博文目录
一、索引
二、视图
三、存储过程
四、系统存储过程
五、触发器
六、事务
七、锁
索引提供指针以指向存储在表中指定列的数据值,然后根据指定的次序排列这些指针,再跟随指针到达包含该值的列。
数据库中的索引与书籍中的目录相似。在一本书中,无需阅读整本书,利用目录就可以快速的查找到所需的信息。在数据库中,索引使数据库程序无须对整个表进行扫描,就可以在其中找到所需的数据。书中的目录就是一个词语列表,其中注明了包含各个词的页码。而数据库中的索引是某个表中一列或若干列值的集合,以及物理表示这些值得数据业的逻辑指针清单。
索引是SQL Server编排数据的内部方法,它为SQL Server提供一种方法来编排查询数据的路由。
索引页是数据库中存储索引的数据页。索引页存放检索数据行的关键字页以及该数据行的地址指针。通过使用索引,可以大大提高数据库的检索速度,改善数据库性能。
唯一索引不允许两行具有相同的索引值。
如果现有数据中存在重复的键值,则一般情况下大多数数据库不允许创建唯一索引。当新数据使表中的键值重复时,数据库也拒绝接收此数据。创建了唯一约束,将自动创建唯一索引。尽管唯一索引有助于找到信息,但是为了获得最佳性能,建议使用主键约束。
在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。
主建索引要求主键中的每个值都是唯一的。当在查询使用主键索引时,它还允许快速访问数据。
在聚集索引中,表中各行的物理顺序与键值的逻辑(索引)顺序相同。一个表中只能包含一个聚集索引。
非聚集索引建立在索引页上,在查询数据是可以从索引中找到记录存放的位置。
非聚集索引使表中各行数据存放的物理顺序与键值的逻辑顺序不匹配。聚集索引比非聚集索引有更快的数据访问速度。在SQL Server中,一个表只能创建一个聚集索引,但可以有多个非聚集索引。设置某列为主键,该列就默认为聚集索引。
在创建索引时,并不是只能对其中一列创建索引,与创建主键一样,可以将多个列组合作为索引,这种索引称为复合索引。
需要注意的是:只有用到复合索引的第一列或整个复合索引列作为条件完成数据查询时才会用到该索引。
全文索引是一种特殊类型的基于标记的功能性索引,由SQL Server中全文引擎服务创建和维护。
全文索引主要用于在大量文本中搜索字符串,此时使用全文索引的效率将大大高于使用T-SQL的LIKE关键字的效率。因为全文索引的创建过程与其他类型的索引有很大的差别。
创建索引的方法有两种:使用SSMS和T-SQL语句。
