JVMзҡ„зӨәдҫӢеҲҶжһҗ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢJVMзҡ„зӨәдҫӢеҲҶжһҗпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
иҝҪжң¬жәҜжәҗвҖ”вҖ”е Ҷе’Ңж Ҳ
е ҶйҖҡеёёжҳҜдёҖдёӘеҸҜд»Ҙиў«зңӢеҒҡдёҖжЈөж ‘зҡ„ж•°з»„еҜ№иұЎпјҢж ҲжҳҜдёҖз§ҚеҸӘиғҪеңЁдёҖз«ҜиҝӣиЎҢжҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңзҡ„е…ҲиҝӣеҗҺеҮәзәҝжҖ§иЎЁпјҢJVMзҡ„жң¬иҙЁжҳҜе Ҷе’Ңж Ҳ
第дёҖпјҢд»ҺиҪҜ件и®ҫи®Ўзҡ„и§’еәҰзңӢпјҢж Ҳд»ЈиЎЁдәҶеӨ„зҗҶйҖ»иҫ‘пјҢиҖҢе Ҷд»ЈиЎЁдәҶж•°жҚ®гҖӮиҝҷж ·еҲҶејҖпјҢдҪҝеҫ—еӨ„зҗҶйҖ»иҫ‘жӣҙдёәжё…жҷ°гҖӮеҲҶиҖҢжІ»д№Ӣзҡ„жҖқжғігҖӮиҝҷз§Қйҡ”зҰ»гҖҒжЁЎеқ—еҢ–зҡ„жҖқжғіеңЁиҪҜ件и®ҫи®Ўзҡ„ж–№ж–№йқўйқўйғҪжңүдҪ“зҺ°гҖӮ
第дәҢпјҢе ҶдёҺж Ҳзҡ„еҲҶзҰ»пјҢдҪҝеҫ—е Ҷдёӯзҡ„еҶ…е®№еҸҜд»Ҙиў«еӨҡдёӘж Ҳе…ұдә«пјҲд№ҹеҸҜд»ҘзҗҶи§ЈдёәеӨҡдёӘзәҝзЁӢи®ҝй—®еҗҢдёҖдёӘеҜ№иұЎпјүгҖӮиҝҷз§Қе…ұдә«зҡ„收зӣҠжҳҜеҫҲеӨҡзҡ„гҖӮдёҖж–№йқўиҝҷз§Қе…ұдә«жҸҗдҫӣдәҶдёҖз§Қжңүж•Ҳзҡ„ж•°жҚ®дәӨдә’ж–№ејҸ(еҰӮпјҡе…ұдә«еҶ…еӯҳ)пјҢеҸҰдёҖж–№йқўпјҢе Ҷдёӯзҡ„е…ұдә«еёёйҮҸе’Ңзј“еӯҳеҸҜд»Ҙиў«жүҖжңүж Ҳи®ҝй—®пјҢиҠӮзңҒдәҶз©әй—ҙгҖӮ
第дёүпјҢж Ҳеӣ дёәиҝҗиЎҢж—¶зҡ„йңҖиҰҒпјҢжҜ”еҰӮдҝқеӯҳзі»з»ҹиҝҗиЎҢзҡ„дёҠдёӢж–ҮпјҢйңҖиҰҒиҝӣиЎҢең°еқҖж®өзҡ„еҲ’еҲҶгҖӮз”ұдәҺж ҲеҸӘиғҪеҗ‘дёҠеўһй•ҝпјҢеӣ жӯӨе°ұдјҡйҷҗеҲ¶дҪҸж ҲеӯҳеӮЁеҶ…е®№зҡ„иғҪеҠӣгҖӮиҖҢе ҶдёҚеҗҢпјҢе Ҷдёӯзҡ„еҜ№иұЎжҳҜеҸҜд»Ҙж №жҚ®йңҖиҰҒеҠЁжҖҒеўһй•ҝзҡ„пјҢеӣ жӯӨж Ҳе’Ңе Ҷзҡ„жӢҶеҲҶпјҢдҪҝеҫ—еҠЁжҖҒеўһй•ҝжҲҗдёәеҸҜиғҪпјҢзӣёеә”ж ҲдёӯеҸӘйңҖи®°еҪ•е Ҷдёӯзҡ„дёҖдёӘең°еқҖеҚіеҸҜгҖӮ
第еӣӣпјҢйқўеҗ‘еҜ№иұЎе°ұжҳҜе Ҷе’Ңж Ҳзҡ„е®ҢзҫҺз»“еҗҲгҖӮе…¶е®һпјҢйқўеҗ‘еҜ№иұЎж–№ејҸзҡ„зЁӢеәҸдёҺд»ҘеүҚз»“жһ„еҢ–зҡ„зЁӢеәҸеңЁжү§иЎҢдёҠжІЎжңүд»»дҪ•еҢәеҲ«гҖӮдҪҶжҳҜпјҢйқўеҗ‘еҜ№иұЎзҡ„еј•е…ҘпјҢдҪҝеҫ—еҜ№еҫ…й—®йўҳзҡ„жҖқиҖғж–№ејҸеҸ‘з”ҹдәҶж”№еҸҳпјҢиҖҢжӣҙжҺҘиҝ‘дәҺиҮӘ然方ејҸзҡ„жҖқиҖғгҖӮеҪ“жҲ‘们жҠҠеҜ№иұЎжӢҶејҖпјҢдҪ дјҡеҸ‘зҺ°пјҢеҜ№иұЎзҡ„еұһжҖ§е…¶е®һе°ұжҳҜж•°жҚ®пјҢеӯҳж”ҫеңЁе ҶдёӯпјӣиҖҢеҜ№иұЎзҡ„иЎҢдёәпјҲж–№жі•пјүпјҢе°ұжҳҜиҝҗиЎҢйҖ»иҫ‘пјҢж”ҫеңЁж ҲдёӯгҖӮжҲ‘们еңЁзј–еҶҷеҜ№иұЎзҡ„ж—¶еҖҷпјҢе…¶е®һеҚізј–еҶҷдәҶж•°жҚ®з»“жһ„пјҢд№ҹзј–еҶҷзҡ„еӨ„зҗҶж•°жҚ®зҡ„йҖ»иҫ‘гҖӮдёҚеҫ—дёҚжүҝи®ӨпјҢйқўеҗ‘еҜ№иұЎзҡ„и®ҫи®ЎпјҢзЎ®е®һеҫҲзҫҺгҖӮ
JVMиҝҗиЎҢжңәеҲ¶

жӯӨеӣҫзңӢеҮәjvmеҶ…еӯҳз»“жһ„
JVMеҶ…еӯҳз»“жһ„дё»иҰҒеҢ…жӢ¬дёӨдёӘеӯҗзі»з»ҹе’ҢдёӨдёӘ组件гҖӮдёӨдёӘеӯҗзі»з»ҹеҲҶеҲ«жҳҜClassloaderеӯҗзі»з»ҹе’ҢExecutionengine(жү§иЎҢеј•ж“Һ)еӯҗзі»з»ҹпјӣдёӨдёӘ组件еҲҶеҲ«жҳҜRuntimedataarea(иҝҗиЎҢж—¶ж•°жҚ®еҢәеҹҹ)组件е’ҢNativeinterface(жң¬ең°жҺҘеҸЈ)组件гҖӮ
Classloaderеӯҗзі»з»ҹзҡ„дҪңз”Ёпјҡж №жҚ®з»ҷе®ҡзҡ„е…Ёйҷҗе®ҡеҗҚзұ»еҗҚ(еҰӮjava.lang.Object)жқҘиЈ…иҪҪclassж–Ү件зҡ„еҶ…е®№еҲ°Runtimedataareaдёӯзҡ„methodarea(ж–№жі•еҢәеҹҹ)гҖӮJavaзЁӢеәҸе‘ҳеҸҜд»Ҙextendsjava.lang.ClassLoaderзұ»жқҘеҶҷиҮӘе·ұзҡ„ClassloaderгҖӮ
Executionengineеӯҗзі»з»ҹзҡ„дҪңз”Ёпјҡжү§иЎҢclassesдёӯзҡ„жҢҮд»ӨгҖӮд»»дҪ•JVMspecificationе®һзҺ°(JDK)зҡ„ж ёеҝғйғҪжҳҜExecutionengineпјҢдёҚеҗҢзҡ„JDKдҫӢеҰӮSunзҡ„JDKе’ҢIBMзҡ„JDKеҘҪеқҸдё»иҰҒе°ұеҸ–еҶідәҺ他们еҗ„иҮӘе®һзҺ°зҡ„Executionengineзҡ„еҘҪеқҸгҖӮ
Nativeinterface组件пјҡдёҺnativelibrariesдәӨдә’пјҢжҳҜе…¶е®ғзј–зЁӢиҜӯиЁҖдәӨдә’зҡ„жҺҘеҸЈгҖӮеҪ“и°ғз”Ёnativeж–№жі•зҡ„ж—¶еҖҷпјҢе°ұиҝӣе…ҘдәҶдёҖдёӘе…Ёж–°зҡ„并且дёҚеҶҚеҸ—иҷҡжӢҹжңәйҷҗеҲ¶зҡ„дё–з•ҢпјҢжүҖд»Ҙд№ҹеҫҲе®№жҳ“еҮәзҺ°JVMж— жі•жҺ§еҲ¶зҡ„nativeheapOutOfMemoryгҖӮ
RuntimeDataArea组件пјҡиҝҷе°ұжҳҜжҲ‘们常иҜҙзҡ„JVMзҡ„еҶ…еӯҳдәҶ
JVMзҡ„з”ҹе‘Ҫе‘Ёжңҹ
дёҖгҖҒйҰ–е…ҲеҲҶжһҗдёӨдёӘжҰӮеҝө
гҖҖгҖҖ JVMе®һдҫӢе’ҢJVMжү§иЎҢеј•ж“Һе®һдҫӢ
гҖҖгҖҖпјҲ1пјүJVMе®һдҫӢеҜ№еә”дәҶдёҖдёӘзӢ¬з«ӢиҝҗиЎҢзҡ„javaзЁӢеәҸпјҢе®ғжҳҜиҝӣзЁӢзә§еҲ«гҖӮ
