小编给大家分享一下HDFS基础配置安装及命令使用的示例分析,希望大家阅读完这篇文章之后都有所收获,下面让我们一起去探讨吧!
HDFS是基于Java的文件系统,可在Hadoop生态系统中提供可扩展且可靠的数据存储。因此,我们需要了解基本的HDFS配置和命令才能正常使用它。在使用之前,我们首先讨论如何配置安装HDFS。Hadoop以及HDFS都运行在java环境中,因此我们都需要安装JDK:
yum -y install jdk(或手动安装)
设置namenode节点到datanode节点的免密登陆
1、本地免密登录
# ssh localhost #检测能否在本机上实现免密码登陆 # ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa #创建登陆的公钥和私钥,公钥放在id_dsa.pub中,私钥放在id_dsa中
# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将公钥追加到已认证信息中 # ssh localhost #实现免密码登陆
2、跨主机免密登陆
# scp ~/.ssh/id_dsa.pub root@node2:~/.ssh/ #在namenode上执行 # cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys #将公钥追加到已认证信息中,在datanode上执行该操作
3、对所有datanode执行上述操作
设置域名解析(在所有节点增加)
# vi /etc/hosts # 增加节点对应节点,如果不加入节点则需要在配置文件中写节点IP 192.168.150.128 node1 192.168.150.129 node2 192.168.150.130 node3 192.168.150.131 node4
由于Hadoop有bin包,所以下载后只需解压即可使用。如果我们使用的是版本hadoop-1.2.1,那就将软件解压到/root/hadoop-1.2.1文件夹中。
注意:namenode和datanode软件包的放置位置要完全相同,否则在集群启动服务时会出现找不到文件的情况。
配置
#vi /root/hadoop-1.2.1/conf/core-site.xml <configuration> <property> <name>fs.default.name</name> # namenode节点名 <value>hdfs://node1:9000</value> #namenode域名(或IP)和端口 </property> <property> <name>hadoop.tmp.dir</name> #文件储存目录 <value>/opt/hadoop-1.2</value> #fs的放置位置 </property> </configuration> 其它具体配置可以查看./hadoop-1.2.1/docs的文档。 #vi /root/hadoop-1.2.1/conf/hdfs-site.xml <configuration> <name>dfs.replication</name> #block的副本数,不能超过datanode的数目 <value>2</value> </configuration> #vi /root/hadoop-1.2.1/conf/slaves #该文件设置datanode节点的域名(IP) node2 node3 #vi /root/hadoop-1.2.1/conf/masters #该文件设置secondarynamenode节点的域名(IP) node2 # 只要跟namenode不在同一台机器上即可 #vi /root/hadoop-1.2.1/conf/hadoop-env.sh #设置运行环境 export JAVA_HOME=/usr/java/jdk1.7.0_79 # 只要设置jdk的目录即可 在所有的节点上进行上述的相同配置。
HDFS本地Golang客户端实践
基于上述基础配置,我们也可以尝试配置HDFS的本地golang客户端,它使用协议缓冲区API直接连接namenode,使用stdlib os包并实现相应接口,包括os.FileInfo和os.PathError。
这是它在action中的状态:
client, _ := hdfs.New("namenode:8020")file, _ := client.Open("/mobydick.txt")buf := make([]byte, 59)
file.ReadAt(buf, 48847)
fmt.Println(string(buf))// => Abominable are the tumblers into which he pours his poison.HDFS二进制文件
与库类似,此repo包含HDFS命令行客户端,主要目标是启用unix动词实现:
$ hdfs --help Usage: hdfs COMMAND The flags available are a subset of the POSIX ones, but should behave similarly. Valid commands: ls [-lah] [FILE]... rm [-rf] FILE... mv [-fT] SOURCE... DEST mkdir [-p] FILE... touch [-amc] FILE... chmod [-R] OCTAL-MODE FILE... chown [-R] OWNER[:GROUP] FILE... cat SOURCE... head [-n LINES | -c BYTES] SOURCE... tail [-n LINES | -c BYTES] SOURCE... du [-sh] FILE... checksum FILE... get SOURCE [DEST] getmerge SOURCE DEST put SOURCE DEST
由于它不必等待JVM启动,所以hadoop -fs要快得多:
$ time hadoop fs -ls / > /dev/null real 0m2.218s user 0m2.500s sys 0m0.376s $ time hdfs ls / > /dev/null real 0m0.015s user 0m0.004s sys 0m0.004s
安装命令行客户端
从发布页面抓取tarball并将其解压缩到任意位置。
要配置客户端,请确保其中一个或两个环境变量指向Hadoop配置(core-site.xml和hdfs-site.xml)。在安装了Hadoop的系统上,应该已经设置过上述变量。
$ export HADOOP_HOME="/etc/hadoop" $ export HADOOP_CONF_DIR="/etc/hadoop/conf"
要在linux上完成选项卡安装,请将tarball附带的bash_completion文件复制或链接到正确位置:
$ ln -sT bash_completion /etc/bash_completion.d/gohdfs
默认情况下,在非kerberized集群上,HDFS用户可设置为当前登录用户,也可以使用另一个环境变量覆盖它:
$ export HADOOP_USER_NAME=username
使用带有Kerberos身份验证的命令行客户端
与hadoop fs一样,命令行客户端需要在默认位置使用ccache文件:/ tmp / krb5cc_ <uid>。 这意味着它必须“正常工作”才能使用kinit:
$ kinit bob@EXAMPLE.com $ hdfs ls /
如果不起作用,请尝试将KRB5CCNAME环境变量设置为保存ccache的位置。
兼容性
该库使用HDFS协议的“Version 9”,这意味着它应该使用基于2.2.x及更高版本的Hadoop发行版,测试针对CDH 5.x和HDP 2.x运行。
检查机器是否能与HDFS通信
如果想检查一台机器是否可以与另一台机器上运行的HDFS服务器通信,并从Hadoop wiki中修改一些代码,如下所示:
