(0)if (!msgs.isEmpty) {// position should be minimum offset per topicpartitionmsgs.asScala.foldLeft(Map[TopicPartition, Long]()) { (acc, m) =>val tp = new TopicPartition(m.topic, m.partition)val off = acc.get(tp).map(o => Math.min(o, m.offset)).getOrElse(m.offset)acc + (tp -> off)}.foreach { case (tp, off) =>c.seek(tp, off)}}}}
关于spark streaming窗口及聚合操作后怎么管理offset问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





