zookeeper基本概念和功能
zookeeper是hadoop生态圈里面重要的底层的框架,主要为上层的框架提供分布式协调服务的。
hadoop-spof 问题及HA 解决思路
引入集群协调服务框架的必要性
zookeeper 简介
ZooKeeper 是一个分布式应用程序协调服务,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等。
目前zookeeper 被广泛应用于hadoop 生态体系中各种框架的分布式协调,我们也可以利用zookeeper 来简化分布式应用开发
Zk简介
1、zookeeper翻译成英文叫动物园管理员 动物员管理员的作用是什么呢??
2、让大象(hadoop),蜂巢(hive) ,猪(pig)能够更友好的在一起,以上几种都是hadoop的组件
3、ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务
4、zookeeper其实就是一个软件,所有安装了zookeeper的服务器都叫 zookeeper server
5、zookeeper server 还分为两类角色,由 leader 和 follower 组成,如果leader挂掉,会有选举机制,follower直接替换leader ,leader只有一个,剩下的都是follower
6、zookeeper 的所有服务器中的所有数据结构(树形结构)是完全相同的,就是说我搭建一个zookeeper集群,集群里面所有机器的数据是一样的
7、数据是树形结构的,与linux目录结构是一样一样的,zk的每个数据目录就是一个znode
8、我需要运行几个ZooKeeper? 你运行一个zookeeper也是可以的,但是在生产环境中,你最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个不是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳
zk对hdfs HA高可用集群的作用?
1、qjn集群(edit日志管理系统 HA的)需要zk集群去实现,协调服务。
2、namenode谁是active谁是standay 记录在zk中
3、zkfc就是基于zk实现的失败切换控制器
zk对yarn 集群HA的作用?
1、谁是recoursemanager active谁是从的RM 记录在zk中
基本同hdfs中在作用一样
zk对hbase集群HA的作用?
1、谁是hmaster记录在zk中
2、zk留存了服务器健康状态与是否可用的信息,并提供服务器故障通知,通过zookeeper cluster可以获取当前系统表.META.的存储所对应的regionserver信息。
3、zk用consensus协议来保障共享状态,需要注意的是,一份consensus协议需要3~5个机器参与(奇数个)。
//官方解释
1 保证任何时候,集群中只有一个master
2 存贮所有Region 的寻址入口。
3 实时监控Region Server 的状态,将Region server 的上线和下线信息实时通知给Master
4 存储Hbase 的schema(模式),包括有哪些table,每个table 有哪些column family
Zk对kafka集群的作用?
1.当一个kafka broker启动后,首先会向zookeeper注册自己的节点信息(临时znode),同时当broker和zookeeper断开连接时,此znode也会被删除.
2.其中partition leader的位置(host:port)注册在zookeeper中
3.对于offset的保存和使用,有consumer来控制 offset将会保存在zookeeper中。
小结:
Zookeeper(第三方) 可以实现的分布式协调服务包括:
1、统一名称服务 //如果把每台服务器sever比作一台一台的资源的,客户端拿到的就是名称服务资源。
2、配置管理
3、分布式共享锁 //比如在分布式的每台服务器上都需要去修改一个共享资源,这个时候会产生冲突,
4、集群节点状态协调(负载均衡/主从协调)//服务器集群动态感知及失败切换 zkfc
小结:这上面4点功能并不是zk本身自带的功能,而是,这些功能可以利用zk来实现。
zookeeper的功能:
也就是第三方,要你查数据的时候,可以返还给客户端,所以具体他是不知道干什么的
(最重要的功能也就是替客户端保管数据,为客户提供数据的监听服务)
内部自己设计了自己分布式内存数据库(用于保管数据)
ZooKeeper 数据模型和层次命名空间
提供的命名空间与标准的文件系统非常相似。一个名称是由通过斜线分隔开的路径名序列所组成的。ZooKeeper 中的每一个节点是都通过路径来识别。
ZooKeeper 中的数据节点:
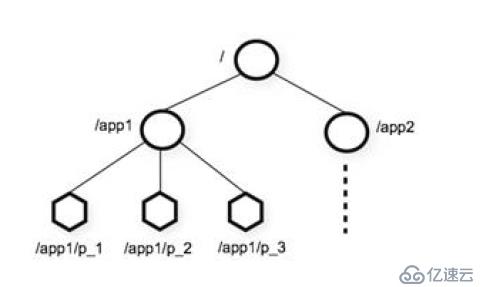
每一个节点称为znode,通过路径来访问
每一个znode 维护着:数据、stat 数据结构(ACL、时间戳及版本号)
znode 维护的数据主要是用于存储协调的数据,如状态、配置、位置等信息,每个节点存储的数据量很小,KB 级别
znode 的数据更新后,版本号等控制信息也会更新(增加)
znode 还具有原子性操作的特点:写--全部替换,读--全部
znode 有永久节点和临时节点之分:临时节点指创建它的session 一结束,该节点即被zookeeper 删除;
zk 性能:
Zookeeper 的读写速度非常快(基于内存数据库),并且读的速度要比写的速度更快。
顺序一致性:客户端的更新顺序与它们被发送的顺序相一致。
原子性:更新操作要么成功要么失败,没有第三种结果。
单系统镜像:无论客户端连接到哪一个服务器,客户端将看到相同的
ZooKeeper 视图。
可靠性:一旦一个更新操作被应用,那么在客户端再次更新它之前,它的值将不会改变。这个保证将会产生下面两种结果:
1 .如果客户端成功地获得了正确的返回代码,那么说明更新已经成功。如果不能够获得返回代码(由于通信错误、超时等等),那么客户端将不知道更新操作是否生效。
2 .当从故障恢复的时候,任何客户端能够看到的执行成功的更新操作将不会被回滚。
实时性:在特定的一段时间内,客户端看到的系统需要被保证是实时的。在此时间段内,任何系统的改变将被客户端看到,或者被客户端侦测到。给予这些一致性保证,ZooKeeper 更高级功能的设计与实现将会变得非常容易,
例如: leader 选举、队列以及可撤销锁等机制的实现。
zookeeper 集群组件:
同一个zookeeper服务下的server 有三种,一种是leader server,另一种是follower server,还有一种叫observer server;
leader特殊之处在于它有决定权,具有Request Processor(observer server 与follower server 的区别就在于不参与leader 选举)
zk中内部leader选举的算法:paxos
如果客户端修改zk集群中的数据的时候,首先集群中会找到leader 然后在leader上修改本地数据,然后每台follower会去同步信息
zk中的端口意思
(其中2181代表:客户端与服务器连接所用的端口)
(其中2888代表:leader与follower之间的通信用的端口)
(其中3888代表:follower之间选举投票用的端口)
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





