这篇文章给大家介绍怎么分析Python生成器、迭代器与yield语句,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
今天要分享的内容是Python的生成器、迭代器与yield语句。主要包括什么是生成器,如何定义一个生成器,如何调用生成器包含的元素。迭代器也是一样的,最后介绍yield语句,以及它和生成器有什么关系。
[* ! *] 理解本文需要一定的基础,需要了解Python列表的定义,基本操作,字典,元组,字符串的概念。Python中for循环的语法结构,以及需要知道
if __name__ =="__main__":
的作用是什么?
1. 迭代
首先来看一下迭代的定义:
如果给定一个列表list或元组tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)。
用人话说一遍就是给一个列表或者元组,把里面的元素挨个看看都是啥,且只看一遍,就叫做迭代。下面写个简单的栗子。首先定义一个list_a,然后通过for循环遍历每一个元素,并打印出list_a中的每一个元素(图1),这就是对list_a迭代的过程。
迭代器的定义:
可以被next()函数调用并不断返回下一个值的对象称为迭代器(Iterator)。
一般来说迭代器都是可以迭代的。
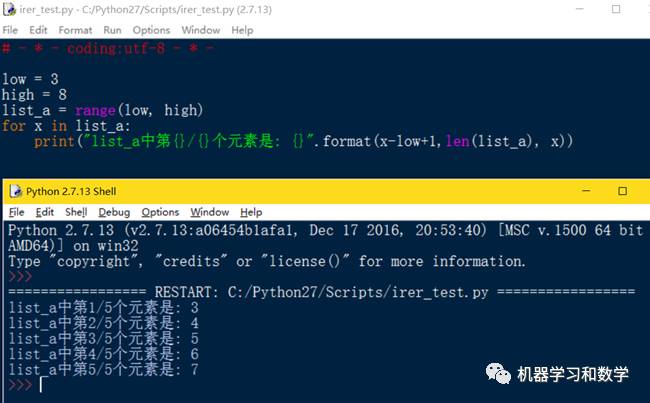
图1
刚才介绍的是对Python中列表的迭代,那么对于其他对象是不是也可以迭代呢?怎么来判断一个对象是不是可迭代的呢?我们可以利用collections模块中的Iterable函数来判断一个对象是不是可迭代的。比如:
分别定义列表,元组,字符串,字典,整数5种数据类型a,b,c,d,e,然后分别判断是否可迭代,见图2。结果可以看到除了整数不可迭代外,其他4种数据类型都是可迭代的。
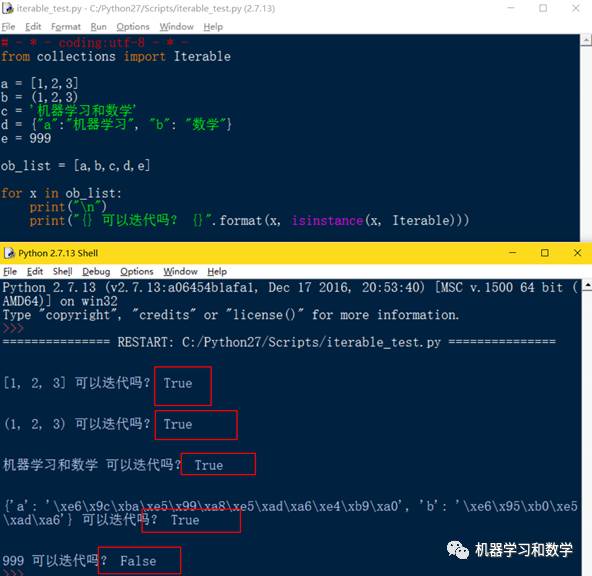
图2
2. 列表生成式
顾名思义,列表生成式就是用来自动创建一个列表表达式。使用列表生成式来创建列表的一个好处是可以简化代码,使代码美观,减少工作量。
举个简单的栗子,我们定义一个列表,name_list,然后利用列表生成式,将name_list中的大写字母全部变为小写字母。其中
[name.lower() for name in name_list]
就是列表生成式,首先定义对象的某种运算,然后定义一个for循环来遍历对象。
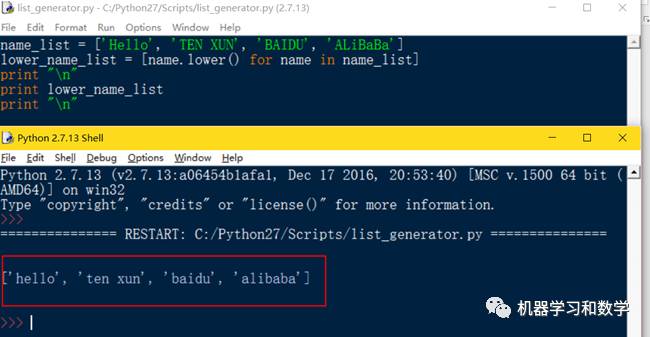
图3
3. 生成器
列表生成式一般用于列表不是特别长,占用内存比较小的情况,如果数据量很大,生成器是比列表生成式更好的选择。在Python中,一边进行某种运算,一遍进行循环的机制称为生成器(Generator)。定义一个生成器有一种很简单的方法,就是把列表生成式中的[ ]改为( )即可。还是刚才的栗子,我们把生成器对象打印一下,看到
