如何使用Python统计180班QQ群聊文本可视化分析,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。




转眼就到大四年级,留在学校的时日不多了
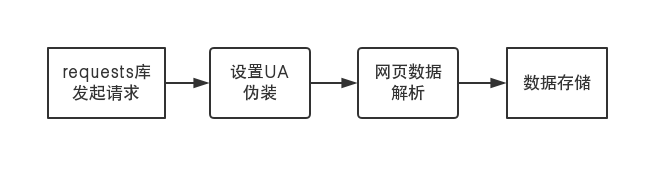
分为网站请求、伪装、解析、存储四个过程
更为详细的爬取流程如下所示
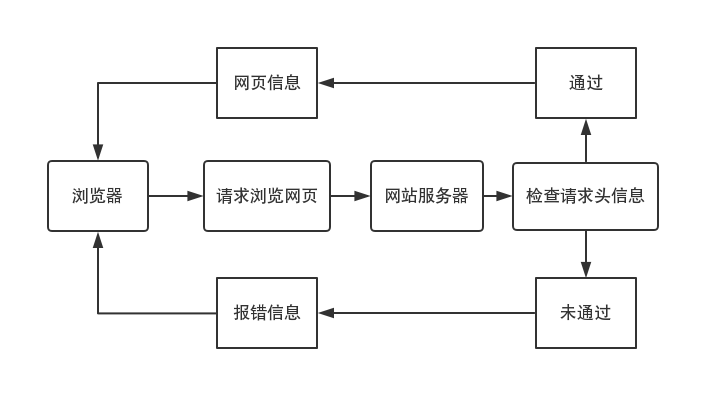
需要添加一些规则
然而,本文的文本数据
是我从QQ电脑端后台导出的
目前对于网络爬虫的学习
我只会豆瓣影评、书评、淘宝价格的爬取
等具体学习成熟了
发一篇网络爬虫的推文
敬请期待
导出文本数据后
编写程序,调试代码,做可视化分析
详细代码如下所示
#QQ群聊数据分析代码import reimport datetimeimport seaborn as snsimport matplotlib.pyplot as pltimport jiebafrom wordcloud import WordCloud, STOPWORDSfrom scipy.misc import imread# 日期def get_date(data): # 日期 dates = re.findall(r'\d{4}-\d{2}-\d{2}', data) # 天 days = [date[-2:] for date in dates] plt.subplot(221) sns.countplot(days) plt.title('Days') # 周几 weekdays = [datetime.date(int(date[:4]), int(date[5:7]), int(date[-2:])).isocalendar()[-1] for date in dates] plt.subplot(222) sns.countplot(weekdays) plt.title('WeekDays')# 时间def get_time(data): times = re.findall(r'\d{2}:\d{2}:\d{2}', data) # 小时 hours = [time[:2] for time in times] plt.subplot(223) sns.countplot(hours, order=['06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '00', '01', '02', '03', '04', '05']) plt.title('Hours')代码演示:# 词云def get_wordclound(text_data): word_list = [" ".join(jieba.cut(sentence)) for sentence in text_data] new_text = ' '.join(word_list) pic_path = 'QQ.jpg' mang_mask = imread(pic_path) plt.subplot(224) wordcloud = WordCloud(background_color="white", font_path='/home/shen/Downloads/fonts/msyh.ttc', mask=mang_mask, stopwords=STOPWORDS).generate(new_text) plt.imshow(wordcloud) plt.axis("off")# 内容及词云def get_content(data): pa = re.compile(r'\d{4}-\d{2}-\d{2}.*?\(\d+\)\n(.*?)\n\n', re.DOTALL) content = re.findall(pa, data) get_wordclound(content)def run(): filename = '新建文本文档.txt' with open(filename) as f: data = f.read() get_date(data) get_time(data) get_content(data) plt.show()
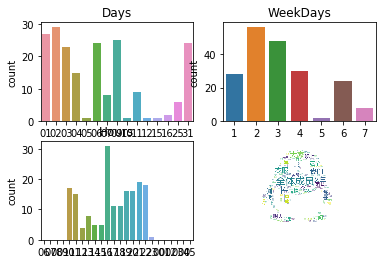
做出文本可视话图后,可以得出如下结论
在2018年1月1日~1月31日统计180班群聊中
1月2日这一天群聊次数最多
每周的星期二群聊次数做多
每天的16时群聊次数最多
做词云图发现
“全体成员”出现的词频最多
关于如何使用Python统计180班QQ群聊文本可视化分析问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