гҖҖгҖҖпјҲ2пјүJVMжү§иЎҢеј•ж“Һе®һдҫӢеҲҷеҜ№еә”дәҶеұһдәҺз”ЁжҲ·иҝҗиЎҢзЁӢеәҸзҡ„зәҝзЁӢпјҢе®ғжҳҜзәҝзЁӢзә§еҲ«зҡ„гҖӮ
дәҢгҖҒJVMзҡ„з”ҹе‘Ҫе‘Ёжңҹ
гҖҖгҖҖпјҲ1пјүJVMе®һдҫӢзҡ„иҜһз”ҹпјҡеҪ“еҗҜеҠЁдёҖдёӘJavaзЁӢеәҸж—¶пјҢдёҖдёӘJVMе®һдҫӢе°ұдә§з”ҹдәҶпјҢд»»дҪ•дёҖдёӘжӢҘжңүpublic static void main(String[] args)еҮҪж•°зҡ„classйғҪеҸҜд»ҘдҪңдёәJVMе®һдҫӢиҝҗиЎҢзҡ„иө·зӮ№гҖӮ
гҖҖгҖҖпјҲ2пјүJVMе®һдҫӢзҡ„иҝҗиЎҢ main()дҪңдёәиҜҘзЁӢеәҸеҲқе§ӢзәҝзЁӢзҡ„иө·зӮ№пјҢд»»дҪ•е…¶д»–зәҝзЁӢеқҮз”ұиҜҘзәҝзЁӢеҗҜеҠЁгҖӮJVMеҶ…йғЁжңүдёӨз§ҚзәҝзЁӢпјҡе®ҲжҠӨзәҝзЁӢе’Ңйқһе®ҲжҠӨзәҝзЁӢпјҢmain()еұһдәҺйқһе®ҲжҠӨзәҝзЁӢпјҢе®ҲжҠӨзәҝзЁӢйҖҡеёёз”ұJVMиҮӘе·ұдҪҝз”ЁпјҢjavaзЁӢеәҸд№ҹеҸҜд»Ҙж ҮжҳҺиҮӘе·ұеҲӣе»әзҡ„зәҝзЁӢжҳҜе®ҲжҠӨзәҝзЁӢгҖӮ
гҖҖгҖҖпјҲ3пјүJVMе®һдҫӢзҡ„ж¶ҲдәЎпјҡеҪ“зЁӢеәҸдёӯзҡ„жүҖжңүйқһе®ҲжҠӨзәҝзЁӢйғҪз»Ҳжӯўж—¶пјҢJVMжүҚйҖҖеҮәпјӣиӢҘе®үе…Ёз®ЎзҗҶеҷЁе…Ғи®ёпјҢзЁӢеәҸд№ҹеҸҜд»ҘдҪҝз”ЁRuntimeзұ»жҲ–иҖ…System.exit()жқҘйҖҖеҮәгҖӮ
зұ»зҡ„з”ҹе‘Ҫ
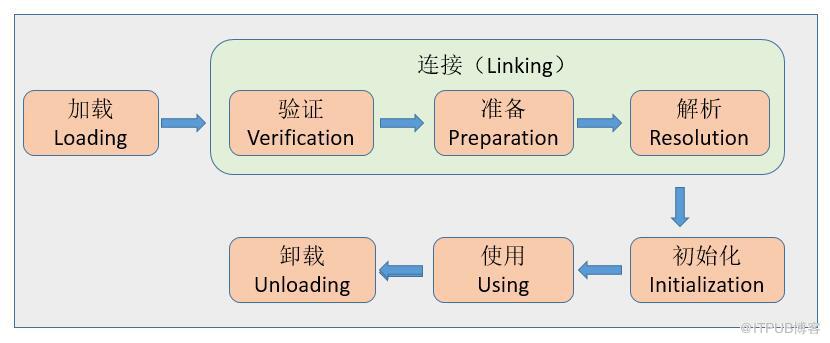
дёҖдёӘjavaзұ»зҡ„е®Ңж•ҙзҡ„з”ҹе‘Ҫе‘Ёжңҹдјҡз»ҸеҺҶеҠ иҪҪгҖҒиҝһжҺҘгҖҒеҲқе§ӢеҢ–гҖҒдҪҝз”ЁгҖҒе’ҢеҚёиҪҪдә”дёӘйҳ¶ж®өпјҢеҪ“然д№ҹжңүеңЁеҠ иҪҪжҲ–иҖ…иҝһжҺҘд№ӢеҗҺжІЎжңүиў«еҲқе§ӢеҢ–е°ұзӣҙжҺҘиў«дҪҝз”Ёзҡ„жғ…еҶө
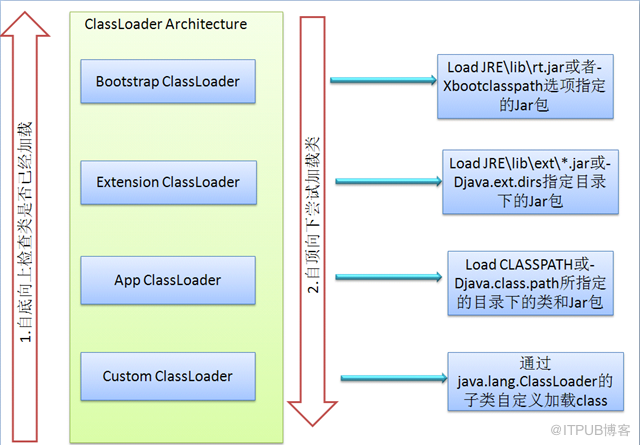
еҸҢдәІе§”жҙҫжЁЎеһӢжҳҜдёҖз§Қз»„з»Үзұ»еҠ иҪҪеҷЁд№Ӣй—ҙе…ізі»зҡ„дёҖз§Қ规иҢғ,д»–зҡ„е·ҘдҪңеҺҹзҗҶжҳҜ:еҰӮжһңдёҖдёӘзұ»еҠ иҪҪеҷЁж”¶еҲ°дәҶзұ»еҠ иҪҪзҡ„иҜ·жұӮ,е®ғдёҚдјҡиҮӘе·ұеҺ»е°қиҜ•еҠ иҪҪиҝҷдёӘзұ»,иҖҢжҳҜжҠҠиҝҷдёӘиҜ·жұӮ委жҙҫз»ҷзҲ¶зұ»еҠ иҪҪеҷЁеҺ»е®ҢжҲҗ,иҝҷж ·еұӮеұӮйҖ’иҝӣ,жңҖз»ҲжүҖжңүзҡ„еҠ иҪҪиҜ·жұӮйғҪиў«дј еҲ°жңҖйЎ¶еұӮзҡ„еҗҜеҠЁзұ»еҠ иҪҪеҷЁдёӯ,еҸӘжңүеҪ“зҲ¶зұ»еҠ иҪҪеҷЁж— жі•е®ҢжҲҗиҝҷдёӘеҠ иҪҪиҜ·жұӮ(е®ғзҡ„жҗңзҙўиҢғеӣҙеҶ…жІЎжңүжүҫеҲ°жүҖйңҖзҡ„зұ»)ж—¶,жүҚдјҡдәӨз»ҷеӯҗзұ»еҠ иҪҪеҷЁеҺ»е°қиҜ•еҠ иҪҪ.
