YOLOv2检测过程的Tensorflow实现是怎样的,很多新手对此不是很清楚,为了帮助大家解决这个难题,下面小编将为大家详细讲解,有这方面需求的人可以来学习下,希望你能有所收获。
一、全部代码解读如下:
1、model_darknet19.py:yolo2网络模型——darknet19。
YOLOv2采用了一个新的基础模型(特征提取器),称为Darknet-19,包括19个卷积层和5个maxpooling层,如下图。Darknet-19与VGG16模型设计原则是一致的,主要采用3*3卷积,采用2*2的maxpooling层之后,特征图维度降低2倍,而同时将特征图的channles增加两倍。
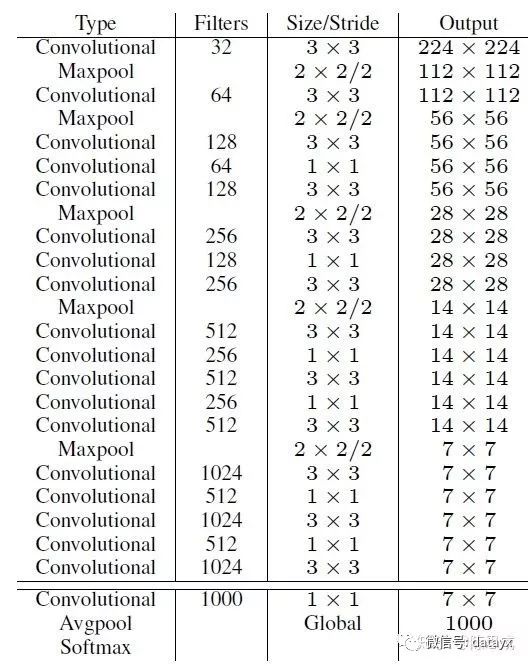
主要特点有:
(1)去掉了全连接层fc
·这样大大减少了网络的参数,个人理解这是yolo2可以增加每个cell产生边界框以及每个边界框能够单独的对应一组类别概率的原因。
·并且,网络下采样是32倍,这样也使得网络可以接收任意尺寸的图片,所以yolo2有了Multi-Scale Training多尺度训练的改进:输入图片resize到不同的尺寸(论文中选用320,352...,608十个尺寸,下采样32倍对应10*10~19*19的特征图)。每训练10个epoch,将图片resize到另一个不同的尺寸再训练。这样一个模型可以适应不同的输入图片尺寸,输入图像大(608*608)精度高速度稍慢、输入图片小(320*320)精度稍低速度快,增加了模型对不同尺寸图片输入的鲁棒性。
(2)在每个卷积层后面都加入一个BN层并不再使用droput
·这样提升模型收敛速度,而且可以起到一定正则化效果,降低模型的过拟合。
(3)采用跨层连接Fine-Grained Features
·YOLOv2的输入图片大小为416*416,经过5次maxpooling(下采样32倍)之后得到13*13大小的特征图,并以此特征图采用卷积做预测。这样会导致小的目标物体经过5层maxpooling之后特征基本没有了。所以yolo2引入passthrough层:前面的特征图维度是后面的特征图的2倍,passthrough层抽取前面层的每个2*2的局部区域,然后将其转化为channel维度,对于26*26*512的特征图,经passthrough层处理之后就变成了13*13*2048的新特征图,这样就可以与后面的13*13*1024特征图连接在一起形成13*13*3072大小的特征图,然后在此特征图基础上卷积做预测。作者在后期的实现中借鉴了ResNet网络,不是直接对高分辨特征图处理,而是增加了一个中间卷积层,先采用64个1*1卷积核进行卷积,然后再进行passthrough处理,这样26*26*512的特征图得到13*13*256的特征图。这算是实现上的一个小细节。
2、decode.py:解码darknet19网络得到的参数.

