这篇文章将为大家详细讲解有关什么是Cloudera虚拟私有集群和SDX,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
1概述
虚拟私有集群(Virtual Private Cluster,VPC)使用Cloudera共享数据体验(Shared Data Experience,SDX)来简化本地和基于云的应用程序的部署,并使运行在不同集群中的工作负载能够安全,灵活的共享数据。这个架构为在应用程序之间部署工作负载和共享数据带来了很多优势,包括共享元数据,统一安全,一致的数据治理和数据生命周期管理。
在传统的CDH部署中,一个集群通常包含存储节点,计算节点以及其它服务如元数据和安全服务。这种传统架构有很多优点,比如Impala和YARN可以访问相同的数据源如HDFS或Hive。
借助VPC和SDX框架,CDH6.2提供了一种新类型集群,称为计算集群(Compute cluster)。计算集群运行Impala,Hive Execution Service,Spark或YARN等计算服务,然后配置这些集群都统一访问同一个常规CDH集群(Regular CDH cluster),称为基础集群(Base cluster)。使用这个架构可以实现计算和存储的分离,从而提高总的资源利用率。
2存储和计算分离的优点
存储和计算分离架构可以为CDH部署带来很多优势:
1.为部署计算和存储资源提供更多选择
a)你可以有选择的将资源部署到本地服务器,容器,虚拟机或云中,具体看工作负载适合哪个部署环境。配置Compute集群时,你可以配置更适合计算类工作负载的硬件,而Base集群则可以使用存储较大的硬件。Cloudera建议每个集群使用相似的硬件。
b)可以优化软件资源以最好地使用计算和存储资源。
2.临时集群
在云基础架构上部署集群时,存储和计算分离可以允许你暂时关闭计算集群以避免不必要的开销 - 同时数据依旧保存给其它的应用程序使用。
3.隔离工作负载
a)Compute集群可以解决用户访问时的资源冲突问题。可以对需要长时间运行的工作负载或者非常吃资源的工作负载进行隔离,将它们部署到专有的Compute集群中运行,从而不影响其它工作负载。
b)资源可以按集群进行分组,从而允许IT团队对使用使用集群的团队基于资源进行成本核算。
3架构
Compute集群配置有计算资源,例如YARN,Spark,Hive Execution或Impala。在这些集群上运行的工作负载通过连接到Base集群的数据上下文(Data Context)来访问数据。数据上下文是连接到Base集群的连接器。数据上下文定义了在Base集群中部署的访问数据所需的数据,元数据和安全服务。无论是Compute集群还是Base集群都由同一个Cloudera Manager管理。Base集群必须部署HDFS服务,同时也可以包含任何其他的CDH服务 - 但只能使用数据上下文共享HDFS,Hive,Sentry,Amazon S3和Microsoft ADLS。
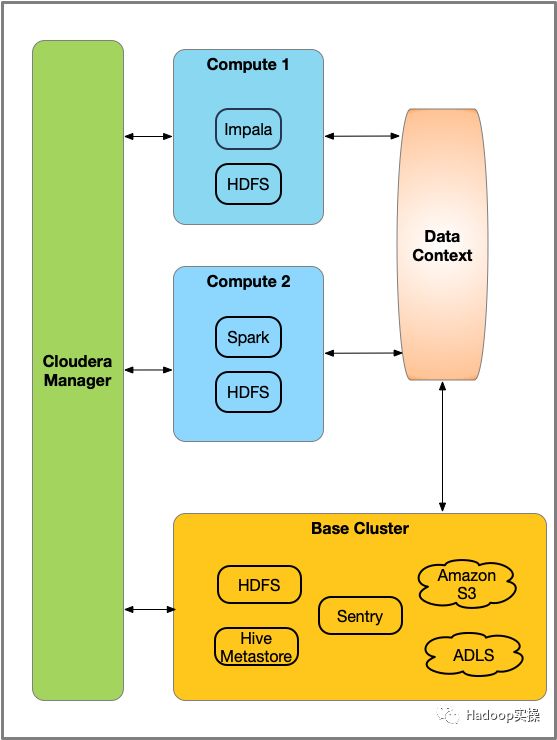
Compute集群需要HDFS服务来保存多阶段MapReduce作业中使用的临时文件。另外,根据需要部署以下服务:
Hive Execution Service(此服务仅提供HiveServer2角色)
Hue
Impala
Spark2
Oozie(Hue依赖该服务)
YARN
HDFS(必须)
VPC的功能是常规集群中可用功能的子集,您可以使用的CDH版本是有限的。
4性能权衡
吞吐
因为访问数据需要通过集群与集群之间的网络,因此该架构不适合需要扫描大量数据的工作负载。这些类型的工作负载在常规集群上会运行的更好,就是存储和计算不分离,诸如像Impala的短回路(short-circuit)读取可以带来更好的性能。
临时集群
当Compute集群因为不需要时被关闭或暂停后,收集历史数据的服务不会在Compute集群离线时收集数据,同时用户也无法访问历史记录。这会影响Spark History Server和YARN JobHistory Server等服务。当Compute集群重新启动后,你才可以访问以前的历史记录。
Compute集群中的数据治理和元数据
在一个Base集群和多个Compute集群的环境中,Navigator的设计目标是为Base集群的数据治理和元数据提供服务。它不会从临时的Compute集群中提取元数据和审计事件。配置集群时,如果用户操作是针对Base集群上的服务和数据运行,并且使用受控的服务账号在Compute集群上进行操作,Navigator会依旧跟踪元数据和审计事件。
因为不会收集Compute集群上运行服务的审计事件,所以如果你需要收集用户的审计事件,请确保Compute集群上运行的工作负载是服务用户执行的工作负载,并严格控制对服务用户帐户的访问。
对于在Compute集群上运行的服务,不会收集任何元数据。要确保系统收集你的环境中的资产和操作元数据,请在数据上下文中包含服务。
关于什么是Cloudera虚拟私有集群和SDX就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