и®ӨиҜҶJVMеҶ…еӯҳжЁЎеһӢ
еҜ№дәҺJVMеҶ…еӯҳпјҢзЁӢеәҸе‘ҳеҸӘйңҖиҰҒе…іжіЁ
еҜ№иұЎеҺ»е“Әе„ҝвҖ”вҖ”е ҶеҶ…еӯҳ(еҢ…жӢ¬ж–°з”ҹд»Је’ҢиҖҒе№ҙд»ЈпјҢж–°з”ҹд»ЈеҸҲеҲҶдёәEndenеҢәе’ҢдёӨдёӘSurvivorеҢә)пјҢе ҶеҶ…еӯҳз”ЁдәҺеӯҳж”ҫеҜ№иұЎпјҢеҗҲзҗҶеҲҶеҢәдё»иҰҒжҳҜдёәдәҶжҸҗй«ҳеһғеңҫеӣһ收ж•ҲзҺҮпјҢж–°еҲӣе»әзҡ„еҜ№иұЎдјҡеңЁEndenеҢәпјҢз»ҸеҺҶMinor GCеҗҺдјҡеҲ°SurvivorеҢәпјҢз»ҸеҺҶдёҖиҲ¬15ж¬ЎGCиҝҳеӯҳжҙ»зҡ„иҜқдјҡиҝӣе…ҘиҖҒе№ҙд»ЈгҖӮ
еҮҪж•°еҰӮдҪ•и°ғз”ЁвҖ”вҖ”ж ҲеҶ…еӯҳз”ЁдәҺиҝҗиЎҢзәҝзЁӢпјҢе®ғ们еҢ…еҗ«дәҶж–№жі•йҮҢзҡ„дёҙж—¶ж•°жҚ®гҖҒе ҶйҮҢе…¶е®ғеҜ№иұЎеј•з”Ёзҡ„зү№е®ҡж•°жҚ®гҖӮ
зұ»еҺ»е“Әе„ҝвҖ”вҖ”ж–№жі•еҢәз”ЁжқҘеӯҳеӮЁзұ»еһӢдҝЎжҒҜпјҲиҝҗиЎҢж—¶еёёйҮҸе’ҢйқҷжҖҒеҸҳйҮҸпјүе’Ңж–№жі•д»Јз Ғе’Ңжһ„йҖ еҮҪж•°д»Јз ҒпјҢйҖҡеёёд№ҹеҸ«ж°ёд№…д»ЈпјҢJDK8з”Ёе…ғз©әй—ҙд»Јжӣҝж°ёд№…д»Ј
JVMиө„жәҗдёҖиҲ¬еҲҶдёәдёӨз§ҚCPUе’ҢеҶ…еӯҳпјҢCPUд»ЈиЎЁзқҖзәҝзЁӢж ҲпјҢеҶ…еӯҳд»ЈиЎЁзқҖе ҶпјҢиҖҢеҫҖеҫҖз”ҹдә§зҺҜеўғJVMй—®йўҳдёҖиҲ¬йғҪжҳҜиҝҷдёӨз§Қиө„жәҗдёҚи¶іеҜјиҮҙзҡ„пјҢеҪ“зәҝзЁӢж ҲдҪҝз”ЁдёҚеҪ“зҡ„ж—¶еҖҷпјҢйҖҡеёёдјҡCPUзҲҶж»ЎпјҢеҪ“е ҶеҶ…еӯҳдҪҝз”ЁдёҚеҪ“зҡ„ж—¶еҖҷпјҢйҖҡеёёдјҡеҮәзҺ°еҶ…еӯҳжәўеҮәгҖӮ
еҶ…еӯҳз®ЎзҗҶжё…жҙҒе·ҘвҖ”вҖ”еһғеңҫеӣһ收
JavaзЁӢеәҸиҜӯиЁҖдёӯзҡ„дёҖдёӘжңҖеӨ§дјҳзӮ№жҳҜиҮӘеҠЁеһғеңҫеӣһ收пјҢJavaеһғеңҫеӣһ收дјҡжүҫеҮәжІЎз”Ёзҡ„еҜ№иұЎпјҢжҠҠе®ғд»ҺеҶ…еӯҳдёӯ移йҷӨ并йҮҠж”ҫеҮәеҶ…еӯҳз»ҷд»ҘеҗҺеҲӣе»әзҡ„еҜ№иұЎдҪҝз”ЁгҖӮдёӢйқўеӣҫзүҮз”ҹеҠЁеҜ№жҜ”жүӢеҠЁеһғеңҫеӣһ收е’ҢиҮӘеҠЁеһғеңҫеӣһ收зҡ„еҢәеҲ«гҖӮеһғеңҫеӣһ收йҮҚзӮ№е…іжіЁзўҺзүҮе’ҢжҖ§иғҪгҖӮ
еҲқиҜҶеһғеңҫеӣһ收算法
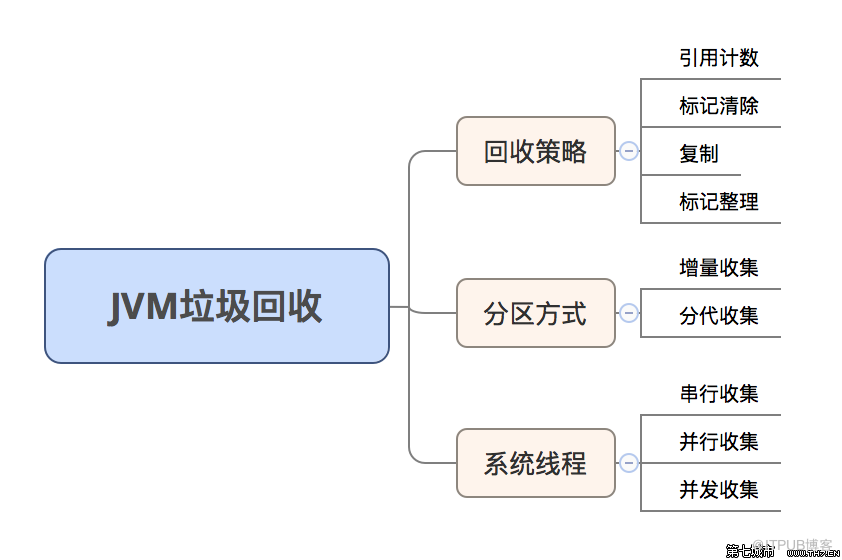