package org.playground;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class HadoopDFSFileReadWrite {
static void printAndExit(String str) {
System.err.println( str );
System.exit(1);
}
public static void main (String[] argv) throws IOException {
Configuration conf = new Configuration();
conf.addResource(new Path("/Users/markneedham/Downloads/core-site.xml"));
FileSystem fs = FileSystem.get(conf);
Path inFile = new Path("hdfs://192.168.0.11/user/markneedham/explore.R");
Path outFile = new Path("hdfs://192.168.0.11/user/markneedham/output-" + System.currentTimeMillis());
// Check if input/output are valid
if (!fs.exists(inFile))
printAndExit("Input file not found");
if (!fs.isFile(inFile))
printAndExit("Input should be a file");
if (fs.exists(outFile))
printAndExit("Output already exists");
// Read from and write to new file
byte buffer[] = new byte[256];
try ( FSDataInputStream in = fs.open( inFile ); FSDataOutputStream out = fs.create( outFile ) )
{
int bytesRead = 0;
while ( (bytesRead = in.read( buffer )) > 0 )
{
out.write( buffer, 0, bytesRead );
}
}
catch ( IOException e )
{
System.out.println( "Error while copying file" );
}
}
}我最初以为POM文件中只有以下内容:
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.0</version> </dependency>
但运行脚本时,我得到了以下结果:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.fs.FSOutputSummer.<init>(Ljava/util/zip/Checksum;II)V at org.apache.hadoop.hdfs.DFSOutputStream.<init>(DFSOutputStream.java:1553) at org.apache.hadoop.hdfs.DFSOutputStream.<init>(DFSOutputStream.java:1582) at org.apache.hadoop.hdfs.DFSOutputStream.newStreamForCreate(DFSOutputStream.java:1614) at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1465) at org.apache.hadoop.hdfs.DFSClient.create(DFSClient.java:1390) at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:394) at org.apache.hadoop.hdfs.DistributedFileSystem$6.doCall(DistributedFileSystem.java:390) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:390) at org.apache.hadoop.hdfs.DistributedFileSystem.create(DistributedFileSystem.java:334) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:909) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:890) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:787) at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:776) at org.playground.HadoopDFSFileReadWrite.main(HadoopDFSFileReadWrite.java:37) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
通过跟踪堆栈跟踪,我意识到犯了一个错误,即对hadoop-hdfs 2.4.1进行了依赖。如果没有hadoop-hdfs依赖,我们会看到如下错误:
Exception in thread "main" java.io.IOException: No FileSystem for scheme: hdfs at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2644) at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2651) at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:92) at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2687) at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2669) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:371) at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:170) at org.playground.HadoopDFSFileReadWrite.main(HadoopDFSFileReadWrite.java:22) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:497) at com.intellij.rt.execution.application.AppMain.main(AppMain.java:140)
现在,让我们添加正确的依赖项版本,并确保可以按照预期工作:
<dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.0</version> <exclusions> <exclusion> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> </exclusion> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> </exclusions> </dependency>
运行时,它会在另一台机器上用当前时间戳在HDFS中创建一个新文件:
$ date +%s000 1446336801000 $ hdfs dfs -ls ... -rw-r--r-- 3 markneedham supergroup 9249 2015-11-01 00:13 output-1446337098257 ...
