еҰӮдҪ•дҪҝз”ЁhadoopжқҘжҸҗеҸ–ж–Ү件дёӯзҡ„жҢҮе®ҡеҶ…е®№
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іеҰӮдҪ•дҪҝз”ЁhadoopжқҘжҸҗеҸ–ж–Ү件дёӯзҡ„жҢҮе®ҡеҶ…е®№пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒйңҖжұӮ
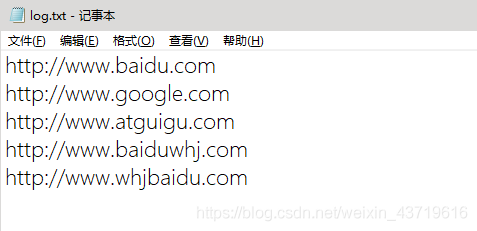
жҠҠд»ҘдёӢtxtдёӯеҗ«вҖңbaiduвҖқеӯ—з¬ҰдёІзҡ„й“ҫжҺҘиҫ“еҮәеҲ°дёҖдёӘж–Ү件пјҢеҗҰеҲҷиҫ“еҮәеҲ°еҸҰеӨ–дёҖдёӘж–Ү件гҖӮ
дәҢгҖҒжӯҘйӘӨ
1.LogMapper.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable,Text,Text,NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// дёҚеҒҡд»»дҪ•еӨ„зҗҶ
context.write(value,NullWritable.get());
}
}2.LogReducer.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class LogReducer extends Reducer<Text,NullWritable,Text,NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
for (NullWritable value : values) {
context.write(key,NullWritable.get());
}
}
}3.LogOutputFormat.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogOutputFormat extends FileOutputFormat<Text,NullWritable> {
@Override
public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext job) throws IOException, InterruptedException {
LogRecordWriter lrw = new LogRecordWriter(job);
return lrw;
}
}4.LogRecordWriter.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import java.io.IOException;
public class LogRecordWriter extends RecordWriter<Text,NullWritable> {
private FSDataOutputStream baiduOut;//ctrl+alt+f
private FSDataOutputStream otherOut;
public LogRecordWriter(TaskAttemptContext job) throws IOException {
//еҲӣе»әдёӨжқЎжөҒ
FileSystem fs = FileSystem.get(job.getConfiguration());
baiduOut = fs.create(new Path("D:\\temp\\outputformat.log"));
otherOut = fs.create(new Path("D:\\temp\\other.log"));
}
@Override
public void write(Text key, NullWritable nullWritable) throws IOException, InterruptedException {
// е…·дҪ“еҶҷ
String log = key.toString();
if(log.contains("baidu")){
baiduOut.writeBytes(log+"\n");
}else{
otherOut.writeBytes(log+"\n");
}
}
@Override
public void close(TaskAttemptContext taskAttemptContext) throws IOException, InterruptedException {
//е…іжөҒ
IOUtils.closeStream(baiduOut);
IOUtils.closeStream(otherOut);
}
}5.LogDriver.java
package com.whj.mapreduce.outputformat;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setReducerClass(LogReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//и®ҫзҪ®иҮӘе®ҡд№үзҡ„ outputformat
job.setOutputFormatClass(LogOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path("D:\\input"));
// иҷҪ 然 жҲ‘ 们 иҮӘ е®ҡ д№ү дәҶ outputformat пјҢ дҪҶ жҳҜ еӣ дёә жҲ‘ 们 зҡ„ outputformat 继жүҝиҮӘfileoutputformat
//иҖҢ fileoutputformat иҰҒиҫ“еҮәдёҖдёӘ_SUCCESS ж–Ү件пјҢжүҖд»ҘеңЁиҝҷиҝҳеҫ—жҢҮе®ҡдёҖдёӘиҫ“еҮәзӣ®еҪ•
FileOutputFormat.setOutputPath(job, new Path("D:\\temp\\logoutput"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
} }дёүгҖҒз»“жһң
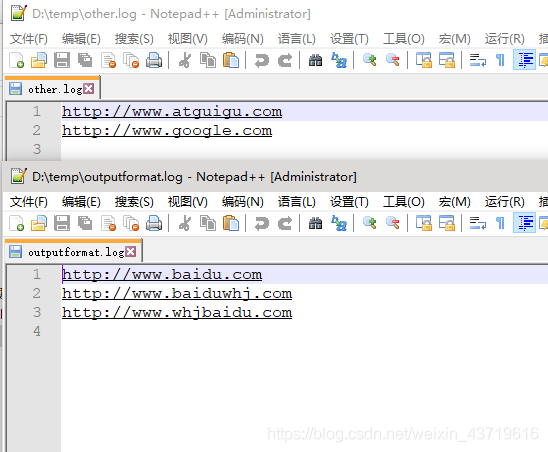
е…ідәҺвҖңеҰӮдҪ•дҪҝз”ЁhadoopжқҘжҸҗеҸ–ж–Ү件дёӯзҡ„жҢҮе®ҡеҶ…е®№вҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ





