这篇文章给大家分享的是有关RSS与爬虫怎么搜集数据的内容。小编觉得挺实用的,因此分享给大家做个参考。一起跟随小编过来看看吧。
摘要:数据的价值被挖掘出来之前,先要通过收集、存储、分析计算等过程,获得全面、准确的数据是数据价值挖掘的基础。本期CSDN云计算俱乐部“大数据故事”将从最为常见的数据搜集方式说起——RSS和搜索引擎爬虫。
12月30日,CSDN云计算俱乐部活动在3W咖啡举行,活动主题是“RSS与爬虫:大数据的故事——从如何搜集数据开始”。数据的价值被挖掘出来之前,先要通过收集、存储、分析计算等过程,获得全面、准确的数据是数据价值挖掘的基础。也许当下数据并不能为企业或组织带来实际价值,但作为有远见的决策者应该意识到,应尽早收集、保存重要数据,数据就是财富。本期“大数据故事”将从最为常见的数据搜集方式说起——RSS和搜索引擎爬虫。

活动现场座无虚席
首先,北京万方软件股份有限公司图书馆事业部总经理崔克俊分享的主题是“大规模进行RSS聚合和网站下载在科学研究中的初步应用”。崔克俊在图书馆、情报行业从业12年,有丰富的数据采集经验,他主要分享了信息聚合的一种重要方式RSS及其实现技术。
RSS(Really Simple Syndication)是一种消息来源格式规范,用以聚合经常发布更新数据的网站,例如博客文章、新闻、音频或视频的网摘。RSS文件包含了全文或是节录的文字,再加上发用者所订阅之网摘布数据和授权的元数据。
对某一行业密切相关的几百个甚至几千个RSS种子进行的聚合,将能快速、全面了解某一行的最新动态;对某一行业的的几十个甚至几百个网站进行完整的数据下载,并进行数据挖掘,将能了解某一主题在该行业发展的来龙去脉。

北京万方软件股份有限公司图书馆事业部总经理 崔克俊
崔克俊以高能物理研究所为例,介绍了RSS在科研院所的应用。 高能物理信息监测对象为全球高能物理同行机构:实验室、行业学会、国际协会、各国主管科研政府机构、重点综合性科学出版物、高能物理试验项目和实验设施。监控的信息类型为:新闻、论文、会议报告、分析评论、预印本、案例研究、多媒体、图书、招聘信息等。
高能物理文献信息所采用最先进的开源内容管理系统 Drupal,开源搜索技术 Apache Solr,以及Google员工开发的能实时订阅新闻的 PubSubHubbub技术和Amazon的 OpenSearch,建立了一套高能物理信息监测系统,有别于传统的RSS订阅和推送,实现了几乎实时的信息抓取和任意关键词、任意类别、复合条件新闻的主动推送。
接下来,崔克俊分享了Drupal、Apache Solr、PubSubHubbub和OpenSearch等技术的使用心得。
接下来,宜搜科技搜索部架构师爬虫组负责人叶顺平带来了题为“网页搜索爬虫时效性系统”的分享,包括时效性系统的主要目标、架构,以及各个子模块的设计方案。

宜搜科技搜索部架构师爬虫组负责人 叶顺平
网页爬虫的几个目标是覆盖率高、死链率低和实效性好,爬虫实效性系统的目标也差不多,主要是实现新网页快速和全面的收录。下图为时效性系统的整体架构:
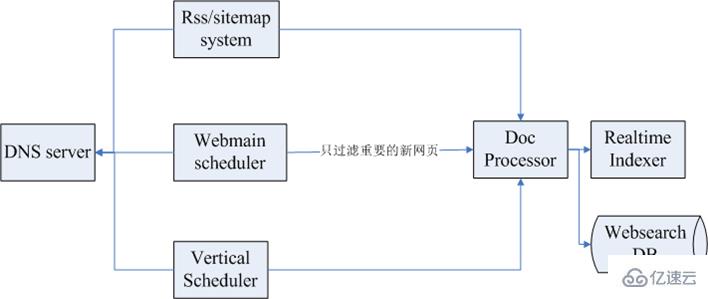
其中,上面第一个是RSS/sitemap一个子系统,接下来是网页泛爬的调度系统Webmain scheduler,然后是一个时效性模块Vertical Scheduler,最左侧是DNS服务,抓取的时候,一般是几十台甚至是几百台的抓取集群,如果每一台都有防御的话对DNS的压力比较大,所以一般有一个DNS的服务模块来做全局的服务。数据抓取完毕后,一般会做后续的数据处理。
涉及到实效性的模块包括以下几个:
RSS/sitemap系统:时效性系统利用RSS/sitemap的过程是挖掘种子,定时抓取,解析链接发布时间,将较新的网页优先抓取并索引。
泛爬系统:泛爬系统设计良好的话有助于提高时效性网页的高覆盖率,但泛爬需要尽可能缩短调度周期。
种子调度系统:主要是一个时效性的种子库,这个种子库里面有一些信息调度系统会不断地扫描这个数据库,然后发给抓取集群,这个集群抓取完会进行一些抽取链接的处理,接下来把这些按类别发出去,各个垂直频道会获取到时效性的数据。
种子的挖掘:涉及到页面解析或其它的一些挖掘手段,可以通过站点地图,还有导航条来构建,还要基于页面结构特征和页面变更规律。
种子的更新机制:记录每个种子的抓取历史,follow的链接信息,定期根据种子的外链更新特征,重新计算种子的更新周期。
抓取系统与JavaScript解析:使用浏览器进行抓取,搭建一个基于浏览器抓取的抓取集群。或采用开源项目,如Qtwebkit。
感谢各位的阅读!关于RSS与爬虫怎么搜集数据就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





