数据量大约在10亿+,需要做一个即席查询,用户可以主动输入搜索条件,如时间。可提供一定的预处理时间。每天还有新数据加入。
10亿+的数据对于普通的rdbms还是有些压力的,而且数据每天还在不停的增长,所以我们运用了我们的spark技术来做一个计算加速。关于增量更新的相关,我会在后续的博客中介绍。
语句如下
select count(*) a,b from table_a where c = '20170101' group by a,b order by a
首先用我们的spark-local模式进行测试数据量成倍上涨。
| 数据量 | table_a的倍数 | spark-local i3 ddr3 8g | spark-local i7 ddr4 32g | spark-yarn 5g,3core 3instance |
| 800w | 1 | 0.512s | 0.4 | 0.771 |
| 1600w | 2 | 0.512s | 0.5 | 0.552 |
| 3200w | 4 | 0.794s | 0.68 | 0.579 |
| 6400w | 8 | 1.126s | 0.945 | 0.652 |
| 1亿2800w | 16 | 1.968s | 1.4 | 0.922 |
| 2亿5600w | 32 | 3.579s | 2.574 | 1.475 |
| 5亿1200w | 64 | 6.928s | 5.001 | 3.384 |
| 10亿2400w | 128 | 13.395s | 9.528 | 5.372 |
我们可以看到单核cpu的性能也会影响spark的性能,所以在衡量一个spark集群的计算性能时,不光要看有几个core,几个instance,还要看单个core的计算能力,而且数据量越大,差距也越大。
spark-sql有一个特点,同样的语句,第二,第三次计算会比之前快,如果不停地运行同一个语句,你会发现时间会成下降趋势直到一个稳定值,一般为2-3次后会达到最小值,在10亿这个级别上,在yarn模式下,运行3次左右后,性能可以达到3s左右,对于一个测试用的小集群已经很让人满意了,如果是正规的spark集群,相信性能还会好很多,做即席查询完全够用了。个人理解是spark会有一定的缓存机制,但是不会缓存在多的东西,这个和之后要讲的Kylin还是不同的。kylin如果是同样的语句,第二次绝对是秒出。
下面我们尝试了用Kylin,效果很让人震撼。
Kylin官网如下
http://kylin.apache.org/
Apache Kylin是一个开源的分布式分析引擎,提供Hadoop之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。
Kylin中国唯一Apache顶级项目。支持下哦
Kylin是基于Hive表的,所以我们还是要将我们的数据先导入到hive中去。
Kylin的安装在这里就不将了,很简单,官网有介绍,启动下服务就可以了。然后打开7070端口
要使用Kylin计算,我们要先建立Model,一个model需要对应一张hive表,然后再model的基础上建立cube,这里我们创建一个默认的cube即可。
在Model页面我们可以看我们创建的cube如下图所示。

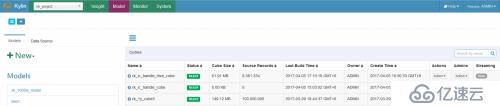
在列表中我们可以看到cube大小,记录数,上次构建时间等信息。
build好cube后就可以查询了,如果build成功cube的状态会变为READY,这时就可以查询了。
还是用之前的3节点的集群做性能测试
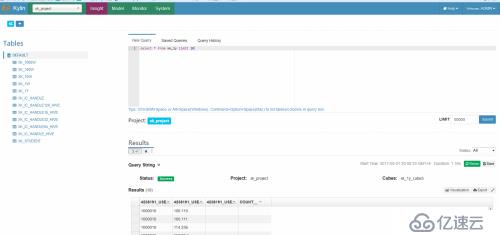
如上图所示,我们在查询界面可以看到这个语句走了哪个project,cubes,耗时等信息
测试结果如下
| 数据量 | 构建时间(全量) | sql时间 |
| 800w | 6.5min | 0.15s |
| 1亿2800w | 48min | 0.15s |
| 2亿5600w | 90.17min | 0.15s |
| 5亿1200w | 142.40min | 执行错误 |
这里到5亿的时候构建cube可以成功,但是运行sql会报错。应该是我没配置好。
可以看到,kylin的查询性能还是非常可观的,而且查询时的资源消耗非常少,这点和spark不一样,由于这样的特性相对于spark,同样性能的集群上kylin就可以支持高得多的并发,并且提供高得多的查询性能,但是kylin的代价是很长的构建cube的时间和更多的磁盘占用,而且据我的经验来看,kylin对sql的支持不如spark-sql支持的好。如果要把原来rdbms的查询迁移到大数据集群中来,spark-sql的适应性会更好。
虽然kylin也支持增量构建,但是相对于spark来说,数据准备的时间还是会长很多,因为spark也支持增量更新。如果允许有数据预处理时间的,例如把构建放到晚上12:00过后进行,在这种场景下,kylin也许更适合.但是如果需要数据实时变化,而且维度很多,sql完全不确定的情况,也许spark-sql更合适一些,具体怎么选择,还要看应用场景。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





