本文小编为大家详细介绍“Python怎么实现批量向PDF文件添加中文水印”,内容详细,步骤清晰,细节处理妥当,希望这篇“Python怎么实现批量向PDF文件添加中文水印”文章能帮助大家解决疑惑,下面跟着小编的思路慢慢深入,一起来学习新知识吧。
可以通过设置批量PDF文件所在的路径及需要添加的水印名称可以实现批量添加PDF水印的效果。
实现思路是这样的,通过在批量PDF文件路径下面生成一个带有水印的PDF模板。最后,将批量文件的每个PDF页面和水印模板进行合并完成批量添加水印的效果。
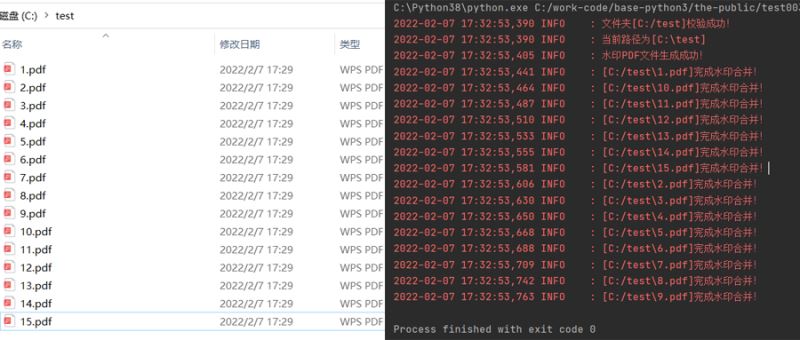
需要注意的是批量PDF文件必须和PDF模板水印文件的大小尺寸保持一致,这个可以在代码里面调节一下就成了。
首先将需要添加水印的PDF文件准备好放在一个文件夹下面。
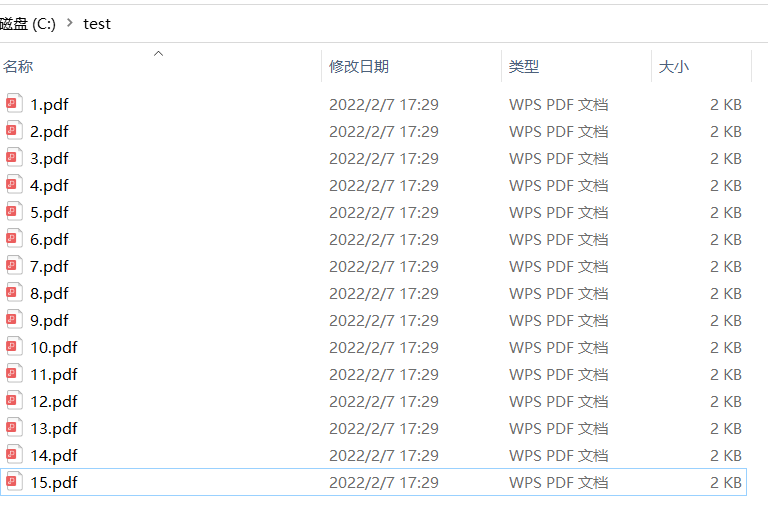
在代码中设置好PDF批量文件的路径及水印名称。
if __name__ == '__main__':
main('C:/pdf', '我是一个水印')内部实现过程都封装在main()函数里面了,这里改一下水印名称和批量PDF文件路径直接执行就好了。
启动以后,出现如下面的结果说明已经执行完成了。

为了不覆盖原来的PDF文件,合并后的文件都是添加了"已合并"字样的PDF文件。
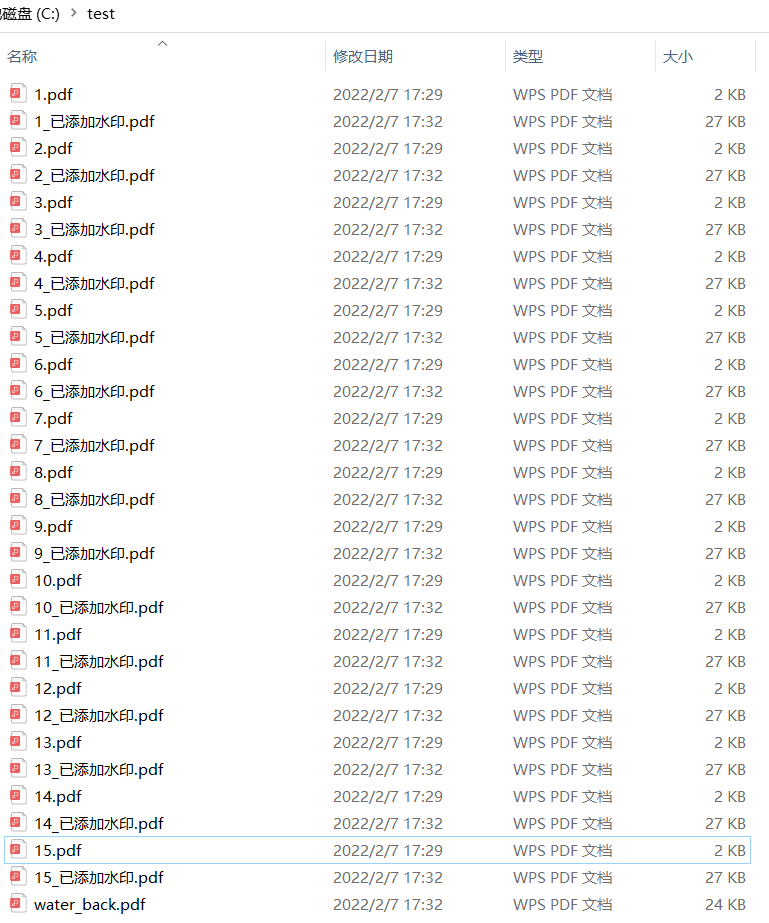
说完了怎么操作,看一下主要的代码块部分有哪些吧。
其中用到的第三方库有下面这些,里面我写了相关的注释。
import os # 应用文件操作
# reportlab是Python的一个标准库,可以画图、画表格、编辑文字,最后可以输出PDF格式。
from reportlab.pdfgen import canvas
from reportlab.lib.units import cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
pdfmetrics.registerFont(TTFont('songti', 'C:/Windows/Fonts/simsun.ttc')) # 加载宋体
# PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面。
from PyPDF2 import PdfFileWriter, PdfFileReader
import logging # 日志打印库日志模块的初始化也比较简单,前面的文章中都有过相关的调用。
# 初始化日志设置
logger = logging.getLogger('批量添加水印')
logging.basicConfig(format='%(asctime)s %(levelname)-8s: %(message)s')
logger.setLevel(logging.DEBUG)日志初始化完成后在后面需要打印日志的地方调用就可以了。
实现过程主要有三个函数来实现的,一个是为了生成水印模板、另一个是使水印模板和批量PDF文件执行合并从而实现添加水印的功能、还有一个就是逐个遍历批量PDF文件使其能够逐个实现水印合并。
水印模板生成函数。
