这篇文章主要为大家展示了“EfficientNet-lite是什么意思”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“EfficientNet-lite是什么意思”这篇文章吧。
3.17日谷歌在 GitHub 与 TFHub 上同步发布了 EfficientNet-lite,EfficientNet的端侧版本,运行在 TensorFlow Lite 上,针对端侧 CPU、GPU 和 EdgeTPU 做了优化。EfficientNet-lite提供五个不同版本(EfficientNet-lite0~4),让用户能够根据自己的应用场景和资源情况在延迟、参数量和精度之间做选择。
EfficientNet-Lite4 是计算量最大的版本,在 ImageNet上的top-1准确率达到了80.4%,同时能够以30ms/image的速度运行在 Pixel 4 的 CPU 上。EfficientNet-lite 具体的精度和延时、参数的关系如下图所示。可见其已经把MobileNet V2,ResNet 50,Inception v4等模型远远甩在背后。
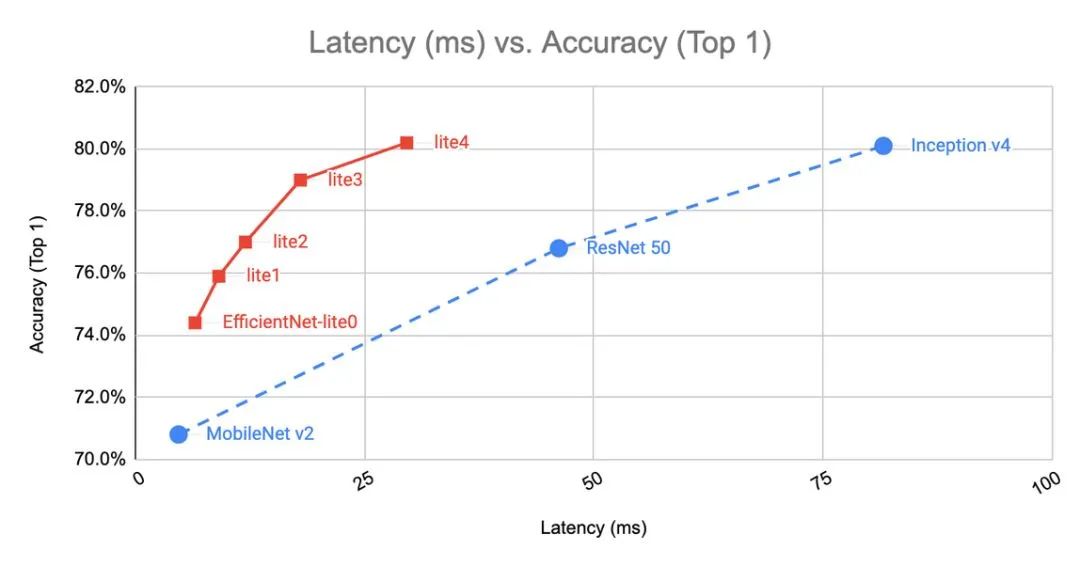
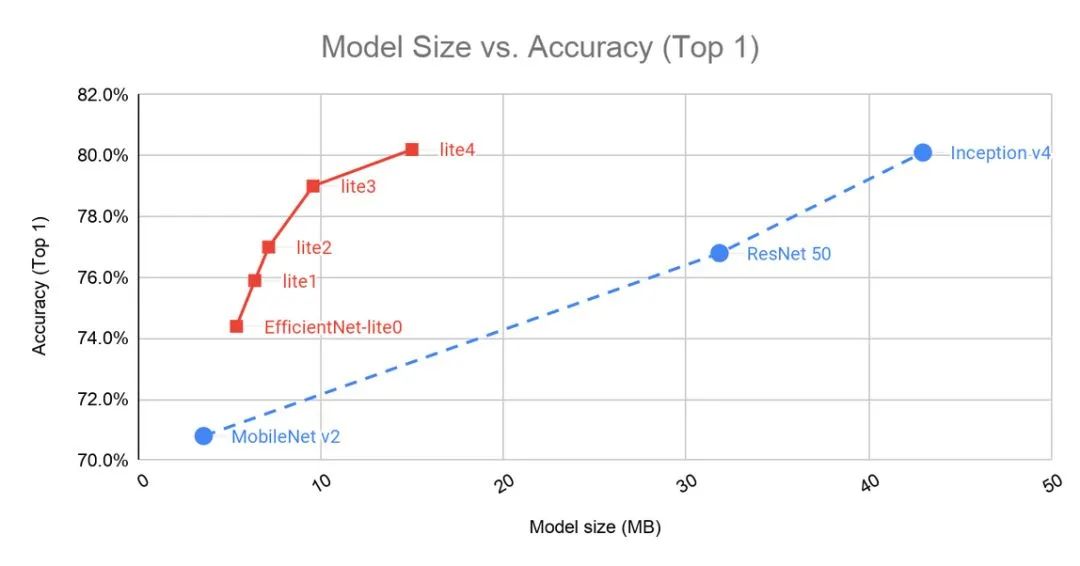
EfficientNet-lite进行了一系列的优化:
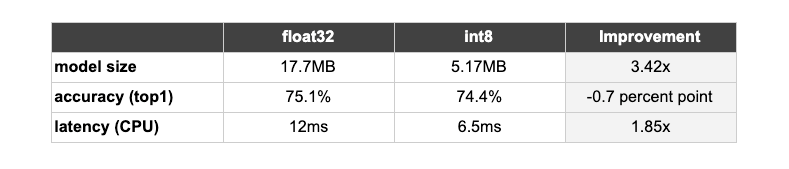
量化。定点运算的速度要比浮点运算快很多,在移动设备算力有限的场景下,量化必不可少。但量化使用了定点数,表示范围相对于浮点数小很多,必然存在精度的损失。借助 TensorFlow Lite 中提供的训练后量化流程来对模型进行量化处理,尽可能地降低了对准确率的影响。通过量化,模型大小减少为1/4,推理速度提升近2倍。
EfficientNet-lite0 浮点模型float32与int8量化版本在模型尺寸、精度及时延的对比:
结构和算子优化。去除 squeeze-and-excitation 结构,因为目前在端侧设备上支持欠佳。
使用 Relu6替代swish 激活函数,swish激活复杂度高,并且对量化有不利影响。
放缩模型尺寸时固定 stem 与 head 模块,减少放缩后模型的大小与计算量。
对于用户个性化的数据集,建议使用 TensorFlow Lite Model Maker,在已有 TensorFlow 模型上使用迁移学习。TensorFlow Lite Model Maker 支持很多模型结构,包括 MobileNetV2 和所有5个版本的 EfficientNet-Lite。以下为使用 EfficientNet-lite0 进行鲜花分类的代码,只要五行。
# Load your custom dataset
data = ImageClassifierDataLoader.from_folder(flower_path)
train_data, test_data = data.split(0.9)# Customize the pre-trained TensorFlow model
model = image_classifier.create(train_data, model_spec=efficienetnet_lite0_spec)# Evaluate the model
loss, accuracy = model.evaluate(test_data)# Export as TensorFlow Lite model.
model.export('image_classifier.tflite', 'image_labels.txt')
通过改变 model_spec 参数,可以尝试不同的模型。模型建立好以后,可以将其构建为移动端 app,把自己个性化的模型存放在 asset 文件夹。
以上是“EfficientNet-lite是什么意思”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