жҢүеӣһ收зӯ–з•Ҙ
(1).еј•з”Ёи®Ўж•°з®—жі•пјҡ
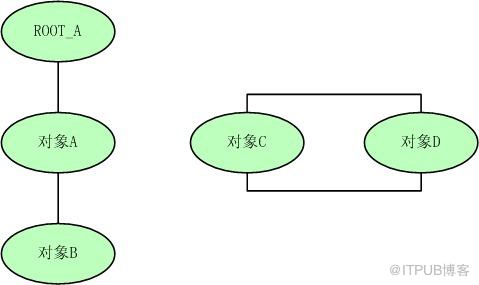
з»ҷеҜ№иұЎдёӯж·»еҠ дёҖдёӘеј•з”Ёи®Ўж•°еҷЁпјҢжҜҸеҪ“жңүдёҖдёӘең°ж–№еј•з”Ёе®ғж—¶пјҢи®Ўж•°еҷЁеҖје°ұеҠ 1пјӣеҪ“еј•з”ЁеӨұж•Ҳж—¶пјҢи®Ўж•°еҷЁеҖје°ұеҮҸ1пјӣд»»дҪ•ж—¶еҲ»и®Ўж•°еҷЁйғҪдёә0зҡ„еҜ№иұЎе°ұжҳҜдёҚеҶҚиў«дҪҝз”Ёзҡ„пјҢеһғеңҫ收йӣҶеҷЁе°Ҷеӣһ收иҜҘеҜ№иұЎдҪҝз”Ёзҡ„еҶ…еӯҳгҖӮеј•з”Ёи®Ўж•°з®—жі•е®һзҺ°з®ҖеҚ•пјҢж•ҲзҺҮеҫҲй«ҳпјҢеҫ®иҪҜзҡ„COMжҠҖжңҜгҖҒActionScriptгҖҒPythonзӯүйғҪдҪҝз”ЁдәҶеј•з”Ёи®Ўж•°з®—жі•иҝӣиЎҢеҶ…еӯҳз®ЎзҗҶпјҢдҪҶжҳҜеј•з”Ёи®Ўж•°з®—жі•еҜ№дәҺеҜ№иұЎд№Ӣй—ҙзӣёдә’еҫӘзҺҜеј•з”Ёй—®йўҳйҡҫд»Ҙи§ЈеҶіпјҢеӣ жӯӨjava并没жңүдҪҝз”Ёеј•з”Ёи®Ўж•°з®—жі•гҖӮ
(2).ж №жҗңзҙўз®—жі•пјҡ
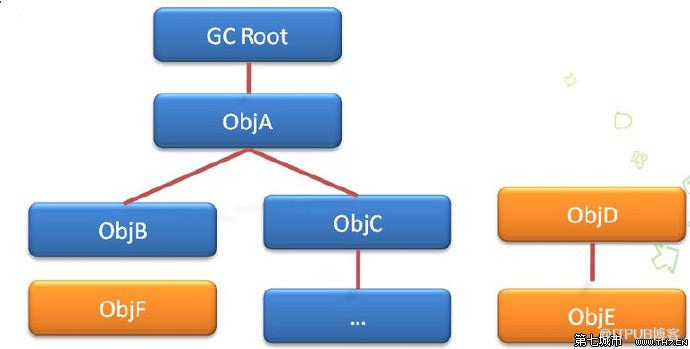
йҖҡиҝҮдёҖзі»еҲ—зҡ„еҗҚдёәвҖңGC RootвҖқзҡ„еҜ№иұЎдҪңдёәиө·зӮ№пјҢд»ҺиҝҷдәӣиҠӮзӮ№еҗ‘дёӢжҗңзҙўпјҢжҗңзҙўжүҖиө°иҝҮзҡ„и·Ҝеҫ„з§°дёәеј•з”Ёй“ҫ(Reference Chain)пјҢеҪ“дёҖдёӘеҜ№иұЎеҲ°GC RootжІЎжңүд»»дҪ•еј•з”Ёй“ҫзӣёиҝһж—¶пјҢеҲҷиҜҘеҜ№иұЎдёҚеҸҜиҫҫпјҢиҜҘеҜ№иұЎжҳҜдёҚеҸҜдҪҝз”Ёзҡ„пјҢеһғеңҫ收йӣҶеҷЁе°Ҷеӣһ收其жүҖеҚ зҡ„еҶ…еӯҳгҖӮ
еңЁJavaиҜӯиЁҖйҮҢпјҢеҸҜдҪңдёәGC RootsеҜ№иұЎзҡ„еҢ…жӢ¬еҰӮдёӢеҮ з§Қпјҡ
a.System Class,еғҸrt.jarйҮҢйқўзҡ„java.util.*
b.Thread,ејҖе§ӢзҠ¶жҖҒзҡ„зәҝзЁӢ
c.иҷҡжӢҹжңәж Ҳ(ж ҲжЎўдёӯзҡ„жң¬ең°еҸҳйҮҸиЎЁ)дёӯзҡ„еј•з”Ёзҡ„еҜ№иұЎ
d.ж–№жі•еҢәдёӯзҡ„зұ»йқҷжҖҒеұһжҖ§еј•з”Ёзҡ„еҜ№иұЎ
e.ж–№жі•еҢәдёӯзҡ„еёёйҮҸеј•з”Ёзҡ„еҜ№иұЎ
f.жң¬ең°ж–№жі•ж ҲдёӯJNIзҡ„еј•з”Ёзҡ„еҜ№иұЎ
(3).ж Үи®°-жё…йҷӨз®—жі•пјҡ
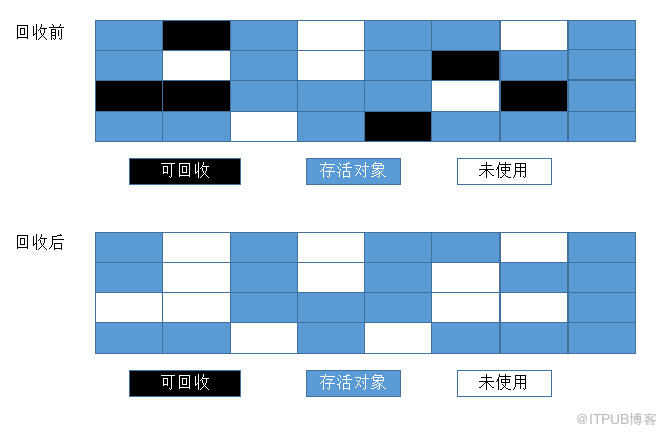