def generate_water_pdf(content):
'''
生成带有水印的PDF
:param content: 水印名称
:return:
'''
cans = canvas.Canvas('water_back.pdf', pagesize=(21 * cm, 29.7 * cm))
cans.translate(10 * cm,
12 * cm) # 移动原点坐标
cans.setFont('songti', 23) # 设置字体为宋体、大小为23号
cans.setFillColorRGB(0.5, 0.5,
0.5) # 设置字体背景颜色
cans.rotate(45) # 设置字体倾斜45度
cans.drawString(-7 * cm, 0 * cm, content)
cans.drawString(7 * cm, 0 * cm, content)
cans.drawString(0 * cm, 7 * cm, content)
cans.drawString(0 * cm, -7 * cm, content)
cans.save() # 保存水印的PDF文件水印合成实现函数。
def insert_water_to_pdf(input_pdf, output_pdf, water_pdf): ''' 合并水印到PDF文件中 :param input_pdf: 输入文件路径 :param output_pdf: 输出文件路径 :param water_pdf: 水印文件路径 :return: ''' water = PdfFileReader(water_pdf) # 读取水印PDF water_page = water.getPage(0) # 获取水印PDF的第一页 pdf = PdfFileReader(input_pdf, strict=False) # 读取需要添加水印的文件 pdf_writer = PdfFileWriter() # 创建PDF文件写入对象 for page in range(pdf.getNumPages()): # 遍历每一页PDF对象 pdf_page = pdf.getPage(page) # 获取PDF的当前页对象 pdf_page.mergePage(water_page) # 将水印页合并到当前页中 pdf_writer.addPage(pdf_page) # 将合并后的PDF对象页添加到PDF写入对象中 output_file = open(output_pdf, 'wb') # 打开PDF输出文件 pdf_writer.write(output_file) # 将文件写入到输出文件 output_file.close() # 关闭写入流
批量PDF文件遍历调用合成函数。
def main(diretory, current):
if os.path.isdir(diretory):
logger.info('文件夹[' + diretory + ']校验成功!')
os.chdir(diretory)
logger.info('当前路径为[' + os.getcwd() + ']')
generate_water_pdf(current)
logger.info('水印PDF文件生成成功!')