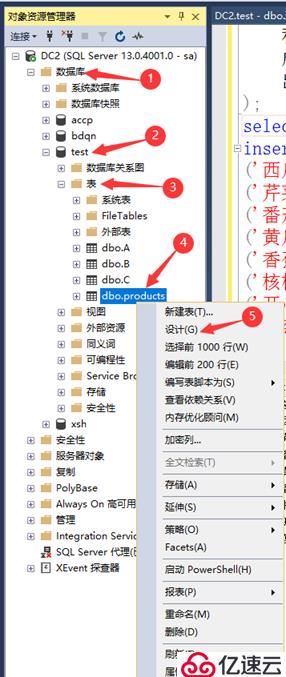
使用SSMS创建索引,如下:
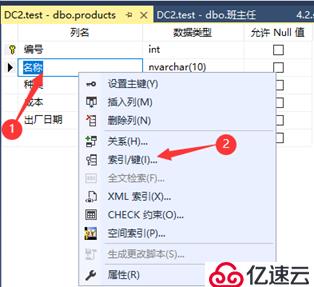
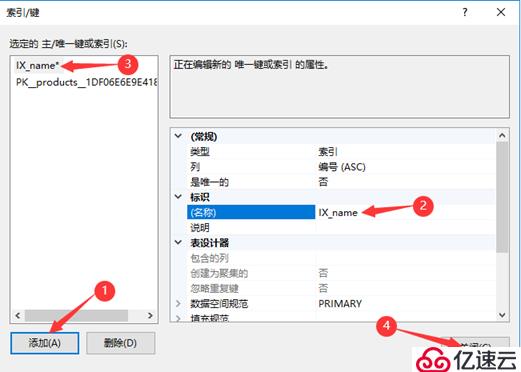
select * from products with (index=IX_name) where 名称='黄瓜';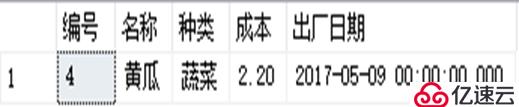
虽然可以指定SQL Server按哪个索引进行数据查询,但一般不需要人工指定。SQL Server将会根据所创建的索引,自动优化查询。
使用索引可加快数据检索速度,但为每个列都建立索引没有必要。因为索引本身也是需要维护,并占用一定的资源,可以按照以下标准选择建立索引的列。
频繁搜索的列;
经常用于查询选择的列;
经常排序、分组的列;
- 经常用于连接的列(主键/外键);
不要使用下面的列创建索引:
仅包含几个不同值的列;
- 表中仅包含几行;
视图是保存在数据库中的select查询。因此,对查询指定的大多数操作也可以在视图上进行。使用视图的原因有两个,其一是处于安全考虑,用户不必看到整个数据库结构,而隐藏部分数据;其二是符合用户日常业务逻辑,使其对数据更容易理解。
视图是另一种查看数据库中一个或多个表中的数据的方法。视图是一种虚拟表,通常是作为来自一个或多个表的行或列的子集创建的。当然,视图也可以包含全部的行和列。但是,视图并不是数据库中存储的数据值的集合,它的行和列来自查询中引用的表。在执行时,视图直接显示来自表中的数据。
视图充当着查询中指定的表的筛选器。定义视图的查询可以基于一个或多个表,也可以基于其他视图、当前数据库或其他数据库。
如下图所示,以表T和表T1为例,该视图可以包含这些表中的全部列或选定的部分列。如下图所示为一个用表T的A列和B列及表T1的B1、C1和D1列创建的视图: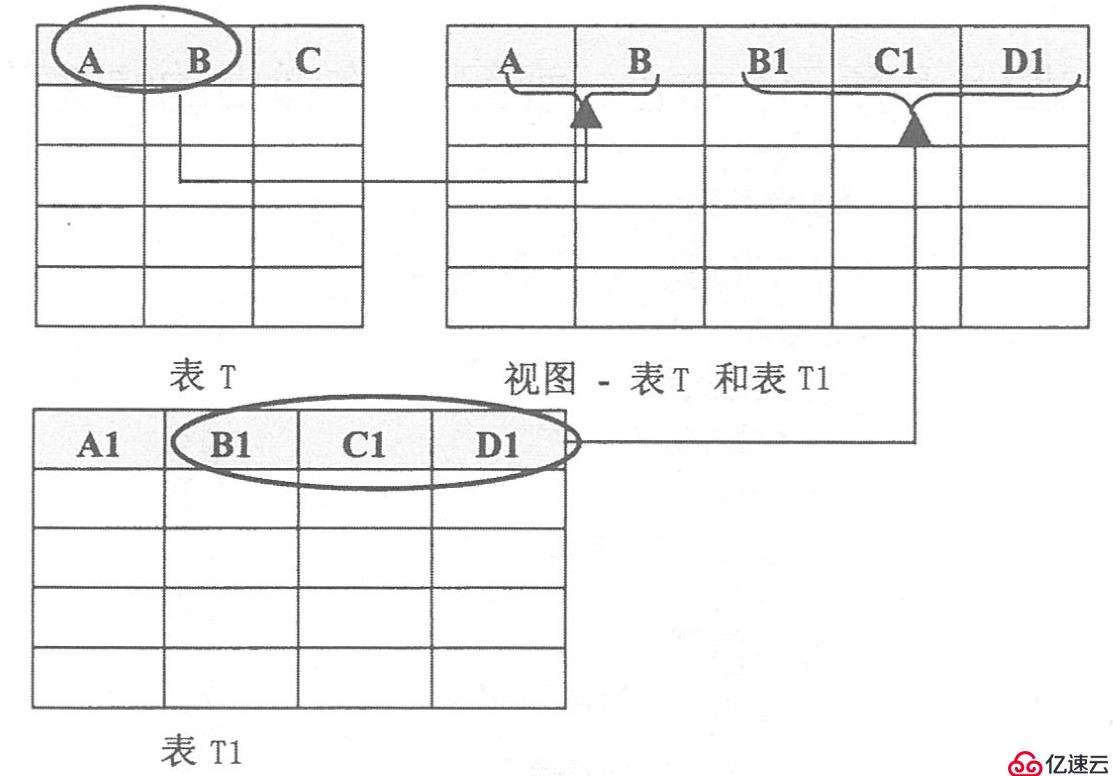
视图通常用来进行以下三种操作:
筛选表中的行;
防止未经许可的用户访问敏感的信息;
- 将多个物理数据表抽象为一个逻辑数据表;
对最终用户的好处:
对开发人员的好处:
在SQL Server中,创建视图的方法有两种:使用SSMS和使用T-SQL语句。
①展开数据库test,如图所示,右击“视图”,在弹出的快捷菜单中选择“新建视图”命令(自行创建多个表插入数据)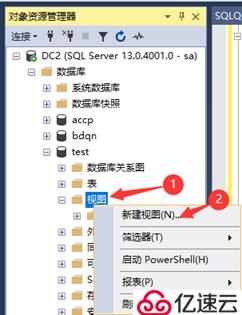
