1.hadoop介绍
Hadoop是Apache软件基金会旗下的一个开源分布式计算平台。以Hadoop分布式文件系统(HDFS,Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核心的Hadoop为用户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两大类角色:Master和Salve。一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件系统的访问操作;集群中的DataNode管理存储的数据。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前的失败任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
从上面的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核心。HDFS在集群上实现分布式文件系统,MapReduce在集群上实现了分布式计算和任务处理。HDFS在MapReduce任务处理过程中提供了文件操作和存储等支持,MapReduce在HDFS的基础上实现了任务的分发、跟踪、执行等工作,并收集结果,二者相互作用,完成了Hadoop分布式集群的主要任务。
1.2环境说明
master 192.168.0.201
slave 192.168.0.220
两个节点都是CentOS7
1.3环境准备
永久关闭防火墙和selinux
systemctl disable firewalld systemctl stop firewalld setenforce 0
1.4网络配置
两台修改主机名:master/salve
设置hosts,能互相解析
1.5配置ssh互信
master yum -y install sshpass ssh-keygen 一路回车 ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.220 slave yum -y install sshpass ssh-keygen 一路回车 ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.201 测试ssh对方主机,不提示输入密码则OK
2.安装JDK
两台机器都装
tar zxvf jdk-8u65-linux-x64.tar.gz mv jdk1.8.0_65 /usr/jdk
2.1设置环境变量
两台机器都设置
export JAVA_HOME=/usr/jdk export JRE_HOME=/usr/jdk/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin 执行 source /etc/profile
3.测试JDK
java -version
3.1安装Hadoop
官方网站下载CDH-2.6-hadoop:archive.cloudera.com/cdh6
tar zxvf hadoop-2.6.0-cdh6.4.8.tar.gz mv hadoop-2.6.0-cdh6.4.8 /usr/hadoop cd /usr/hadoop mkdir -p dfs/name mkdir -p dfs/data mkdir -p tmp
3.2添加slave
cd /usr/hadoop/etc/hadoop vim slaves 192.168.0.220 #添加slaveIP
3.3修改hadoop-env.sh和yarn.env.sh
vim hadoop-env.sh / vim yarn-env.sh export JAVA_HOME=/usr/jdk #加入java变量
3.4修改core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://192.168.0.201:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131702</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/tmp</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration>
3.5修改hdfs-site.xml
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/usr/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>192.168.0.201:9001</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration> </configuration>
3.6修改mapred-site.xml
configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>192.168.0.201:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>192.168.0.201:19888</value> </property> </configuration>
3.7修改yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.0.201:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.0.201:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.0.201:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>192.168.0.201:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>192.168.0.201:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>768</value> </property> </configuration>
4.把配置文件拷贝到slave端
scp -r /usr/hadoop root@192.168.0.220:/usr/
5.格式化nanenode
./bin/hdfs namenode -format
5.1启动hdfs
./sbin/start-dfs.sh$ ./sbin/start-yarn.sh
5.2检查启动情况
输入192.168.0.201:8088
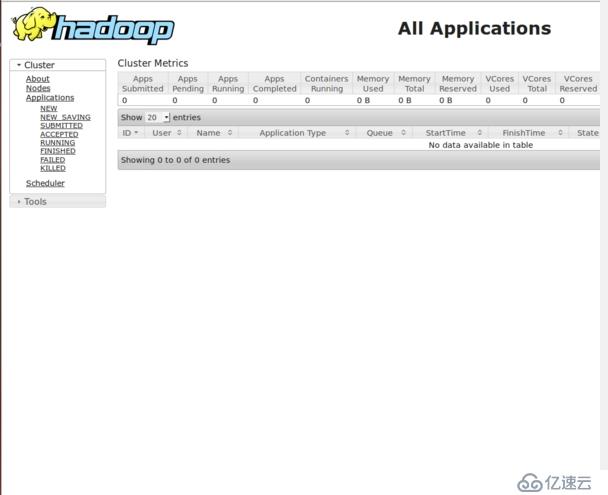
输入网址:192.168.0.201:9001
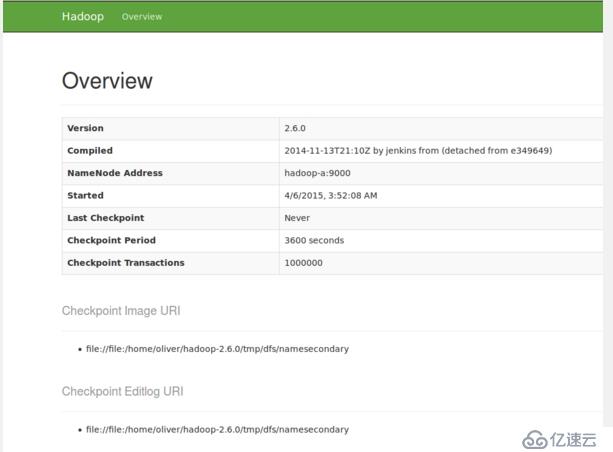
配置文件详解:
core-site.xml
hadoop.tmp.dir hadoop文件系统依赖的基础配置,很多路径都依赖它。如果hdfs-site-xml中不配置namenode 和datanode的存放位置,默认就放在这个路径下 fs.defaultFS 这里的值指的是默认的HDFS路径。这里只有一个HDFS集群,在这里指定!
hdfs-site.xml
dfs.replication 指定DataNode存储block的副本数量。默认值是3个,我们现在有4个DataNode,该值不大于4即可
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





