本文在介绍关于C++实现稀疏矩阵的压缩存储、转置、快速转置的基础上,重点探讨了其具体步骤分享了代码,本文内容紧凑,希望大家可以有所收获。
/*稀疏矩阵的压缩存储、转置、快速转置*/
#include <iostream>
using namespace std;
#include <vector>
//三元组
template<class T>
struct Triple
{
size_t _row;
size_t _col;
T _value;
Triple(size_t row = 0, size_t col = 0, const T& value = T())
:_row(row)
,_col(col)
,_value(value)
{}
};
template<class T>
class SparseMatrix
{
public:
SparseMatrix(T* a = NULL, size_t M = 0, size_t N = 0, const T& invalid = T())
:_rowSize(M)
,_colSize(N)
,_invalid(invalid)
{
for (size_t i = 0; i < M; ++i)
{
for (size_t j = 0; j < N; ++j)
{
if (a[i*N+j] != _invalid)
{
Triple<T> t;
t._row = i;
t._col = j;
t._value = a[i*N+j];
_a.push_back(t);
}
}
}
}
void Display()
{
size_t index = 0;
for (size_t i = 0; i < _rowSize; ++i)
{
for (size_t j = 0; j < _colSize; ++j)
{
if (index < _a.size()
&& (_a[index]._row == i)
&& (_a[index]._col == j))
{
cout<<_a[index++]._value<<" ";
}
else
{
cout<<_invalid<<" ";
}
}
cout<<endl;
}
}
//矩阵转置 时间复杂度为 O(有效数据的个数*原矩阵的列数)
SparseMatrix<T> Transport()
{
SparseMatrix<T> sm;
sm._colSize = _rowSize;
sm._rowSize = _colSize;
sm._invalid = _invalid;
for (size_t i = 0; i < _colSize; ++i)
{
size_t index = 0;
while (index < _a.size())
{
if (_a[index]._col == i)
{
Triple<T> t;
t._row = _a[index]._col;
t._col = _a[index]._row;
t._value = _a[index]._value;
sm._a.push_back(t);
}
++index;
}
}
return sm;
}
//快速转置 时间复杂度为O(有效数据的个数+原矩阵的列数)
SparseMatrix<T> FastTransport()
{
SparseMatrix<T> sm;
sm._rowSize = _colSize;
sm._colSize = _rowSize;
sm._invalid = _invalid;
int* RowCounts = new int[_colSize];
int* RowStart = new int [_colSize];
memset(RowCounts, 0, sizeof(int)*_colSize);
memset(RowStart, 0, sizeof(int)*_colSize);
size_t index = 0;
while (index < _a.size())
{
++RowCounts[_a[index]._col];
++index;
}
for (size_t i = 1; i < _colSize; ++i)
{
RowStart[i] = RowStart[i-1] + RowCounts[i-1];
}
index = 0;
sm._a.resize(_a.size());
while (index < sm._a.size())
{
Triple<T> t;
t._row = _a[index]._col;
t._col = _a[index]._row;
t._value = _a[index]._value;
sm._a[RowStart[_a[index]._col]] = t;
++RowStart[_a[index]._col];
++index;
}
delete[] RowCounts;
delete[] RowStart;
return sm;
}
protected:
vector<Triple<T>> _a;
size_t _rowSize;
size_t _colSize;
T _invalid;
};
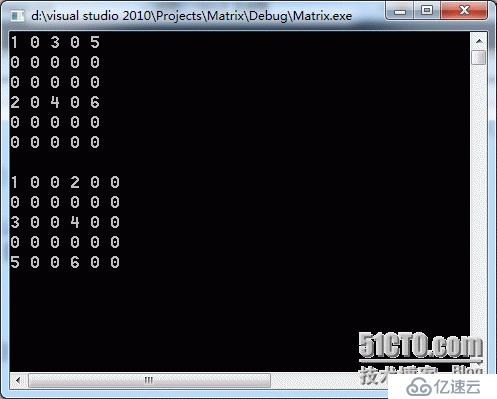
void Test()
{
int array [6][5] =
{
{1, 0, 3, 0, 5},
{0, 0, 0, 0, 0},
{0, 0, 0, 0, 0},
{2, 0, 4, 0, 6},
{0, 0, 0, 0, 0},
{0, 0, 0, 0, 0}
};
SparseMatrix<int> sm1((int*)array, 6, 5, 0);
sm1.Display();
cout<<endl;
//SprseMatrix<int> sm2 = sm1.Transport();
SparseMatrix<int> sm2 = sm1.FastTransport();
sm2.Display();
}
int main()
{
Test();
return 0;
}
看完上诉内容,你们掌握C++实现稀疏矩阵的压缩存储、转置、快速转置的方法了吗?如果想了解更多相关内容,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





