HDFS组件结构图解说:
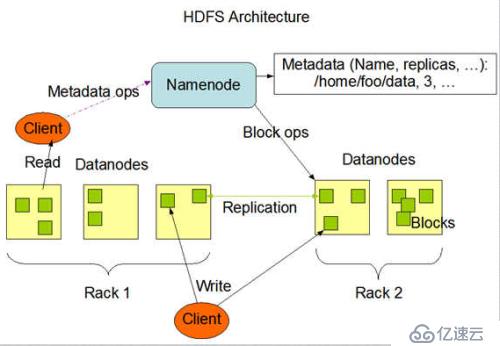
1、如图所示中,NameNode充当master角色,职责包括:管理文档系统的命名空间(namespace);调节客户端访问到需要的文件(存储在DateNode中的文件)
2、DataNodes充当slaves角色,通常情况下,一台机器只部署一个Datenode,用来存储MapReduce程序需要的数据
3、Namenode会定期从DataNodes那里收到Heartbeat和Blockreport反馈
4、Heartbeat反馈用来确保DataNode没有出现功能异常;
5、Blockreport包含DataNode所存储的Block集合
二、HDFS设计原则
1、文件以块(block)方式存储
2、每个块带下远比多数文件系统来的大(预设64M)
3、通过副本机制提高可靠度和读取吞吐量
4、每个区块至少分到三台DataNode上(一般,对namenode进行raid1配置,对datanode进行raid5配置)
5、单一 master (NameNode)来协调存储元数据(metadata)
6、客户端对文件没有缓存机制 (No data caching)
三、NameNode(NN)
NameNode主要功能提供名称查询服务,它是一个jetty服务器(一个开源的servlet容器,嵌入式的web服务器)
NameNode保存metadate信息包括
文件owership和permissions
文件包含哪些块
Block保存在哪个DataNode(由DataNode启动时上报)
1、NameNode的metadate信息在启动后会加载到内存
2、metadata存储到磁盘文件名为”fsp_w_picpath”
Block的位置信息不会保存到fsp_w_picpath
四.DataNode(DN)
保存Block
启动DN线程的时候会向NN汇报block信息
hadoop fs -cmd
cmd :为具体的操作,基本上于UNIX的命令相同
args:参数
hdfs资源URL格式:scheme://bigdata/path
scheme:协议名,file或hdfs
bigdata:namenode主机名
path:路径
eg:hdfs://localhost:9000/user/chunk/test.txt
假设已经在core-site.xml设置了fs.default.name=hdfs://localhost:9000,
则仅使用/user/chunk/test.txt即可
hdfs命令示例:存放的数据以文件的形式存储,使用绝对路径来区分每个资源,在创建目录来存储资源时候要加/
#创建目录
hadoop fs -mkidr /myFirstDir
#查看创建的目录
hadoop fs -ls /myFirstDir #返回为空,目前还没存放数据
#对当前创建目录存放文件
hadoop fs -put /etc/shadow /myFirstDir
#查看目录下的文件
hadoop fs -ls /myFirstDir
#复制文件到指定的位置
hadoop fs -get /hadoop目下的文件 /本地文件路径
hadoop fs -get /myFirstDir/shadow /home/#下载shadow到/home目录下
#新建一个空文件
hadoop fs -touchz /myFirstDir/newFile.txt
#将hadoop上某个文件重命名
hadoop fs -mv /myFirstDir/newFile.txt /myFirstDir/bigdata.txt
#将hadoop指定目录下所有内容保存为一个文件,同时down至本地
hadoop dfs -getmerge /myFirstDir/bigdata.txt /home/a
#查看文件里的内容
hadoop fs -cat /myFirstDir/shadow
#查看最后1000字节数据
hadoop fs -tail /myFirsDir/shadow
#删除文件\目录
hadoop fs -rm -R /myFirstDir/shadow
hadoop fs -rm -R /myFirstDir/Secondary
#查看HDFS下的文件
hadoop fs -ls /
#查看集群数据的信息,登陆master节点查看
http://192.168.1.114:50070
管理与更新
#查看HDFS的基本统计信息
hadoop dfsadmin -report
#进出安全模式
hadoop dfsadmin -safemode enter
hadoop dfsadmin -safemode leave
#节点添加
添加一个新的DataNode节点,先在新加节点上安装好Hadoop,
要和NameNode使用相同的配置(可以直接从NameNode复制),修改$HADOOP_HOME/conf/master文件,加入NameNode主机名。
然后在NameNode节点上修改$HADOOP_HOME/conf/slaves文件,加入新节点名,再建立新加节点无密码的SSH连接,运行启动命令为:
/bin/start-all.sh
#负载均衡
HDFS的数据在各个DataNode中的分布可能很不均匀,尤其是在DataNode节点出现故障或新增DataNode节点时。
新增数据块时NameNode对DataNode节点的选择策略也有可能导致数据块分布不均匀。
用户可以使用命令重新平衡DataNode上的数据块的分布:
start-balancer.sh
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