for file_path, dir_names, file_names in os.walk(r'' + os.getcwd()):
for file_name in file_names:
try:
name = file_name.split('.')[0]
if name == 'water_back':
continue
else:
file_name_path = os.path.join(file_path, file_name)
output_file_path = file_name_path.split('.')[0] + '_已添加水印.pdf'
insert_water_to_pdf(file_name_path, output_file_path, 'water_back.pdf')
logger.info('[' + file_name_path + ']完成水印合并!')
except Exception as e:
logger.error('[' + file_name_path + ']发生异常,执行下一个!')
logger.error('异常信息:' + repr(e))
else:
logger.info('文件夹[' + diretory + ']校验失败!')主要实现过程就是通过上面三个函数来完成的,最后调用后台入口函数将mian()函数调用执行就可以了。
# -*- coding:utf-8 -*-
# @author Python 集中营
# @date 2022/1/27
# @file test4.py
# done
# 批量向PDF文件添加中文水印
import os # 应用文件操作
# reportlab是Python的一个标准库,可以画图、画表格、编辑文字,最后可以输出PDF格式。
from reportlab.pdfgen import canvas
from reportlab.lib.units import cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
pdfmetrics.registerFont(TTFont('songti', 'C:/Windows/Fonts/simsun.ttc')) # 加载宋体
# PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面。
from PyPDF2 import PdfFileWriter, PdfFileReader
import logging # 日志打印库
# 初始化日志设置
logger = logging.getLogger('批量添加水印')
logging.basicConfig(format='%(asctime)s %(levelname)-8s: %(message)s')
logger.setLevel(logging.DEBUG)
def generate_water_pdf(content):
'''
生成带有水印的PDF
:param content: 水印名称
:return:
'''
cans = canvas.Canvas('water_back.pdf', pagesize=(21 * cm, 29.7 * cm))
cans.translate(10 * cm,
12 * cm) # 移动原点坐标
cans.setFont('songti', 23) # 设置字体为宋体、大小为23号
cans.setFillColorRGB(0.5, 0.5,
0.5) # 设置字体背景颜色
cans.rotate(45) # 设置字体倾斜45度
cans.drawString(-7 * cm, 0 * cm, content)
cans.drawString(7 * cm, 0 * cm, content)
cans.drawString(0 * cm, 7 * cm, content)
cans.drawString(0 * cm, -7 * cm, content)
cans.save() # 保存水印的PDF文件
def insert_water_to_pdf(input_pdf, output_pdf, water_pdf):
'''
合并水印到PDF文件中
:param input_pdf: 输入文件路径
:param output_pdf: 输出文件路径
:param water_pdf: 水印文件路径
:return:
'''
water = PdfFileReader(water_pdf) # 读取水印PDF
water_page = water.getPage(0) # 获取水印PDF的第一页
pdf = PdfFileReader(input_pdf, strict=False) # 读取需要添加水印的文件
pdf_writer = PdfFileWriter() # 创建PDF文件写入对象
for page in range(pdf.getNumPages()): # 遍历每一页PDF对象
pdf_page = pdf.getPage(page) # 获取PDF的当前页对象
pdf_page.mergePage(water_page) # 将水印页合并到当前页中
pdf_writer.addPage(pdf_page) # 将合并后的PDF对象页添加到PDF写入对象中
output_file = open(output_pdf, 'wb') # 打开PDF输出文件
pdf_writer.write(output_file) # 将文件写入到输出文件
output_file.close() # 关闭写入流
def main(diretory, current):
if os.path.isdir(diretory):
logger.info('文件夹[' + diretory + ']校验成功!')
os.chdir(diretory)
logger.info('当前路径为[' + os.getcwd() + ']')
generate_water_pdf(current)
logger.info('水印PDF文件生成成功!')
for file_path, dir_names, file_names in os.walk(r'' + os.getcwd()):
for file_name in file_names:
try:
name = file_name.split('.')[0]
if name == 'water_back':
continue
else:
file_name_path = os.path.join(file_path, file_name)
output_file_path = file_name_path.split('.')[0] + '_已添加水印.pdf'
insert_water_to_pdf(file_name_path, output_file_path, 'water_back.pdf')
logger.info('[' + file_name_path + ']完成水印合并!')
except Exception as e:
logger.error('[' + file_name_path + ']发生异常,执行下一个!')
logger.error('异常信息:' + repr(e))
else:
logger.info('文件夹[' + diretory + ']校验失败!')
if __name__ == '__main__':
main('C:/pdf', '我是一个水印')读到这里,这篇“Python怎么实现批量向PDF文件添加中文水印”文章已经介绍完毕,想要掌握这篇文章的知识点还需要大家自己动手实践使用过才能领会,如果想了解更多相关内容的文章,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





