本篇内容介绍了“如何使用Python探索变量的概率分布”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
首先,正态分布又名高斯分布
它以数学天才 Carl Friedrich Gauss 命名
正态分布又名高斯分布
3 . 越简单的模型越是常用,因为它们能够被很好的解释和理解。正态分布非常简单,这就是它是如此的常用的原因。
因此,理解正态分布非常有必要。
首先介绍一下相关概念。
考虑一个预测模型,该模型可以是我们的数据科学研究中的一个组件。
如果我们想精确预测一个变量的值,那么我们首先要做的就是理解该变量的潜在特性。
首先我们要知道该变量的可能取值,还要知道这些值是连续的还是离散的。简单来讲,如果我们要预测一个的取值,那么第一步就是明白它的取值是1 到 6(离散)。
第二步就是确定每个可能取值(事件)发生的概率。如果某个取值永远都不会出现,那么该值的概率就是 0 。
事件的概率越大,该事件越容易出现。
在实际操作中,我们可以大量重复进行某个实验,并记录该实验对应的输出变量的结果。
我们可以将这些取值分为不同的集合类,在每一类中,我们记录属于该类结果的次数。例如,我们可以投10000次,每次都有6种可能的取值,我们可以将类别数设为6,然后我们就可以开始对每一类出现的次数进行计数了。
我们可以画出上述结果的曲线,该曲线就是概率分布曲线。目标变量每个取值的可能性就由其概率分布决定。
一旦我们知道了变量的概率分布,我们就可以开始估计事件出现的概率了,我们甚至可以使用一些概率公式。至此,我们就可更好的理解变量的特性了。概率分布取决于样本的一些特征,例如平均值,标准偏差,偏度和峰度。
如果将所有概率值求和,那么求和结果将会是100%
世界上存在着很多不同的概率分布,而最广泛使用的就是正态分布了。
我们可以画出正态分布的概率分布曲线,可以看到该曲线是一个钟型的曲线。如果变量的均值,模和中值相等,那么该变量就呈现正态分布。
如下图所示,为正态分布的概率分布曲线:
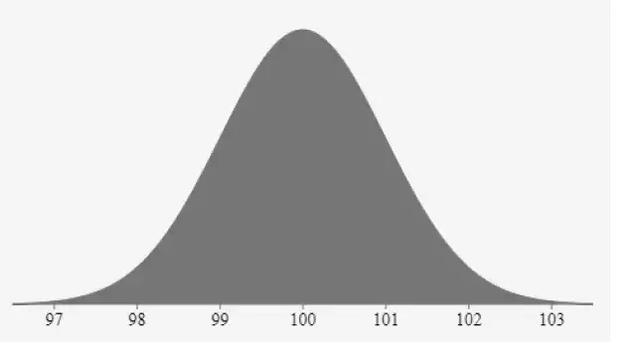
理解和估计变量的概率分布非常重要。
下面列出的变量的分布都比较接近正态分布:
人群的身高
成年人的血压
传播中的粒子的位置
测量误差
回归中的残差
人群的鞋码
一天中雇员回家的总耗时
教育指标
此外,生活中有大量的变量都是具有 x % 置信度的正态变量,其中,x<100。
正态分布只依赖于数据集的两个特征:样本的均值和方差。
均值——样本所有取值的平均
方差——该指标衡量了样本总体偏离均值的程度
正态分布的这种统计特性使得问题变得异常简单,任何具有正态分布的变量,都可以进行高精度分预测。
值得注意的是,大自然中发现的变量,大多近似服从正态分布。
正态分布很容易解释,这是因为:
正态分布的均值,模和中位数是相等的。
我们只需要用均值和标准差就能解释整个分布。
正态分布是我们熟悉的正常行为
这个现象可以由如下定理理解释:当在大量随机变量上重复很多次实验时,它们的分布总和将非常接近正态分布。
由于人的身高是一个随机变量,并且基于其他随机变量,例如一个人消耗的营养量,他们所处的环境,他们的遗传等等,这些变量的分布总和最终是非常接近正态的。
这就是中心极限定理。
我们从上文的分析得出,正态分布是许多随机分布的总和。 如果我们绘制正态分布密度函数,那么它的曲线将具有以下特征:
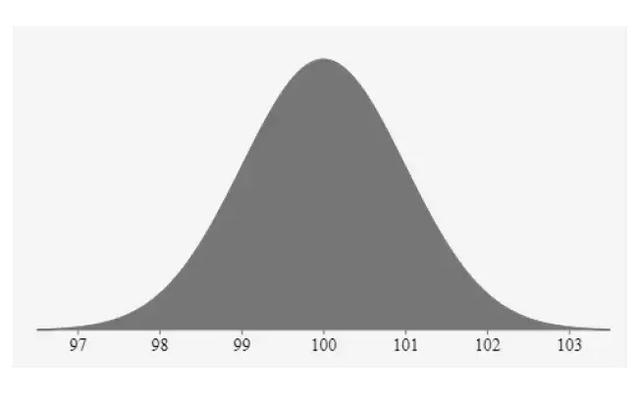
如上图所示,该钟形曲线有均值为 100,标准差为1:
均值是曲线的中心。 这是曲线的最高点,因为大多数点都是均值。