②将A、B、C三张表添加出来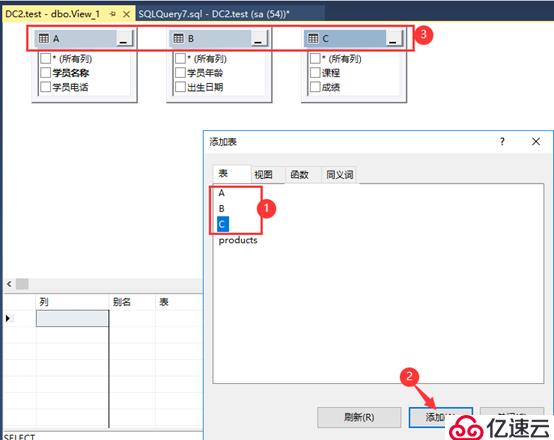
③选择希望看到列:学员名称、学员年龄、成绩,然后中下方自动生成T-SQL语句,按“crtl+R”快捷键执行语句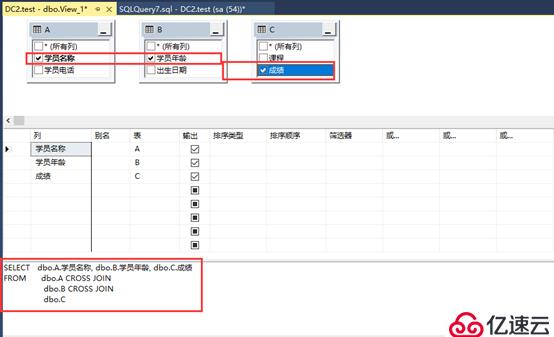
④选择T-SQL语句按“crtl+R”快捷键执行即可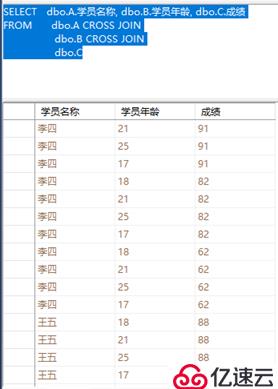
每个视图可以使用多个表;
与查询相似,一个视图可以嵌套另一个视图,最好不要超过三层;
- 视图定义中的select语句不能包含以下内容:
order by子句,除非子啊select语句的选择列表中也有一个TOP子句;
into关键字;
引用临时表或表变量;
SQL Server使用存储过程来避免远程发送并执行SQL代码带来的安全隐患。
当今的软件大多应用于网络中,而一般应用程序所运用的数据保存在数据库中。在没有使用存储过程的数据库应用程序中,用户大多从本地极端及客户端通过网络向服务器端发送SQL代码编写的请求,服务器端对接收到SQL代码进行语法编译后执行,并经指定结果传送回客户端,再由客户端的应用软件处理后输出。如果开发者对服务器的安全性考虑不全面,就会为非法者提供盗取数据的机会。如下图所示: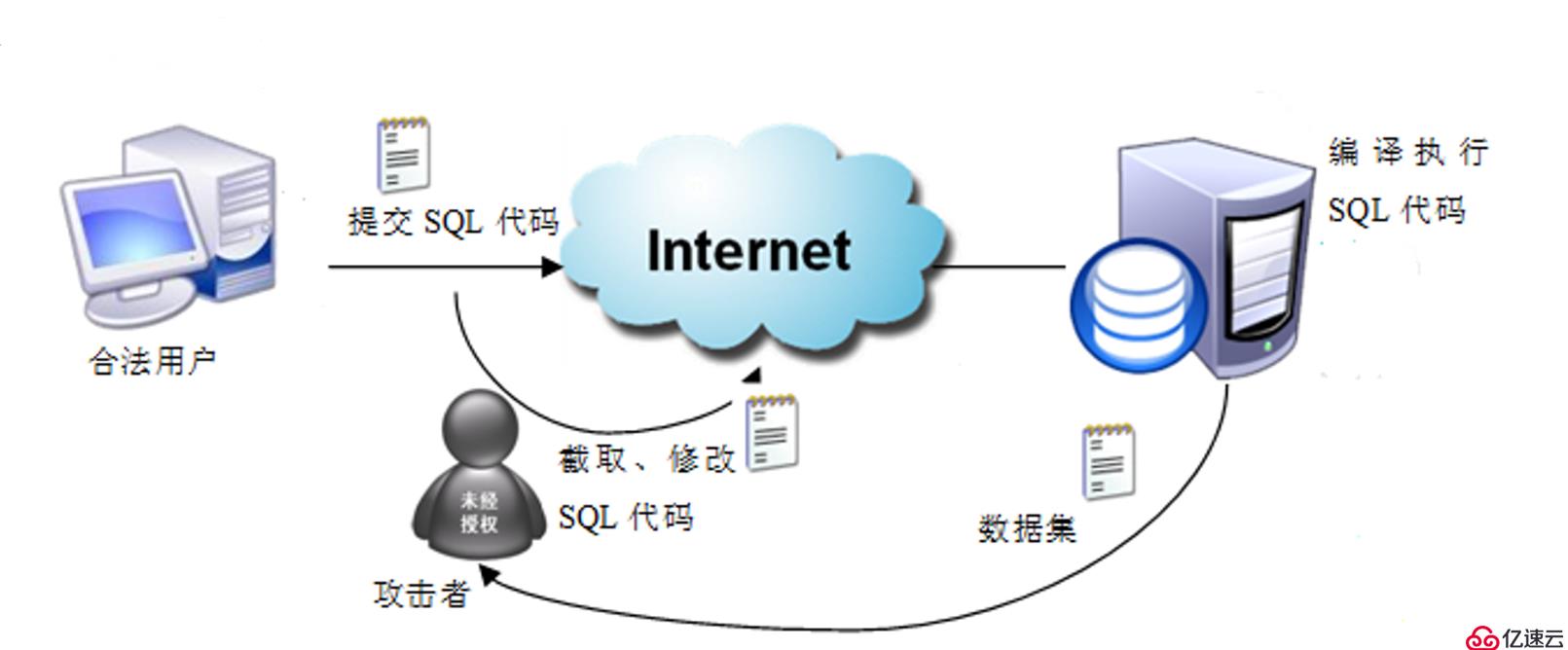
未经授权的非法者在网络中截取用户想服务器发送的SQL代码,改写后的恶意SQL代码提交到服务器编译并执行,最后非法者就比较容易地获得他所需的数据。
从图中,我们可以看到应用程序执行的过程是不安全的,主要在于以下几个方面:
数据不安全:网络传送SQL代码,容易被未经授权者截取;
每次提交SQL代码都要经过语法编译后再执行,影响应用程序的运行性能;
- 网络流量大。对于反复执行的相同SQL代码,将会在网络上多次传送,增加网络传输流量;
为了解决这些问题,我们可以采用存储过程把对数据库操作的SQL代码预先编译好并保存在服务器端,用户只需在本机上输入要执行的存储过程名称和必要的数据就可以直接调用执行存储过程完成行管的操作。这样。既减少了网络传输流量,又能保证应用程序的运行性能,同时也防止了未经授权者想截获SQL代码的行为。
存储过程是SQL语句和控制语句的预编译集合,保存在数据库中,可由应用程序调用执行,而且允许用户声明变量,逻辑控制语句及其他强大的编程功能。
存储过程可包含逻辑控制语句和数据操作语句,可以接收参数、输出参数、返回单个或多个结果集及返回值。