(该项目开源地址:https://github.com/colinmarc/hdfs)
基础HDFS命令
完成安装配置后,我们需要了解HDFS基础命令,需要知道每个命令的详细语法。一般语法如下:
hadoop dfs [COMMAND [COMMAND_OPTIONS]]
这将在Hadoop(HDFS)支持的文件系统上运行filesystem命令,其余Command选项如下所示:

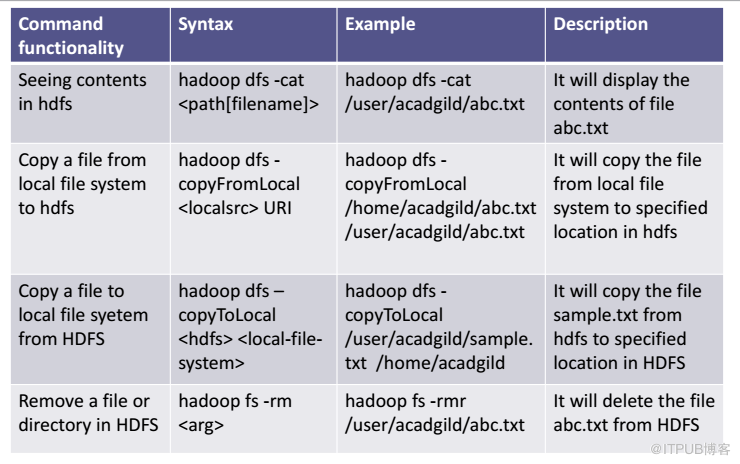
1、put命令
'put'命令将数据输入HDFS。
语法:hadoop dfs -put </ source path> </ destination path>
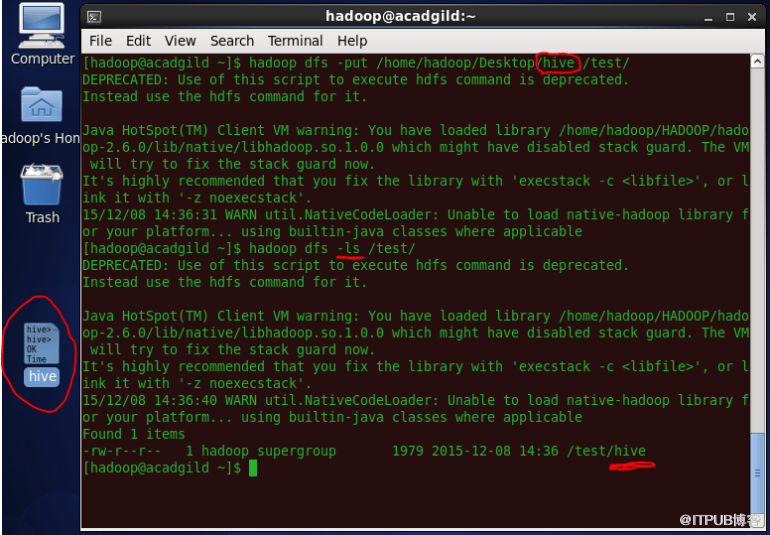
2、List命令
'list'命令显示特定路径中的所有可用文件。
语法:hadoop dfs -ls </ source path>
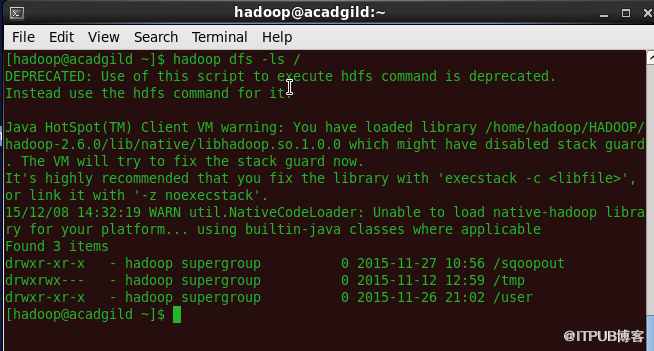
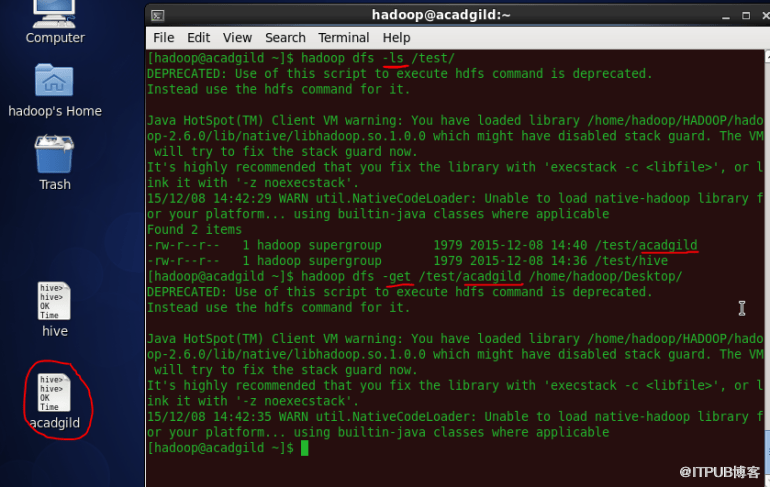
3、Get命令
'get'命令将上述文件的全部内容复制到本地驱动器。
语法:hadoop dfs -get </ source path> </ destination path>