曲线两侧的点数相等。 曲线的中心具有最多的点数。
曲线下的总面积是变量所有取值的总概率。
因此总曲线面积为 100%
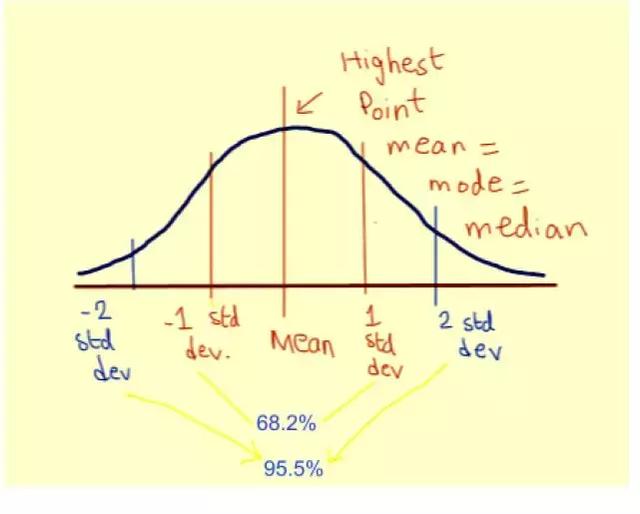
更进一步,如上图所示:
约 68.2% 的点在 -1 到 1 个标准偏差范围内。
约 95.5% 的点在 -2 到 2 个标准偏差范围内。
约 99.7% 的点在 -3 至 3 个标准偏差范围内。
这使我们可以轻松估计变量的变化性,并给出相应置信水平,它的可能取值是多少。例如,在上面的灰色钟形曲线中,变量值在 99-101 之间的可能性为 68.2%。
正态概率分布函数
概率密度函数的形式如下:

概率密度函数基本上可以看作是连续随机变量取值的概率。
正态分布是钟形曲线,其中mean = mode = median。
如果使用概率密度函数绘制变量的概率分布曲线,则给定范围的曲线下的面积,表示目标变量在该范围内取值的概率。
概率分布曲线基于概率分布函数,而概率分布函数本身是根据诸如平均值或标准差等多个参数计算的。
我们可以使用概率分布函数来查找随机变量取值范围内的值的相对概率。 例如,我们可以记录股票的每日收益,将它们分组到适当的集合类中,然后计算股票在未来获得20-40%收益的概率。
标准差越大,样品中的变化性越大。
最简单的方法是加载 data frame 中的所有特征,然后运行以下脚本(使用pandas 库):
DataFrame.hist(bins=10) #Make a histogram of the DataFrame.
该函数向我们展示了所有变量的概率分布。
如果我们将大量具有不同分布的随机变量加起来,所得到的新变量将最终具有正态分布。这就是前文所述的中心极限定理。
服从正态分布的变量总是服从正态分布。 例如,假设 A 和 B 是两个具有正态分布的变量,那么:
• A x B 是正态分布
• A + B 是正态分布
因此,使用正态分布,预测变量并在一定范围内找到它的概率会变得非常简单。
我们可以将变量的分布转换为正态分布。
我们有多种方法将非正态分布转化为正态分布:
1.线性变换
一旦我们收集到变量的样本数据,我们就可以对样本进行线性变化,并计算Z得分:
计算平均值
计算标准偏差
对于每个 x,使用以下方法计算 Z:

2.使用 Boxcox 变换
我们可以使用 SciPy 包将数据转换为正态分布:
scipy.stats.boxcox(x, lmbda=None, alpha=None)
3.使用 Yeo-Johnson 变换
另外,我们可以使用 yeo-johnson 变换。 Python 的 sci-kit learn 库提供了相应的功能:
sklearn.preprocessing.PowerTransformer(method=’yeojohnson’,standardize=True, copy=True)
正态分布的问题
由于正态分布简单且易于理解,因此它也在预测研究中被过度使用。 假设变量服从正态分布会有一些显而易见的缺陷。 例如,我们不能假设股票价格服从正态分布,因为价格不能为负。 因此,我们可以假设股票价格服从对数正态分布,以确保它永远不会低于零。
我们知道股票收益可能是负数,因此收益可以假设服从正态分布。
假设变量服从正态分布而不进行任何分析是愚蠢的。
变量可以服从Poisson,Student-t 或 Binomial 分布,盲目地假设变量服从正态分布可能导致不准确的结果。
“如何使用Python探索变量的概率分布”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





