一、初识Spark和Hadoop
Apache Spark 是一个新兴的大数据处理通用引擎,提供了分布式的内存抽象。Spark 正如其名,最大的特点就是快(Lightning-fast),可比 Hadoop MapReduce 的处理速度快 100 倍。
Hadoop实质上更多是一个分布式数据基础设施: 它将巨大的数据集分派到一个由普通计算机组成的集群中的多个节点进行存储,意味着你不需要购买和维护昂贵的服务器硬件。
同时,Hadoop还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度。Spark则是一个专门用来对那些分布式存储的大数据进行处理的工具,它并不会进行分布式数据的存储。
Hadoop除了提供为大家所共识的HDFS分布式数据存储功能之外,还提供了叫做MapReduce的数据处理功能。所以我们完全可以抛开Spark,使用Hadoop自身的MapReduce来完成数据的处理。
当然,Spark也不是非要依附在Hadoop身上才能生存。但它没有提供文件管理系统,所以,它必须和其他的分布式文件系统进行集成才能运作。我们可以选择Hadoop的HDFS,也可以选择其他的基于云的数据系统平台。但Spark默认来说还是被用在Hadoop上面的,毕竟大家都认为它们的结合是最好的。
二、安装Spark
以下都是在Ubuntu 16.04 系统上的操作
1.安装Java JDK并配置好环境变量(这部分就不详细说了)
2.安装Hadoop
2.1 创建Hadoop用户:
打开终端,输入命令:
sudo useradd -m hadoop -s /bin/bash
添加hadoop用户,并设置/bin/bash作为shell
2.2 设置Hadoop用户的登录密码:
sudo passwd hadoop
然后根据系统提示输入两次自己的密码,再给hadoop用户添加管理员权限:
sudo adduser hadoop sudo
2.3 将当前的用户切换到刚刚创建的hadoop用户(屏幕右上角有个齿轮,点进去就看到)
2.4 更新系统的apt。打开终端,输入命令:
sudo apt-get update
2.5 安装ssh、配置ssh无密码登录
集群、单节点模式都需要遇到SSH登录。Ubuntu默认安装了SSH Client,但需要自己安装SSH Server:
sudo apt-get install openssh-server
安装后,直接登录本机
ssh localhost
SSH首次登录需要确认,根据提示输入:yes,然后再按提示输入刚刚设置的hadoop的密码,就登录了。
2.6 下载Hadoop
下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/
选择“stable”文件夹,点击下载“hadoop-2.x.y.tar.gz”文件。默认会下载到“下载”目录中,

在该文件夹下打开终端,将该文件解压到/usr/local文件中,执行命令:
sudo tar -zxf ~/hadoop-2.9.0.tar.gz cd /usr/local/ sudo mv ./hadoop-2.9.0/ ./hadoop #将文件名修改为hadoop sudo chown -R hadoop ./hadoop #修改文件权限
Hadoop的文件夹解压之后就可以直接使用,检查一下Hadoop是否可以正常使用,如果正常则显示Hadoop的版本信息
cd /usr/local/hadoop ./bin/hadoop version

这里就初步完成了Hadoop的安装,还有很多配置什么的用到的时候在写,比如伪分布式系统配置。
3.安装Spark
3.1 下载Spark:http://spark.apache.org/downloads.html

第一项我选择的版本是最新当前的最新版本:2.3.1,第二项选择“Pre-build with user-provided Apache Hadoop”,然后点击第三项后面的下载“spark-2.3.1-bin-without-hadoop-tgz”。
3.2 解压文件
这一步与Hadoop的解压是一样的,我们都把它解压到/usr/local路径下:
$ sudo tar -zxf ~/下载/spark-2.3.1-bin-without-hadoop.tgz -C /usr/local/ $ cd /usr/local $ sudo mv ./spark-2.3.1-bin-without-hadoop/ ./spark $ sudo chown -R hadoop:hadoop ./spark
3.3 设置环境变量
执行如下命令拷贝一个配置文件:
$ cd /usr/local/spark $ ./conf/spark-env.sh.template ./conf/spark-env.sh
然后编辑spark-env.sh:
$ vim ./conf/spark-env.sh
打开之后在这个文件的最后一行加上下面的内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
然后保存退出Vim,就可以使用Spark了。
三、Spark入门示例
在文件路径“/usr/local/spark/examples/src/main”中,我们可以找到spark自带的一些实例,如下图可以看到Spark支持Scala、Python、Java、R语言等。