жңҖеҹәзЎҖзҡ„еһғеңҫ收йӣҶз®—жі•пјҢз®—жі•еҲҶдёәвҖңж Үи®°вҖқе’ҢвҖңжё…йҷӨвҖқдёӨдёӘйҳ¶ж®өпјҡйҰ–е…Ҳж Үи®°еҮәжүҖжңүйңҖиҰҒеӣһ收зҡ„еҜ№иұЎпјҢеңЁж Үи®°е®ҢжҲҗд№ӢеҗҺз»ҹдёҖеӣһ收жҺүжүҖжңүиў«ж Үи®°зҡ„еҜ№иұЎгҖӮ
ж Үи®°-жё…йҷӨз®—жі•зҡ„зјәзӮ№жңүдёӨдёӘпјҡйҰ–е…ҲпјҢж•ҲзҺҮй—®йўҳпјҢж Үи®°е’Ңжё…йҷӨж•ҲзҺҮйғҪдёҚй«ҳгҖӮе…¶ж¬ЎпјҢж Үи®°жё…йҷӨд№ӢеҗҺдјҡдә§з”ҹеӨ§йҮҸзҡ„дёҚиҝһз»ӯзҡ„еҶ…еӯҳзўҺзүҮпјҢз©әй—ҙзўҺзүҮеӨӘеӨҡдјҡеҜјиҮҙеҪ“зЁӢеәҸйңҖиҰҒдёәиҫғеӨ§еҜ№иұЎеҲҶй…ҚеҶ…еӯҳж—¶ж— жі•жүҫеҲ°и¶іеӨҹзҡ„иҝһз»ӯеҶ…еӯҳиҖҢдёҚеҫ—дёҚжҸҗеүҚи§ҰеҸ‘еҸҰдёҖж¬Ўеһғеңҫ收йӣҶеҠЁдҪңгҖӮ
(4).еӨҚеҲ¶з®—жі•пјҡ

е°ҶеҸҜз”ЁеҶ…еӯҳжҢүе®№йҮҸеҲҶжҲҗеӨ§е°Ҹзӣёзӯүзҡ„дёӨеқ—пјҢжҜҸж¬ЎеҸӘдҪҝз”Ёе…¶дёӯдёҖеқ—пјҢеҪ“иҝҷеқ—еҶ…еӯҳдҪҝз”Ёе®ҢдәҶпјҢе°ұе°Ҷиҝҳеӯҳжҙ»зҡ„еҜ№иұЎеӨҚеҲ¶еҲ°еҸҰдёҖеқ—еҶ…еӯҳдёҠеҺ»пјҢ然еҗҺжҠҠдҪҝз”ЁиҝҮзҡ„еҶ…еӯҳз©әй—ҙдёҖж¬Ўжё…зҗҶжҺүгҖӮиҝҷж ·дҪҝеҫ—жҜҸж¬ЎйғҪжҳҜеҜ№е…¶дёӯдёҖеқ—еҶ…еӯҳиҝӣиЎҢеӣһ收пјҢеҶ…еӯҳеҲҶй…Қж—¶дёҚз”ЁиҖғиҷ‘еҶ…еӯҳзўҺзүҮзӯүеӨҚжқӮжғ…еҶөпјҢеҸӘйңҖиҰҒ移еҠЁе ҶйЎ¶жҢҮй’ҲпјҢжҢүйЎәеәҸеҲҶй…ҚеҶ…еӯҳеҚіеҸҜпјҢе®һзҺ°з®ҖеҚ•пјҢиҝҗиЎҢй«ҳж•ҲгҖӮ
еӨҚеҲ¶з®—жі•зҡ„зјәзӮ№жҳҫиҖҢжҳ“и§ҒпјҢеҸҜдҪҝз”Ёзҡ„еҶ…еӯҳйҷҚдёәеҺҹжқҘдёҖеҚҠгҖӮ
(5).ж Үи®°-жё…йҷӨ-ж•ҙзҗҶз®—жі•пјҡ
ж Үи®°-ж•ҙзҗҶз®—жі•еңЁж Үи®°-жё…йҷӨз®—жі•еҹәзЎҖдёҠеҒҡдәҶж”№иҝӣпјҢж Үи®°йҳ¶ж®өжҳҜзӣёеҗҢзҡ„ж Үи®°еҮәжүҖжңүйңҖиҰҒеӣһ收зҡ„еҜ№иұЎпјҢеңЁж Үи®°е®ҢжҲҗд№ӢеҗҺдёҚжҳҜзӣҙжҺҘеҜ№еҸҜеӣһ收еҜ№иұЎиҝӣиЎҢжё…зҗҶпјҢиҖҢжҳҜи®©жүҖжңүеӯҳжҙ»зҡ„еҜ№иұЎйғҪеҗ‘дёҖз«Ҝ移еҠЁпјҢеңЁз§»еҠЁиҝҮзЁӢдёӯжё…зҗҶжҺүеҸҜеӣһ收зҡ„еҜ№иұЎпјҢиҝҷдёӘиҝҮзЁӢеҸ«еҒҡж•ҙзҗҶгҖӮ