存储过程的优点如下:
模块化程序设计;
执行速度快、效率高;
减少网络流量;
- 具有良好的安全性;
SQL Server提供系统存储过程,它们是一组预编译的T-SQL语句。系统存储过程提供了管理数据库和更新表的机制,并充当从系统表中检索信息的快捷方式。
通过配置SQL Server,可以生成对象、用户、权限的信息和定义,这些信息和定义存储在系统表中。每个数据库分别有一个包含配置信息的系统表集,用户数据库的系统表是在创建数据库时自动创建的,用户可以通过系统存储过程访问和更新系统表。
SQL Server的系统存储过程的名称以“sp-”开头,并存放在Resource数据库中。系统管理员拥有这些存储过程的使用权限。可以在任何数据库中运行系统存储过程,但执行的结果会反映在当前数据库中。
示例如下:
<!--显示数据库-->
exec sp_databases;
<!--显示某个数据库对象的信息-->
exec sp_help A;
<!--显示所有数据库的信息-->
exec sp_helpdb;
<!--更改数据库名字-->
exec sp_renamedb 'xsh','benet';
<!--显示products表的约束-->
exec sp_helpconstraint products;
<!--显示products表的索引-->
exec sp_helpindex products;上面示例的输出结果集较多,在此不一一列举,请自行逐句运行,查看相应的输出结果。
根据系统存储过程的不同作用,系统存储过程可以分为不同类。扩展存储过程是SQL Server提供的各类系统存储过程中的一类。
扩展存储过程允许使用其他编程语言(如 C##语言)创建外部存储过程,为数据库用户提供从SQL Server实例到外部程序的接口,以便进行各种维护活动。它通常以“xp_”开头,以DLL形式单独存在。
一个常用的扩展存储过程为xp_cmdshell,它可以完成DOS命令下的一些操作,如创建文件夹、列出文件夹列表等,其语法如下:
开启系统cmdshell功能
<!--开启系统cmdshell功能-->
exec sp_configure 'show advanced options',1
reconfigure
exec sp_configure 'xp_cmdshell',1
reconfigure;<!--创建目录-->
exec xp_cmdshell 'mkdir D:\test', no_output;
<!--显示创建目录-->
