这篇文章将为大家详细讲解有关Hive基础操作的示例代码,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1.在hive的服务端新建源数据
[root@hadoop5 ~]# cat hivedata 1,xiaoming,read-tv-code,beijing:chaoyang-shanghai:pudong 2,lisi,cook-game,chongqing:yongchun-sichuan:yibing 3,zhangsan,shop-eat,shanghai:xujiahui
2.创建内部表
create table test1 (id int,name string,likes array<string>,address map<string,string>) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':';
3.将数据导入hive
load data local inpath '/root/hivedata' into table test1;
0: jdbc:hive2://hadoop5:10000> select * from test1;
+-----------+-------------+-----------------------+----------------------------------------------+
| test1.id | test1.name | test1.likes | test1.address |
+-----------+-------------+-----------------------+----------------------------------------------+
| 1 | xiaoming | ["read","tv","code"] | {"beijing":"chaoyang","shanghai":"pudong"} |
| 2 | lisi | ["cook","game"] | {"chongqing":"yongchun","sichuan":"yibing"} |
| 3 | zhangsan | ["shop","eat"] | {"shanghai":"xujiahui"} |
+-----------+-------------+-----------------------+----------------------------------------------+
3 rows selected (0.207 seconds)
0: jdbc:hive2://hadoop5:10000>4.创建外部表(在hive中删除后,hdfs上数据不会删除)
create external table test2 (id int,name string,likes array<string>,address map<string,string>) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':' location '/user/test2';
5.以test1的部分列为模板创建test3
create table test3 as select id, name from test1;
0: jdbc:hive2://hadoop5:10000> desc test3; +-----------+------------+----------+ | col_name | data_type | comment | +-----------+------------+----------+ | id | int | | | name | string | | +-----------+------------+----------+ 2 rows selected (0.406 seconds) 0: jdbc:hive2://hadoop5:10000>
6.参照test1创建test4
create table test4 like test1;
7.创建分区表
create table test5 (id int,name string,likes array<string>,address map<string,string>) partitioned by (sex string) row format delimited fields terminated by ',' collection items terminated by '-' map keys terminated by ':';
0: jdbc:hive2://hadoop5:10000> desc test5; +--------------------------+-----------------------+-----------------------+ | col_name | data_type | comment | +--------------------------+-----------------------+-----------------------+ | id | int | | | name | string | | | likes | array<string> | | | address | map<string,string> | | | sex | string | | | | NULL | NULL | | # Partition Information | NULL | NULL | | # col_name | data_type | comment | | | NULL | NULL | | sex | string | | +--------------------------+-----------------------+-----------------------+ 10 rows selected (0.382 seconds) 0: jdbc:hive2://hadoop5:10000>
8.为该分区添加加载数据
load data local inpath '/root/hivedata' into table test5 partition (sex='boy');
0: jdbc:hive2://hadoop5:10000> select * from test5;
+-----------+-------------+-----------------------+----------------------------------------------+------------+
| test5.id | test5.name | test5.likes | test5.address | test5.sex |
+-----------+-------------+-----------------------+----------------------------------------------+------------+
| 1 | xiaoming | ["read","tv","code"] | {"beijing":"chaoyang","shanghai":"pudong"} | boy |
| 2 | lisi | ["cook","game"] | {"chongqing":"yongchun","sichuan":"yibing"} | boy |
| 3 | zhangsan | ["shop","eat"] | {"shanghai":"xujiahui"} | boy |
+-----------+-------------+-----------------------+----------------------------------------------+------------+
3 rows selected (0.784 seconds)
0: jdbc:hive2://hadoop5:10000>9.为test5添加一个sex=girl的分区
alter table test5 add partition (sex='girl');
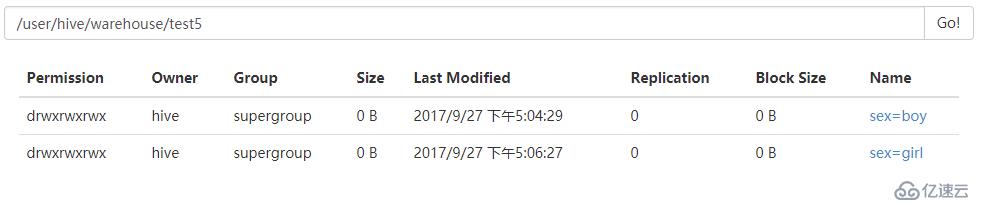
10.删除一个分区
alter table test5 drop partition (sex='girl');
关于“Hive基础操作的示例代码”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





