小编给大家分享一下如何使用Selenium爬取豆瓣电影前100的爱情片,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
Selenium是一个用于测试网站的自动化测试工具,支持各种浏览器包括Chrome、Firefox、Safari等主流界面浏览器,同时也支持phantomJS无界面浏览器。
由于Selenium的环境配置过程比较繁琐,我会尽可能详细的对其进行讲解。
由于Selenium的环境配置过程比较繁琐,我会多花一些篇幅对其进行讲解。可以在cmd命令框输入以下内容安装Selenium库。
pip install Selenium
Selenium的使用必须有相应浏览器的webdriver,以Chrome浏览器为例,可以在这个链接查看自己的浏览器对应的Chromedriver的版本。
设置浏览器的地址非常简单。 我们可以手动创建一个存放浏览器驱动的目录, , 将下载的浏览器驱动文件丢到该目录下。然后在我的电脑–>属性–>系统设置–>高级–>环境变量–>系统变量–>Path,将该目录添加到Path的值中。如果配置变量有问题,可以参照这个链接
注意,如果系统报错为:
selenium.common.exceptions.SessionNotCreatedException: Message: session not created:This version of ChromeDriver only supports Chrome version***
表示当前下载的Chromedriver的版本与自己浏览器的版本无法对应,可以通过Chrome的帮助查看自己的浏览器版本

接下来就可以测试我们的selenium是不是可以正常使用了,以一个简单的例子开始:驱动浏览器打开百度。
from selenium import webdriver url='https://www.baidu.com/' browser=webdriver.Chrome() browser.get(url)
如果到这里都没有问题的话,就已经可以开始进行下一步了。
首先导入本次爬虫任务需要的相关库:
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.desired_capabilities import DesiredCapabilities import time
其中selenium.webdriver.common.by 主要用于搜寻网页元素的id信息,用于定位按钮、输入框之类的元素,WebDriverWait主要是用于等待网页响应完成,因为网页没有完全加载,就使用find_elements_by_**等方法,就会出现找不到对应元素的情况。
movies=browser.find_elements_by_class_name('movie-name-text')
names=[]
for item in movies:
if item.text!='':
names.append(item.text)其中find_elements_by_class_name就是通过查找class_name来锁定影片名称这个信息。
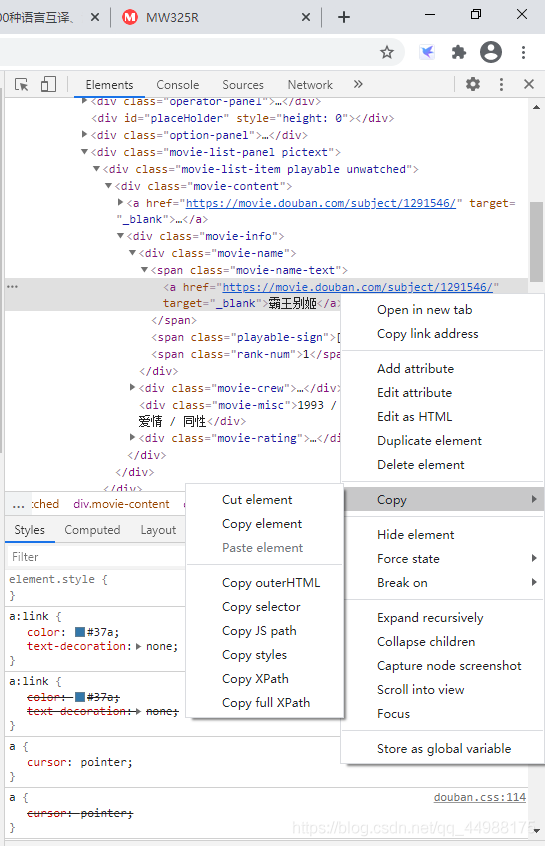
审查元素后右键即可Copy这个元素的JS path,selector等信息,可以锁定这个元素及其类似的其他元素的信息。以‘霸王别姬'这部影片为例,他的selector就是#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(1) > div > div > div.movie-name > span.movie-name-text > a那么就可以用下面的代码来锁定影片名称。
movies=browser.find_elements_by_class_name('#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(1) > div > div > div.movie-name > span.movie-name-text > a')前面已经说过,如果页面还没有完全加载出,我们就进行元素的查找,返回的很可能是空列表,所以我们需要设置等待时间。
这里就涉及到显示等待和隐式等待的区别。
2.3.1 显式等待
每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常(TimeoutException)代码格式:WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
2.3.2 隐式等待
隐式等待是通过一定的时长等待页面上某个元素加载完成。如果超出了设置的时长元素还没有被加载,则抛出NoSuchElementException异常。
操作如下:implicitly_wait()
当使用了隐式等待执行测试的时候,如果 WebDriver没有在 DOM中找到元素,将继续等待,超出设定时间后则抛出找不到元素的异常换句话说,当查找元素或元素并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是0,一旦设置了隐式等待,则它存在整个 WebDriver 对象实例的声明周期中,隐式的等到会让一个正常响应的应用的测试变慢,它将会在寻找每个元素的时候都进行等待,这样会增加整个测试执行的时间。我们这里使用的就是隐式等待。
def get_page():
browser.implicitly_wait(10)
for i in range(50):
time.sleep(0.3)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
print('正在下滑第{}次'.format(i))
print('-------------')
#time.sleep(10)
print("*****请等待几秒*****")
time.sleep(10)
when=wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(380) > div > a > img')))2.3.3 强制等待(补充)
强制等待就是使用python自带的time模块,设置等待时间,操作如下:time.sleep(time)一般可以用强制等待来限制计算机频繁访问目标链接导致验证问题。
页面下滑过程比较简单,不多赘述。其实现过程如下:
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')#下滑操作爬取出的数据是列表形式,使用pandas的to_csv方法就可以保存到本地了。
rate,miscs,actor_list,ranks,playable_sign,names=get_page()
datas=pd.DataFrame({'names':names,'rank':ranks,'分类':miscs,'评分':rate})
try:
datas.to_csv('机器学习\爬虫\douban_0327.csv',encoding='utf_8_sig')
print("保存成功")
print(datas)from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import pandas as pd
import time
url='https://movie.douban.com/typerank?type_name=爱情片&type=13&interval_id=100:90&action='
options=webdriver.ChromeOptions()
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('user-agent="Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"')
browser=webdriver.Chrome()
browser.get(url)
wait=WebDriverWait(browser,10)
def get_page():
browser.implicitly_wait(10)
for i in range(50):
time.sleep(0.3)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')#下滑操作
print('正在下滑第{}次'.format(i))
print('-------------')
#time.sleep(10)
print("*****请等待几秒*****")
time.sleep(10)
when=wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'#content > div > div.article > div.movie-list-panel.pictext > div:nth-child(380) > div > a > img')))
#-----------------------------------------------------------------
movies=browser.find_elements_by_class_name('movie-name-text')
names=[]
for item in movies:
if item.text!='':
names.append(item.text)
print("爬取成功")
print(len(names))
#---------------------------------------------------------------
playables=browser.find_elements_by_class_name('playable-sign')
playable_sign=[]
for sign in playables:
if sign.text!='':
playable_sign.append(sign.text)
print('爬取成功')
print(len(playable_sign))
#------------------------------------------------------------
rank_names=browser.find_elements_by_class_name('rank-num')
ranks=[]
for rank in rank_names:
if rank.text!='':
ranks.append(rank.text)
print('爬取成功')
print(len(ranks))
#---------------------------------------------------------
actors=browser.find_elements_by_class_name('movie-crew')
actor_list=[]
for actor in actors:
if actor.text!='':
actor_list.append(actor.text)
print('爬取成功')
print(len(actor_list))
#----------------------------------------------------------
clasic=browser.find_elements_by_class_name('movie-misc')
miscs=[]
for misc in clasic:
if misc.text!='':
miscs.append(misc.text)
print('爬取成功')
print(len(miscs))
#-----------------------------------------------------------
rates=browser.find_elements_by_class_name('movie-rating')
rate=[]
for score in rates:
if score.text!='':
rate.append(score.text)
print('爬取成功')
print(len(rate))
#-----------------------------------------------------------
'''
links=browser.find_elements_by_class_name('movie-content')
for link in links:
link_img=link.get_attribute('data-original')
print(link_img)
'''
return rate,miscs,actor_list,ranks,playable_sign,names
if __name__ == "__main__":
rate,miscs,actor_list,ranks,playable_sign,names=get_page()
datas=pd.DataFrame({'names':names,'rank':ranks,'分类':miscs,'评分':rate})
try:
datas.to_csv('机器学习\爬虫\douban_0327.csv',encoding='utf_8_sig')
print("保存成功")
print(datas)
except:
print('保存失败')以上是“如何使用Selenium爬取豆瓣电影前100的爱情片”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