exec xp_cmdshell 'dir d:\';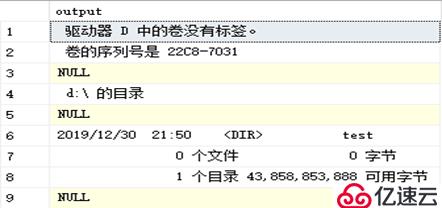
触发器是一种特殊类型的存储过程,当表中的数据发生更新时将自动调用,以响应INSERT、UPDATE或DELETE语句。
触发器是在对表进行插入、更新或删除操作时自动执行的存储过程。触发器通常用于强制业务规则,是一种高级约束,可以定义比用CHECK约束更为复杂的约束,可以行发杂的SQL语句(如IF/WHILE/CASE),可引用其他表中的列。触发器主要是通过事件进行触发而被执行的,而存储过程可以通过存储过程名称而被直接调用。当对某一表进行修改,,如UPDATE、INSERT和DELETE这些操作时,SQL Server会自动执行触发器所定义的SQL语句,从而确保对数据的处理必须符合由这些SQL语句所定义的规则。由此触发器可分为以下几种:

触发器的主要作用是,实现由主键和外键所不能保证的复杂的参照完整性和数据的一致性。
使用T-SQL语句创建触发器的语法如下:
CREATE TRIGGER trigger_name
ON table_name
[WITH ENCRYPTION]
FOR { [DELETE, INSERT, UPDATE] }
AS SQL语句
创建触发器时需要注意以下问题:
CREATE TRIGGER必须是批处理中的第一条语句,并且只能应用到一个表中;
触发器只能在当前的数据库中创建,不过触发器可以引用当前数据库的外部对象;
- 在同一条CREATE TRIGGER语句中,可以为多种用户操作(如INSERT和UPDATE)定义相同的触发器操作;
事务是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行。因此,事务是一个不可分隔的工作逻辑单元,在数据库系统上执行并发操作时,事务是作为最小的控制单元来使用的,它特别适用于多用户同时操作的数据库系统。
事务是作为单个逻辑工作单元执行的一系列操作。一个逻辑工作单元必须有四个属性,即原子性、一致性、隔离性及持久性,这些特性通常简称为ACID。
事务是一个完整的操作。事务的各元素是不可分的(原子的)。事务中的所有元素必须作为一个整体提交或回滚。如果事务中的任何元素失败、则整个事务将失败。
当事务完成时,数据必须处于一致状态。也就是说,在事务开始之前,数据库中存储的数据处于一致状态。在正在进行的事务中,数据可能处于不一致的状态,如数据可能有部分修改。然而,当事务成功完成时,数据必须再次回到已知的一致状态。通过事务对数据所做的修改不能损坏数据,或者说事务不能使数据存储处于不稳定的状态。