<generator object <genexpr> at 0x00000000038FF828>
lower_name_list是一个generator object,生成器对象。
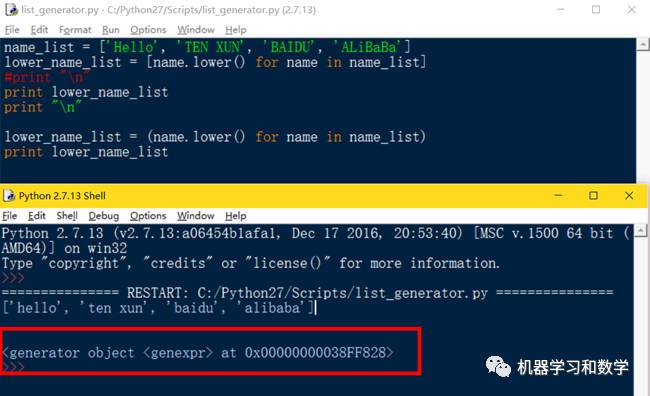
图4
然后介绍一下怎么查看这个生成器对象中有哪些元素?对于生成器对象来说,使用生成器的next()方法来输出每一个对象。Next()的意思就是下一个,就好像是next()对生成器说,来吧,下一个,生成器就把下一个元素吐出来了,知道生成器中没有可迭代的对象的时候,就会抛出StopIteration异常(图5)。
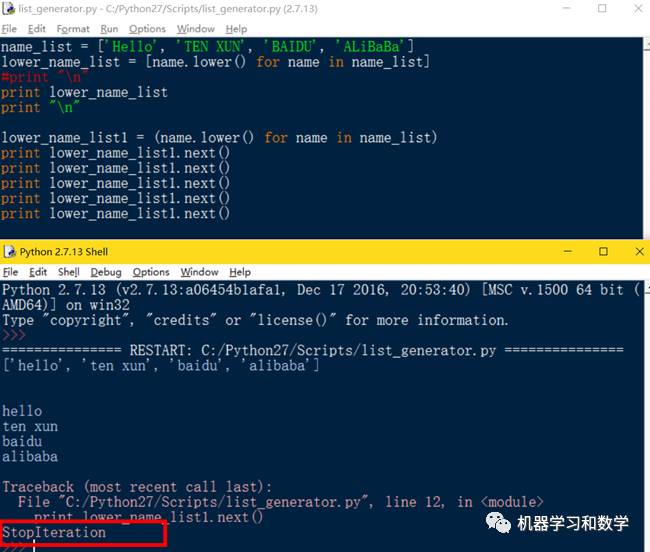
图5
接下来我们学习另外一种输出生成器中元素的方法,就是用for循环来迭代生成器中的元素(图6)。这是因为生成器是一种可迭代的对象,所以可以使用for循环来遍历。
>>> isinstance(lower_name_list1,Iterable)
>>> True
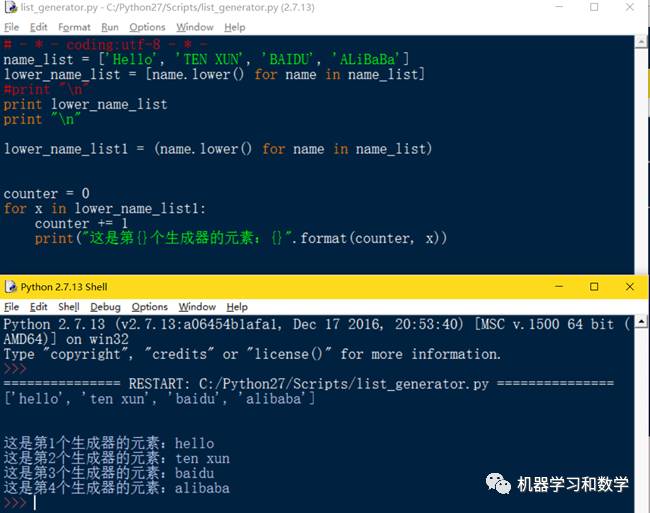
图6
4. yield语句
接下来就到了我们今天的重点要介绍的东西,这里必须强行安利一波,yield很有用很有用,最好能熟练掌握。然后为什么这么说呢?这个我要扯一会儿深度学习,我们说的机器学习,或者深度学习,其中非常重要的一个环节就是读取数据,就是把数据读进来然后交给我们的模型去训练,去学习。那么问题来了,给你一个100万张图片,或者1G的文本数据,你怎么来读数据?传统的方法在求解机器学习算法的时候,大部分是使用批梯度下降法(Batch Gradient Descent),一般是一次性把数据都读进来,然后整体做梯度下降。但是现在是大数据时代了,数据量一般都很大,如果一次读进来,内存肯定不够用,如果是GPU,同样显存也不够用。所以就有了后来的mini-batch 梯度下降,到底有多mini呢,通常远远小于全部数据量,这个数字就是我们在训练模型的时候取得batchsize的大小。意思就是从一个很大的数据集里面,每次只取很小的一部分数据集,然后遍历整个数据集。
这个思想和Python的yield语句极为吻合,所以我强烈推荐大家掌握yield语句。下面我们开始yield语句的学习。
首先来看一下Python官方文档中,对yield的解释。
意思是:yiled语句仅在定义一个生成器函数的时候使用,并且在生成器函数的函数体里面使用。在函数定义中使用yield语句之后,这个函数就不是一般的函数,而是生成器函数。
当我们调用生成器函数的时候,将会返回一个生成器。我们通过调用生成器的next()方法来执行生成器函数,直到抛出异常。