4、Make Directory命令
'mkdir'命令在指定位置创建一个新目录。
语法:hadoop dfs -mkdir </ source path>

5、查看特定文件的内容
'cat'命令用于显示文件的所有内容。
语法:hadoop dfs -cat </ path [filename]>
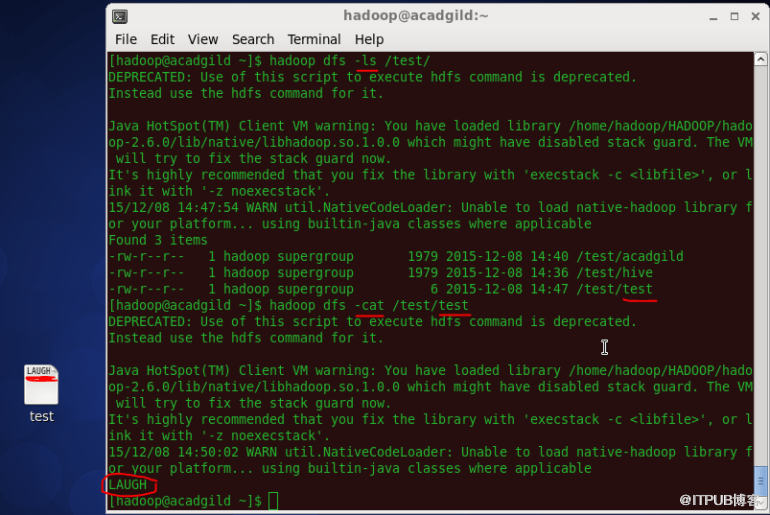
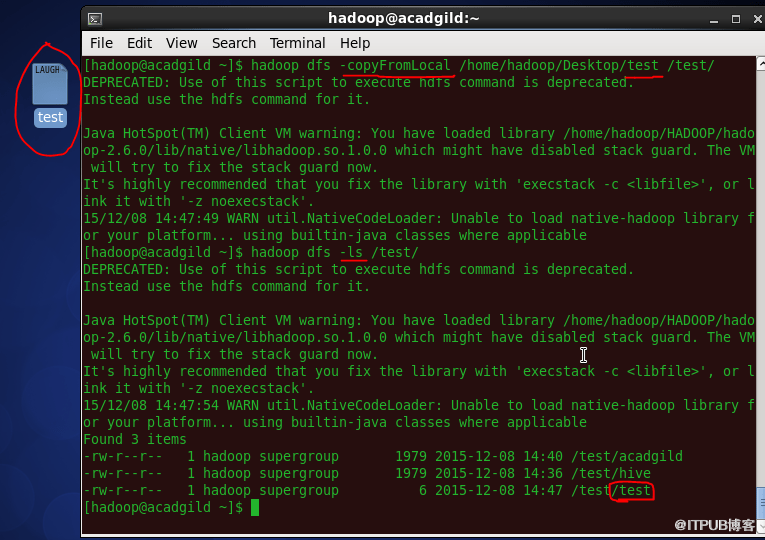
6、复制HDFS内的完整文件
'copyfromlocal'命令将文件从本地文件系统复制到HDFS。
语法:hadoop dfs -copyFromLocal </ source path> </ destination path>
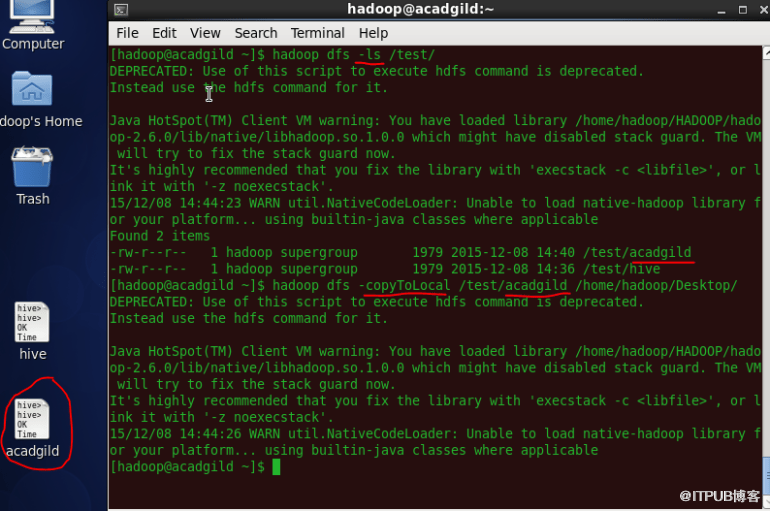
7、将文件从HDFS复制到本地文件系统。
'copytolocal'命令将文件从HDFS复制到本地文件系统。
语法:hadoop dfs -copyToLocal </ source path> </ destination path>
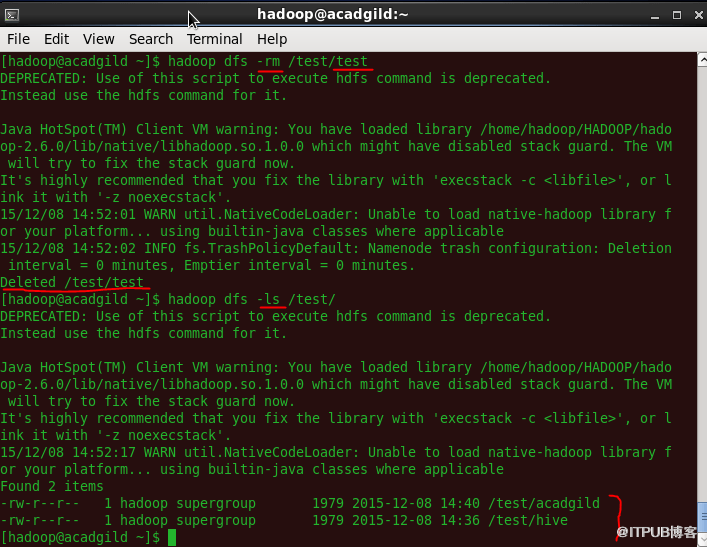
8、删除文件
命令'rm'将删除存储在HDFS中的文件。