对数据进行修改的所有并发事务使彼此隔离的,这表明事务必须是独立的,它不应以任何方式依赖于或影响其他事务。修改数据的事务可以在另一个使用相同数据的事务开始之前访问这些数据,或者在另一个使用相同的数据,则直到该事务成功提交之后,对数据的修改才能生效。
事务的持久性指不管系统是否发生了故障,事务处理的结果都是永久的。
BEGIN TRANSACTIONCOMMIT TRANSACTIONROLLBACK TRANSACTIONBEGIN TRANSACTION语句后面的SQL语句对数据库的更新操作都将记录在事务日志中,直至遇到ROLLBACK TRANSACTION语句或COMMIT TRANSACTION语句。如果事务中某一操作失败且执行ROLLBACK TRANSACTION语句,那么在BEGIN TRANSACTION语句之后所有更新的数据都能回滚到事务开始前的状态。如果事务中的所有操作都全部正确完成,并且使用COMMIT TRANSACTION语句向数据库提交更新数据,那么这时候的数据又处在新的一致状态。
多个用户能够同时操纵同一个数据库中的数据,会发生数据不一致现象。也就是说,如果没有锁定且多个用户同时访问一个数据库,则当事务同时使用相同的数据时可能会发生问题。这些问题包括丢失、更新、脏读、不可重复读和幻觉读。数据库加锁就是为了解决以上的问题。
共享锁(S锁):用于读取资源所加的锁;
排他锁(X锁):和其他任何锁都不兼容,包括其他排他锁,排他锁用于数据修改;
- 更新锁(U锁):U锁可以看作S锁和X锁的结合,用于更新数据,更新数据时首先需要找到被更新的数据,此时可以理解为被查找的数据上了S锁。当找到需要修改的数据时,需要对被修改的资源上X锁。SQL Server通过U锁来避免死锁问题;
使用sys.dm_tran_locks动态管理视图;
- 使用profiler来捕捉锁信息;
死锁的本质是一种僵持状态,是由多个主体对资源的争用而导致的。要理解SQL Server中的死锁,可以参考如下图:
发生死锁需要如下四个必要条件:
互斥条件;
请求和等待条件;
不剥夺条件;
- 环路等待条件;
预防死锁就是破坏四个必要条件中的某一个和几个,使其不能形成死锁,常用方法如下:
破坏互斥条件;
破坏请求和等待条件;
- 破坏不剥夺条件;
———————— 本文至此结束,感谢阅读 ————————
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