ж Үи®°-ж•ҙзҗҶз®—жі•зӣёжҜ”ж Үи®°-жё…йҷӨз®—жі•зҡ„дјҳзӮ№жҳҜеҶ…еӯҳиў«ж•ҙзҗҶд»ҘеҗҺдёҚдјҡдә§з”ҹеӨ§йҮҸдёҚиҝһз»ӯеҶ…еӯҳзўҺзүҮй—®йўҳгҖӮ
еӨҚеҲ¶з®—жі•еңЁеҜ№иұЎеӯҳжҙ»зҺҮй«ҳзҡ„жғ…еҶөдёӢе°ұиҰҒжү§иЎҢиҫғеӨҡзҡ„еӨҚеҲ¶ж“ҚдҪңпјҢж•ҲзҺҮе°ҶдјҡеҸҳдҪҺпјҢиҖҢеңЁеҜ№иұЎеӯҳжҙ»зҺҮй«ҳзҡ„жғ…еҶөдёӢдҪҝз”Ёж Үи®°-ж•ҙзҗҶз®—жі•ж•ҲзҺҮдјҡеӨ§еӨ§жҸҗй«ҳгҖӮ
жҢүеҲҶеҢәеӣһ收
(1).еҲҶд»Јз®—жі•пјҡ
ж №жҚ®еҜ№иұЎзҡ„еӯҳжҙ»е‘Ёжңҹзҡ„дёҚеҗҢе°ҶеҶ…еӯҳеҲ’еҲҶдёәеҮ еқ—гҖӮдёҖиҲ¬жҠҠjavaе ҶеҲҶдёәж–°з”ҹд»Је’ҢиҖҒе№ҙд»ЈпјҢиҝҷж ·е°ұеҸҜд»Ҙж №жҚ®еҗ„дёӘе№ҙд»Јзҡ„зү№зӮ№йҮҮз”ЁжңҖйҖӮеҪ“зҡ„收йӣҶз®—жі•гҖӮеңЁж–°з”ҹд»ЈпјҢжҜҸж¬Ўеһғеңҫ收йӣҶж—¶йғҪеҸ‘зҺ°жңүеӨ§жү№еҜ№иұЎжӯ»еҺ»пјҢеҸӘжңүе°‘йҮҸеӯҳжҙ»пјҢйӮЈе°ұйҖүз”ЁеӨҚеҲ¶з®—жі•пјҢеҸӘйңҖиҰҒд»ҳеҮәе°‘йҮҸеӯҳжҙ»еҜ№иұЎзҡ„еӨҚеҲ¶жҲҗжң¬е°ұеҸҜд»Ҙе®ҢжҲҗ收йӣҶгҖӮиҖҢиҖҒе№ҙд»Јдёӯеӣ дёәеҜ№иұЎеӯҳжҙ»зҺҮй«ҳгҖҒжІЎжңүйўқеӨ–з©әй—ҙеҜ№д»–иҝӣиЎҢеҲҶй…ҚжӢ…дҝқпјҢе°ұеҝ…йЎ»дҪҝз”ЁвҖңж Үи®°-ж•ҙзҗҶвҖқз®—жі•иҝӣиЎҢеӣһ收гҖӮ
жҢүзі»з»ҹзәҝзЁӢ
дёІиЎҢ/并иЎҢеӣһ收方ејҸпјҡеңЁGCиҝҮзЁӢдёӯпјҢеҚ•зәҝзЁӢ/еӨҡзәҝзЁӢ收йӣҶеҷЁйҮҮз”ЁStop-the-WorldжңәеҲ¶пјҢеҒҡдәӢдё“дёҖеҗһеҗҗйҮҸй«ҳпјӣ
并еҸ‘еӣһ收пјҡе·ҘдҪңзәҝзЁӢе’Ңеһғеңҫеӣһ收зәҝзЁӢ并еҸ‘жү§иЎҢпјҢдёҖеҝғдәҢз”ЁпјҢеҗһеҗҗйҮҸиҫғдҪҺпјҢдёҚиҝҮдҝқиҜҒеңЁGCзҡ„ж—¶еҖҷпјҢе…¶е®ғз”ЁжҲ·зәҝзЁӢеҸҜд»Ҙе·ҘдҪңпјӣ
еһғеңҫ收йӣҶеҷЁ
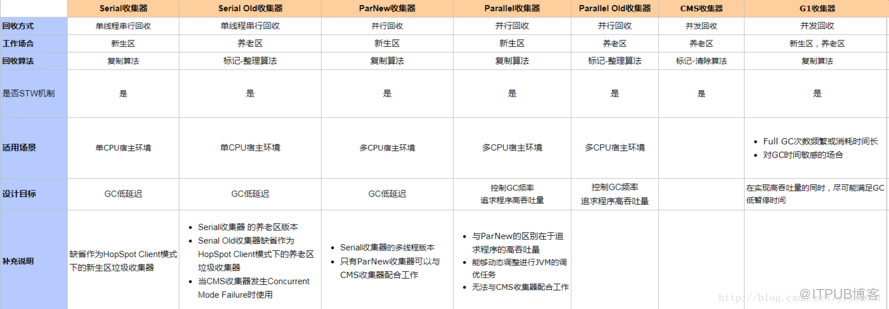
JVMеёёи§ҒеҸӮж•°
жңҖеҗҺжұҮжҖ»дёҖдёӢJVMеёёи§Ғй…ҚзҪ®
зұ»еҠ иҪҪи®ҫзҪ®
-XX:+TraceClassLoading:зұ»еҠ иҪҪж—Ҙеҝ—
-XX:+TraceClassUnloading:зұ»еҚёиҪҪж—Ҙеҝ—