当执行yield语句的时候,生成器对象是被冻结的,执行的结果只有next()方法所返回的list。冻结的意思是除了next()方法可以返回一个列表以外,其他的变量都不会执行。
把这段文档简单理解一下就是我们可以通过定义一个包含yield语句的函数,来定义一个生成器函数。这个生成器函数可以通过next()方法来执行。
下面我们举个具体的栗子,来看一下yield的执行原理。
首先我们定义了两个函数,yield_test()和yield_test2(),第一个函数是用return来返回输出值,第二个函数用yield来返回。这样做是为了反映return和yield的区别,也是为了体现包含yield语句函数的不同之处。为什么要做这个比较呢,说白了,yield语句其实也是返回一个值,只不过这个返回方式不太寻常,它是以生成器函数的形式返回,所以我们对比一下和return的区别,看看哪里不一样。
# - * -coding:utf-8 - * -
defyield_test():
list_a = range(5)
list_b = []
for i in list_a:
list_b.append(i * i)
return list_b
defyield_test2():
list_a = range(5)
for i in list_a:
yield i * i
if __name__ =="__main__":
results = yield_test()
results2 = yield_test2()
print("The results is:", results)
print("The type of results is: ",type(results))
print("The results2 is: ",results2)
print("The type of results2 is:", type(results2))
result_list = []
for x in results2:
result_list.append(x)
print("The result_list is:",result_list)
下面是程序输出结果
"""
('The results is:', [0, 1, 4, 9, 16])
('The type of results is: ', <type 'list'>)
('The results2is: ', <generator object yield_test2 at 0x00000000040F6630>)
('The type of results2 is: ', <type 'generator'>)
('The result_list is:', [0, 1, 4, 9, 16])
"""
关于怎么分析Python生成器、迭代器与yield语句就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