1.Spark最简单的方式就是使用交互式命令行提示符。打开PySpark终端,在命令行中打出pyspark:
~$ pyspark
2.PySpark将会自动使用本地Spark配置创建一个SparkContext。我们可以通过sc变量来访问它,来创建第一个RDD:
>>>text=sc.textFile(“file\\\usr\local\spark\exp\test1.txt") >>>print text

3.转换一下这个RDD,来进行分布式计算的“hello world”:“字数统计”

首先导入了add操作符,它是个命名函数,可以作为加法的闭包来使用。我们稍后再使用这个函数。首先我们要做的是把文本拆分为单词。我们创建了一个tokenize函数,参数是文本片段,返回根据空格拆分的单词列表。然后我们通过给flatMap操作符传递tokenize闭包对textRDD进行变换创建了一个wordsRDD。你会发现,words是个PythonRDD,但是执行本应该立即进行。显然,我们还没有把整个数据集拆分为单词列表。
4.将每个单词映射到一个键值对,其中键是单词,值是1,然后使用reducer计算每个键的1总数
>>> wc = words.map(lambda x: (x,1)) >>> print wc.toDebugString()

我使用了一个匿名函数(用了Python中的lambda关键字)而不是命名函数。这行代码将会把lambda映射到每个单词。因此,每个x都是一个单词,每个单词都会被匿名闭包转换为元组(word, 1)。为了查看转换关系,我们使用toDebugString方法来查看PipelinedRDD是怎么被转换的。可以使用reduceByKey动作进行字数统计,然后把统计结果写到磁盘。
5.使用reduceByKey动作进行字数统计,然后把统计结果写到磁盘
>>> counts = wc.reduceByKey(add)
>>> counts.saveAsTextFile("wc")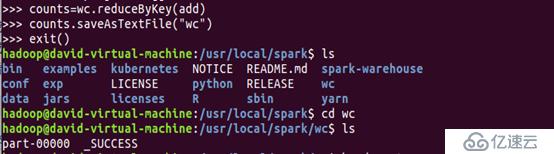
一旦我们最终调用了saveAsTextFile动作,这个分布式作业就开始执行了,在作业“跨集群地”(或者你本机的很多进程)运行时,你应该可以看到很多INFO语句。如果退出解释器,你可以看到当前工作目录下有个“wc”目录。每个part文件都代表你本机上的进程计算得到的被保持到磁盘上的最终RDD。

四、Spark数据形式
4.1 弹性分布式数据集(RDD)
Spark 的主要抽象是分布式的元素集合(distributed collection of items),称为RDD(Resilient Distributed Dataset,弹性分布式数据集),它可被分发到集群各个节点上,进行并行操作。RDDs 可以通过 Hadoop InputFormats 创建(如 HDFS),或者从其他 RDDs 转化而来。
获得RDD的三种方式:
Parallelize:将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试
>>>sc.parallelize(['cat','apple','bat’])
MakeRDD:只有scala版本才有此函数,用法与parallelize类似
textFile:从外部存储中读取数据来创建 RDD
>>>sc.textFile(“file\\\usr\local\spark\README.md”)
RDD的两个特性:不可变;分布式。
RDD支持两种操作;Transformation(转化操作:返回值还是RDD)如map(),filter()等。这种操作是lazy(惰性)的,即从一个RDD转换生成另一个RDD的操作不是马上执行,只是记录下来,只有等到有Action操作是才会真正启动计算,将生成的新RDD写到内存或hdfs里,不会对原有的RDD的值进行改变;Action(行动操作:返回值不是RDD)会实际触发Spark计算,对RDD计算出一个结果,并把结果返回到内存或hdfs中,如count(),first()等。
4.2 RDD的缓存策略
Spark最为强大的功能之一便是能够把数据缓存在集群的内存里。这通过调用RDD的cache函数来实现:rddFromTextFile.cache,
调用一个RDD的cache函数将会告诉Spark将这个RDD缓存在内存中。在RDD首次调用一个执行操作时,这个操作对应的计算会立即执行,数据会从数据源里读出并保存到内存。因此,首次调用cache函数所需要的时间会部分取决于Spark从输入源读取数据所需要的时间。但是,当下一次访问该数据集的时候,数据可以直接从内存中读出从而减少低效的I/O操作,加快计算。多数情况下,这会取得数倍的速度提升。
Spark的另一个核心功能是能创建两种特殊类型的变量:广播变量和累加器。广播变量(broadcast variable)为只读变量,它由运行SparkContext的驱动程序创建后发送给会参与计算的节点。对那些需要让各工作节点高效地访问相同数据的应用场景,比如机器学习,这非常有用。Spark下创建广播变量只需在SparkContext上调用一个方法即可:
>>> broadcastAList = sc.broadcast(list(["a", "b", "c", "d", "e"]))
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