3、utils.py:功能函数,包含:预处理输入图片、筛选边界框NMS、绘制筛选后的边界框。
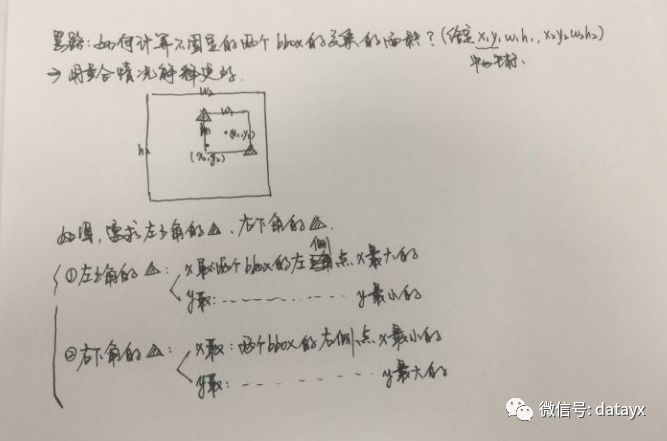
这里着重介绍NMS中IOU计算方式:yolo2中计算IOU只考虑形状,先将anchor与ground truth的中心点都偏移到同一位置(cell左上角),然后计算出对应的IOU值。
IOU计算难点在于计算交集大小:首先要判断是否有交集,然后再计算IOU。计算时候有一个trick,只计算交集部分的左上角和右下角坐标即可,通过取max和min计算:
4、Main.py:YOLO_v2主函数
对应程序有三个步骤:
(1)输入图片进入darknet19网络得到特征图,并进行解码得到:xmin xmax表示的边界框、置信度、类别概率
(2)筛选解码后的回归边界框——NMS
(3)绘制筛选后的边界框
Python3 + Tensorflow1.5 + OpenCV-python3.3.1 + Numpy1.13
windows和ubuntu环境都可以
请在yolo2检测模型下载模型,并放到yolo2_model文件夹下
https://pan.baidu.com/s/1ZeT5HerjQxyUZ_L9d3X52w
1、model_darknet19.py:yolo2网络模型——darknet19
2、decode.py:解码darknet19网络得到的参数
3、utils.py:功能函数,包含:预处理输入图片、筛选边界框NMS、绘制筛选后的边界框
4、config.py:配置文件,包含anchor尺寸、coco数据集的80个classes类别名称
5、Main.py:YOLO_v2主函数,对应程序有三个步骤:
(1)输入图片进入darknet19网络得到特征图,并进行解码得到:xmin xmax表示的边界框、置信度、类别概率
(2)筛选解码后的回归边界框——NMS
(3)绘制筛选后的边界框
6、Loss.py:Yolo_v2 Loss损失函数(train时候用,预测时候没有调用此程序)
(1)IOU值最大的那个anchor与ground truth匹配,对应的预测框用来预测这个ground truth:计算xywh、置信度c(目标值为1)、类别概率p误差。
(2)IOU小于某阈值的anchor对应的预测框:只计算置信度c(目标值为0)误差。
(3)剩下IOU大于某阈值但不是max的anchor对应的预测框:丢弃,不计算任何误差。
7、yolo2_data文件夹:包含待检测输入图片car.jpg、检测后的输出图片detection.jpg、coco数据集80个类别名称coco_classes.txt
1、car.jpg:输入的待检测图片

2、detected.jpg:检测结果可视化

可以看到,跟yolo1对比,yolo2引入anchor后检测精度有了提升(car和person的类别置信度高了许多),并且每个边界框对应一组类别概率解决了yolo1中多个目标中心点落在同一个cell只能检测一个物体的问题(左侧两个person都检测出来了)。相比yolo1还是有一定提升的。
看完上述内容是否对您有帮助呢?如果还想对相关知识有进一步的了解或阅读更多相关文章,请关注亿速云行业资讯频道,感谢您对亿速云的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