语法:hadoop dfs -rm </ path [filename]>
9、运行DFS文件系统以检查实用程序
命令'fsck'用于检查文件系统的一致性
语法:hadoop fsck </ file path>
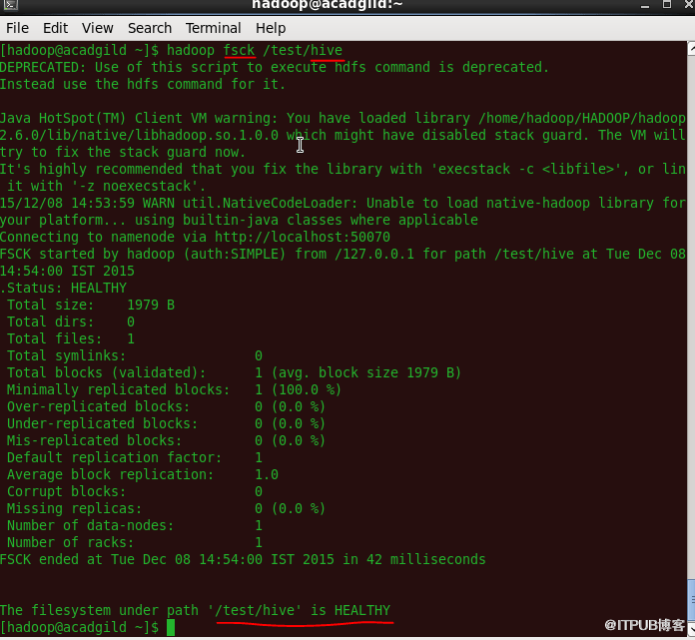
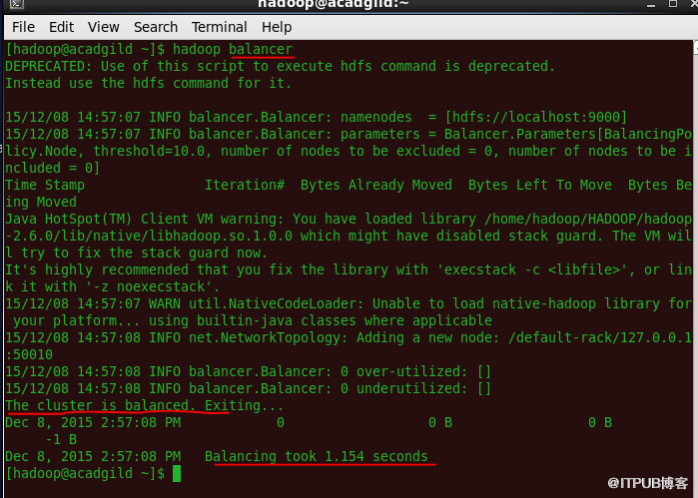
10、集群负载均衡程序
'balancer'命令将检查集群中节点的工作负载并进行平衡。
语法:hadoop balancer
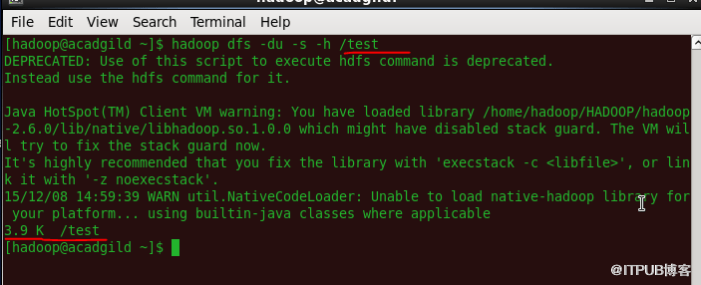
11、检查HDFS中的目录空间
该命令将显示集群内文件占用的大小。
语法:hadoop dfs -du -s -h </ file path>
12、列出所有Hadoop文件系统Shell命令
'fs'命令列出了Hadoop文件系统的所有shell命令。
语法:hadoop fs [options]
[hadoop@acadgild ~]$ hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
Generic options supported are
-conf <configuration file> specify an application configuration file
-D <property=value> use value for given property
-fs <local|namenode:port> specify a namenode
-jt <local|resourcemanager:port> specify a ResourceManager
-files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster
-libjars <comma separated list of jars> specify comma separated jar files to include in the classpath.
-archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines.
The general command line syntax is
bin/hadoop command [genericOptions] [commandOptions]
[hadoop@acadgild ~]$看完了这篇文章,相信你对“HDFS基础配置安装及命令使用的示例分析”有了一定的了解,如果想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





