最近开发的搜索引擎中,需要对索引进行分片。根据项目的需求,我们提供了两种分片方式。过程博客记录一下。
Hash算法
原理很简单,通过行键(_id)的Hash值确定所在的分片,然后再进行操作。
举个栗(例)子,现在有个索引,初始化5个分片,分别为shard0, shard1, shard2, shard3, shard4。
现在需要保存一行数据,_id为0001000000123,_id的HashCode为1571574097,对5求余(1571574097 % 5)为2,从而确定数据应该保存在shard2。下面是一个简单的图解:
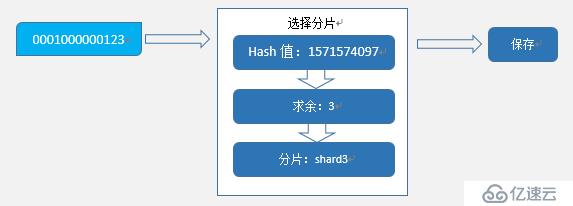
Hash算法分片实现非常简单,计算过程只需要知道分片数量即可完成定位。但也正因为分片数量是算法的一部分,修改分片数量的代价也非常昂贵。
有一种解决方案是重新排列,比如从M个分片切增加到N个分片,先将每个分片切分为N个小分片,然后再将所有小分片合并为大分片。从网络上复制了一张图解说明,
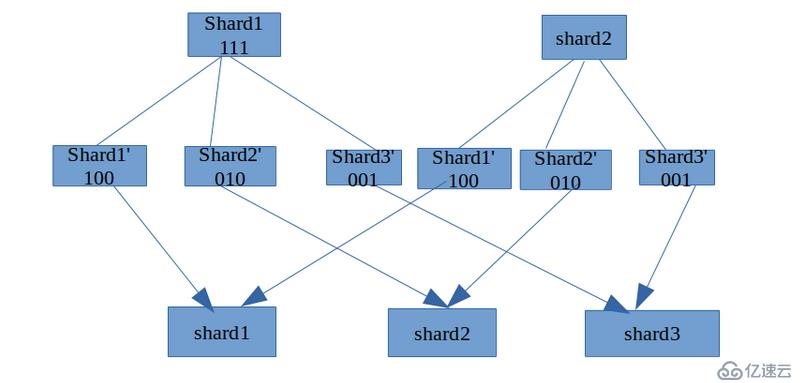
这种方式的优点是,可以任意设定新的分片数量。缺点是需要对所有数据进行重新排列,如果数据量很大,可能会非常耗时。
当然,由于项目数据增长是不可预测性,我们没有选择上面增片方式,而是选择了另外一种增片的方式。
动态分片
结合Hash算法和二叉树的原理,进行动态增加分片。
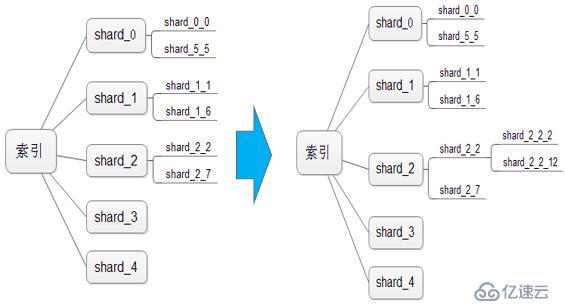
首先,Hash算法与之前一样,搜索创建时,可以设置一个初始化的分片数量,例如初始化5个分片,分别为shard_0, shard_1, shard_2, shard_3, shard_4。添加数据时,通过_id的Hash值确定数据需要保存到哪个分片。不同的是,我们设置了每个分片的最大行数,当某个分片的数量达到最大行数时,该分片会分拆分为两个小的分片,并且作为当前分片的子分片。
例如,设置分片最大行数为1000万,当shard_2超过1000万时,分裂为两个子分片shard_2_2和shard_2_7。如果shard_2_2数据继续增长到1000万,则分裂子分片shard_2_2_2和shard_2_2_12。
从示例中可以看出,分裂并不是毫无规则,假设分片的初始数量为m,k表示二叉树深度,则分片n的分裂规则为
shard_n 分裂为 shard_n_n和shard_n_(n + m * 1)
shard_n_n 分裂为 shard_n_n_n和shard_n_n_(n + m * 2)
shard_n_(n + m * 1) 分裂为 shard_n_(n + m * 1)_(n + m * 1) 和 shard_n_(n + m * 1)_(n + m * 1 + m * 2)
...