е Ҷи®ҫзҪ®
-Xms:еҲқе§Ӣе ҶеӨ§е°Ҹ
-Xmx:жңҖеӨ§е ҶеӨ§е°Ҹ
-XX:NewSize=n:и®ҫзҪ®е№ҙиҪ»д»ЈеӨ§е°Ҹ
-XX:NewRatio=n:и®ҫзҪ®е№ҙиҪ»д»Је’Ңе№ҙиҖҒд»Јзҡ„жҜ”еҖјгҖӮеҰӮ:дёә3пјҢиЎЁзӨәе№ҙиҪ»д»ЈдёҺе№ҙиҖҒд»ЈжҜ”еҖјдёә1пјҡ3пјҢе№ҙиҪ»д»ЈеҚ ж•ҙдёӘе№ҙиҪ»д»Је№ҙиҖҒд»Је’Ңзҡ„1/4
-XX:SurvivorRatio=n:е№ҙиҪ»д»ЈдёӯEdenеҢәдёҺдёӨдёӘSurvivorеҢәзҡ„жҜ”еҖјгҖӮжіЁж„ҸSurvivorеҢәжңүдёӨдёӘгҖӮеҰӮпјҡ3пјҢиЎЁзӨәEdenпјҡSurvivor=3пјҡ2пјҢдёҖдёӘSurvivorеҢәеҚ ж•ҙдёӘе№ҙиҪ»д»Јзҡ„1/5
-XX:MaxPermSize=n:и®ҫзҪ®жҢҒд№…д»ЈеӨ§е°Ҹ
收йӣҶеҷЁи®ҫзҪ®
-XX:+UseSerialGC:и®ҫзҪ®дёІиЎҢ收йӣҶеҷЁ
-XX:+UseParallelGC:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁ
-XX:+UseParalledlOldGC:и®ҫзҪ®е№¶иЎҢе№ҙиҖҒ代收йӣҶ
-XX:+UseConcMarkSweepGC:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁ
еһғеңҫеӣһ收з»ҹи®ЎдҝЎжҒҜ
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
并иЎҢ收йӣҶеҷЁи®ҫзҪ®
-XX:ParallelGCThreads=n:и®ҫзҪ®е№¶иЎҢ收йӣҶеҷЁж”¶йӣҶж—¶дҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
-XX:MaxGCPauseMillis=n:и®ҫзҪ®е№¶иЎҢ收йӣҶжңҖеӨ§жҡӮеҒңж—¶й—ҙ
-XX:GCTimeRatio=n:и®ҫзҪ®еһғеңҫеӣһ收时й—ҙеҚ зЁӢеәҸиҝҗиЎҢж—¶й—ҙзҡ„зҷҫеҲҶжҜ”гҖӮе…¬ејҸдёә1/(1+n)
并еҸ‘收йӣҶеҷЁи®ҫзҪ®
-XX:+CMSIncrementalMode:и®ҫзҪ®дёәеўһйҮҸжЁЎејҸгҖӮйҖӮз”ЁдәҺеҚ•CPUжғ…еҶө
-XX:ParallelGCThreads=n:и®ҫзҪ®е№¶еҸ‘收йӣҶеҷЁе№ҙиҪ»д»Јж”¶йӣҶж–№ејҸдёә并иЎҢ收йӣҶж—¶пјҢдҪҝз”Ёзҡ„CPUж•°гҖӮ并иЎҢ收йӣҶзәҝзЁӢж•°гҖӮ
д»ҘдёҠжҳҜвҖңJVMзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ





