1、适用场景:
一张表很大,一张表很小
2、解决方案:
在map端缓存多张表,提前处理业务逻辑,这样增加map端业务,减少reduce端的数据压力,尽可能减少数据倾斜。
3、具体方法:采用分布式缓存
(1)在mapper的setup阶段,将文件读取到缓存集合中
(2)在driver中加载缓存,job.addCacheFile(new URI("file:/e:/mapjoincache/pd.txt"));// 缓存普通文件到task运行节点。
4、实例
//order.txt
订单id 商品id 商品数量
1001 01 1
1002 02 2
1003 03 3
1004 01 4
1005 02 5
1006 03 6
//pd.txt
商品id 商品名
01 小米
02 华为
03 格力要将order中的商品id替换为商品名称,缓存 pd.txt 这个小表
mapper:
package MapJoin;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
Map<String, String> productMap = new HashMap<String, String>();
Text k = new Text();
/**
*
* 将 pd.txt加载到hashmap中,只加载一次
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void setup(Context context) throws IOException, InterruptedException {
BufferedReader productReader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("G:\\test\\A\\mapjoin\\pd.txt"))));
String line;
while (StringUtils.isNotEmpty(line = productReader.readLine())) {
String[] fields = line.split("\t");
productMap.put(fields[0], fields[1]);
}
productReader.close();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
String productName = productMap.get(fields[1]);
k.set(fields[0] + "\t" + productName + "\t" + fields[2]);
context.write(k, NullWritable.get());
}
@Override
protected void cleanup(Context context) throws IOException, InterruptedException {
super.cleanup(context);
}
}driver:
package MapJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class MapJoinDriver {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException {
args = new String[]{"G:\\test\\A\\mapjoin\\order.txt", "G:\\test\\A\\mapjoin\\join2\\"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MapJoinDriver.class);
job.setMapperClass(MapJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//将重复使用的小文件加载到缓存中
job.addCacheFile(new URI("file:///G:/test/A/mapjoin/pd.txt"));
job.setNumReduceTasks(0);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
1、分析思路
通过将关联条件作为map的输出的key,也就是使用商品ID来作为key,将两表满足join条件的数据并携带数据所来源的文件信息,发往同一个reduce task,在reduce中进行数据的串联
输入的数据和上面的map join一样,输出的结果也和上面的类似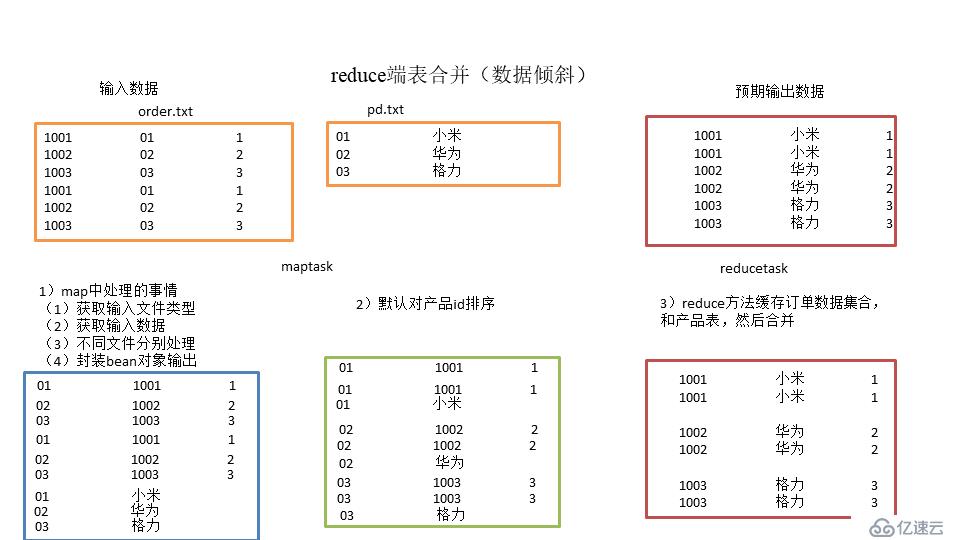
bean:
package ReduceJoin;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
public class OrderBean implements Writable {
private String orderID;
private String productID;
private int amount;
private String productName;
private String flag;
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(this.orderID);
dataOutput.writeUTF(this.productID);
dataOutput.writeInt(this.amount);
dataOutput.writeUTF(this.productName);
dataOutput.writeUTF(this.flag);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.orderID = dataInput.readUTF();
this.productID = dataInput.readUTF();
this.amount = dataInput.readInt();
this.productName = dataInput.readUTF();
this.flag = dataInput.readUTF();
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append(this.orderID);
sb.append("\t");
sb.append(this.productName);
sb.append("\t");
sb.append(this.amount);
sb.append("\t");
sb.append(this.flag);
return sb.toString();
}
}
map:
package ReduceJoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text, Text, OrderBean> {
Text k = new Text();
OrderBean v = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
FileSplit inputSplit = (FileSplit)context.getInputSplit();
String fileName = inputSplit.getPath().getName();
//将商品id作为map输出的key
if (fileName.startsWith("order")) {
k.set(fields[1]);
v.setOrderID(fields[0]);
v.setProductID(fields[1]);
v.setAmount(Integer.parseInt(fields[2]));
v.setFlag("0");
v.setProductName("");
} else {
k.set(fields[0]);
v.setOrderID("");
v.setAmount(0);
v.setProductID(fields[0]);
v.setProductName(fields[1]);
v.setFlag("1");
}
context.write(k, v);
}
}reduce:
package ReduceJoin;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.lang.reflect.InvocationTargetException;
import java.util.ArrayList;
public class OrderReducer extends Reducer<Text, OrderBean, OrderBean, NullWritable> {
@Override
protected void reduce(Text key, Iterable<OrderBean> values, Context context) throws IOException, InterruptedException {
//key是productID,如果订单表和商品名称表的productID相同,则key相同,会merge在一起
//<productID,[商品名称V, 订单列表V1,订单列表V2]>
//reduce输出是将每个订单列表输出的
ArrayList<OrderBean> orderBeans = new ArrayList<>();
OrderBean pdBean = new OrderBean();
OrderBean tmp = new OrderBean();
for(OrderBean bean : values) {
if ("0".equals(bean.getFlag())) {
try {
BeanUtils.copyProperties(tmp, bean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
orderBeans.add(tmp);
//orderBeans.add(bean);
} else {
//取出商品名称的KV
try {
BeanUtils.copyProperties(pdBean, bean);
} catch (IllegalAccessException e) {
e.printStackTrace();
} catch (InvocationTargetException e) {
e.printStackTrace();
}
}
}
//获取当前的KV的productName,并输出
for (OrderBean o : orderBeans) {
o.setProductName(pdBean.getProductName());
context.write(o, NullWritable.get());
}
}
}
driver:
package ReduceJoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
args = new String[]{"G:\\test\\A\\mapjoin\\", "G:\\test\\A\\reducejoin12\\"};
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderBean.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