上面的公式看起来很复杂,我们使用图解来说明分裂过程
如果还没有明白,我们可以通过_id寻找对应的分片来梳理一下思路,还是上面的例子,
需要保存一行数据,_id为0001000000123,_id的HashCode为1571574097,对5求余(1571574097 % 5)为2,从而确定数据应该保存在shard_2。
shard_2已经分裂为shard_2_2和shard_2_7两个子分片了,这一层的基数为10(基数=初始化分片数量*层数),我们将1571574097对10求余(1571574097 % 10)为7,则数据保存在shard_2_7。
shard_2_7没有子分片,说明该分片没有分裂,直接保存在该分片即可。
分析一下分片寻找原理:
按照hash算法找到分片;
如果分片有子分片,则从子分片中查找;
如果分片没有子分片,则数据保存在该分片;
再来分析一下分片分裂规则,为什么shard_1会分裂为shard_1_1和shard_1_6?
原因很简单,shard_1表示id的hash值对5取余后值为1,如果shard_1分裂为2份,则第2层的基数10=上一层基数*2,即5 * 2。对5取余值为1,那么对10取余结果只会是1和6,因此
shard_1分裂为shard_1_1和shard_1_6。
数据一致性
动态分片是在使用过程中自动分片,分片过程会非常长,经过测试,索引32列500万行的分裂为两个子分片,耗时245秒。分裂过程如果原始数据发生修改,这些修改可能会丢失。因此,在分裂过程中需要一定的措施保障数据安全性。
方法一,使用悲观锁。
分裂前对锁定分片不能再修改,直到分裂完成后才能再修改。
优点:逻辑简单粗暴,开发难度低。
缺点:锁的时间太长可能会导致调用服务方产生大量的异常请求。
方法二,使用事务日志。
分裂前创建事务日志,当前shard所有新增、修改和删除操作都写入事务日志。分裂完成后,锁定分片和子分片,从事务日志中恢复数据到子分片,然后解锁。
优点:只有在创建事务日志和恢复数据时会锁定分片,锁定时间比较短暂,影响服务调用方几乎不受影响。
缺点:开发难度大,需要开发一套事务日志和日志恢复操作接口。但是底层lucene存储已经有一套事务日志接口和实现,该缺点几乎可以忽略。
行键递增分片
如果保存数据的行键整体上是递增的,例如,行键是000000001,000000002,000000003,...这种格式,可以按行键进行分片。这种分片实现方式比较简单,
1. 创建索引时设置一个初始化分片;
2. 添加数据过程中,并且记录分片行键最小值minId和最大值maxId;
3. 当分片数据量超过设置的最大值是,创建一个新的分片,新增的数据保存在该分片;
4. 更新数据时,通过与每个分片的minId和maxId比较,确定所在的分片。
行键递增分片与Hash算法分片比较:
1.行键递增分片方式实现更简单,开发成本更低;
2.行键递增分片通过minId和maxId定位分片,如果每个分片信息中需要记录分片的minId和maxId;
3.行键递增分片存入数据时,需要按照一定的顺序存入,否则可能会导致数据倾斜;
4.行键递增分片按需添加分片,只需要设置每个分片的最大行数,没有分裂过程;
5.行键递增分片大量的压力集中在最新的分片上,Hash算法分片压力分散到各个分片,理论上Hash算法分片可以支持更高的吞吐量。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





