今天小编给大家分享一下DQN与PG多角度实例比较分析的相关知识点,内容详细,逻辑清晰,相信大部分人都还太了解这方面的知识,所以分享这篇文章给大家参考一下,希望大家阅读完这篇文章后有所收获,下面我们一起来了解一下吧。
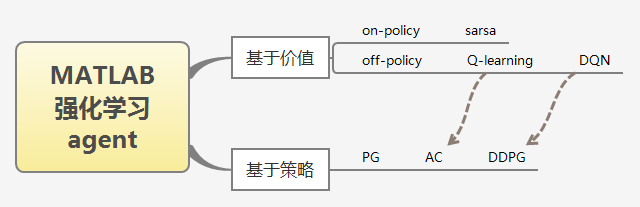
首先是原理上的对比,强化学习研究的目标是训练出一个对应于具体任务的好模型,这两个训练策略的方法是不同的。DQN基于值的方法,简单说就是先学出个值函数 ,然后通过值函数确定策略。而PG基于策略的方法则是,直接通过一个目标函数去训练出一个策略
接下来是网络模型上的不同,在MATLAB中DQN方法需要的模型是这样的
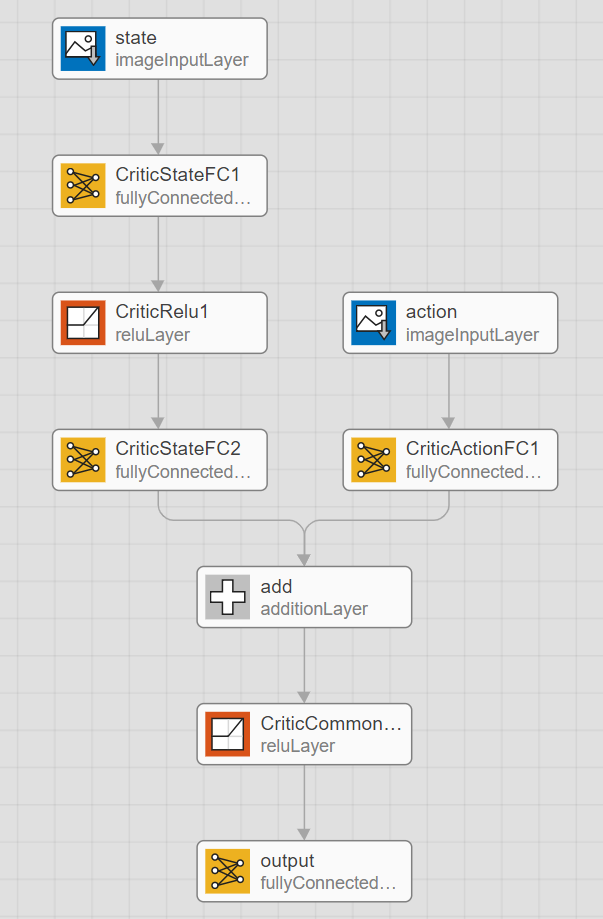
每一步的state和action一起作为输入进入网络,最后输出的是下一步action的值,和模型接受的动作对应,比如迷宫环境中的表示向上的1,rlDQNAgent模型把1施加给环境
再看PG方法的模型
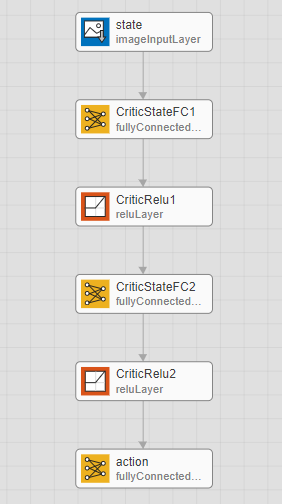
只要state作为输入,经过网络的运算后输出的是下一步的action,和模型的actionInfo对应,rlPGAgent分析后取出需要执行的动作再和环境交互
最后看的是训练过程,同样的简单平衡维持环境,DQN训练时reward变化是这样的
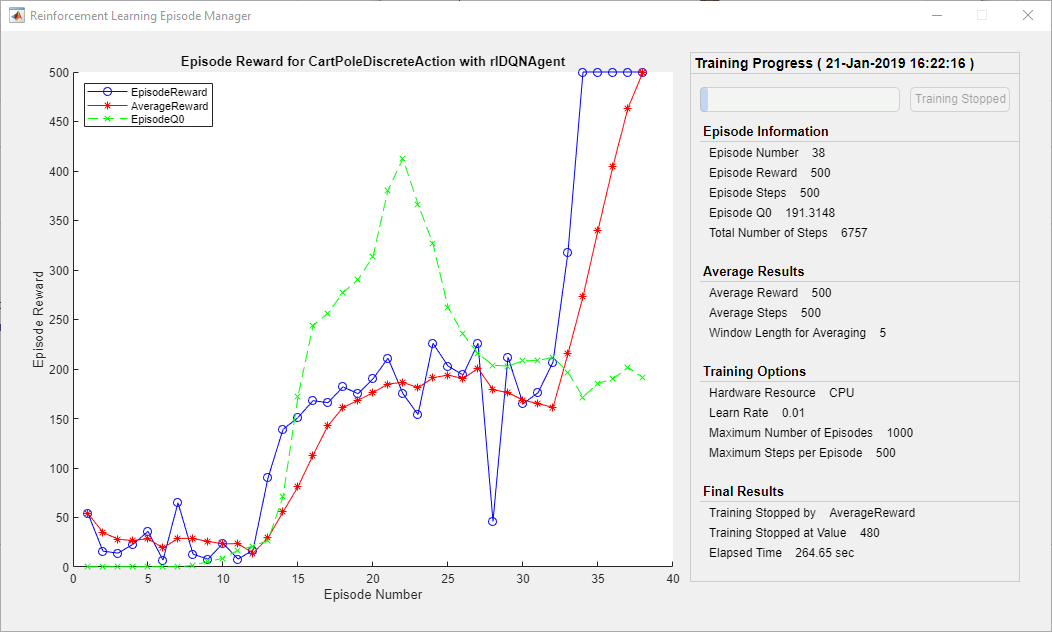
而PG训练需要更多次
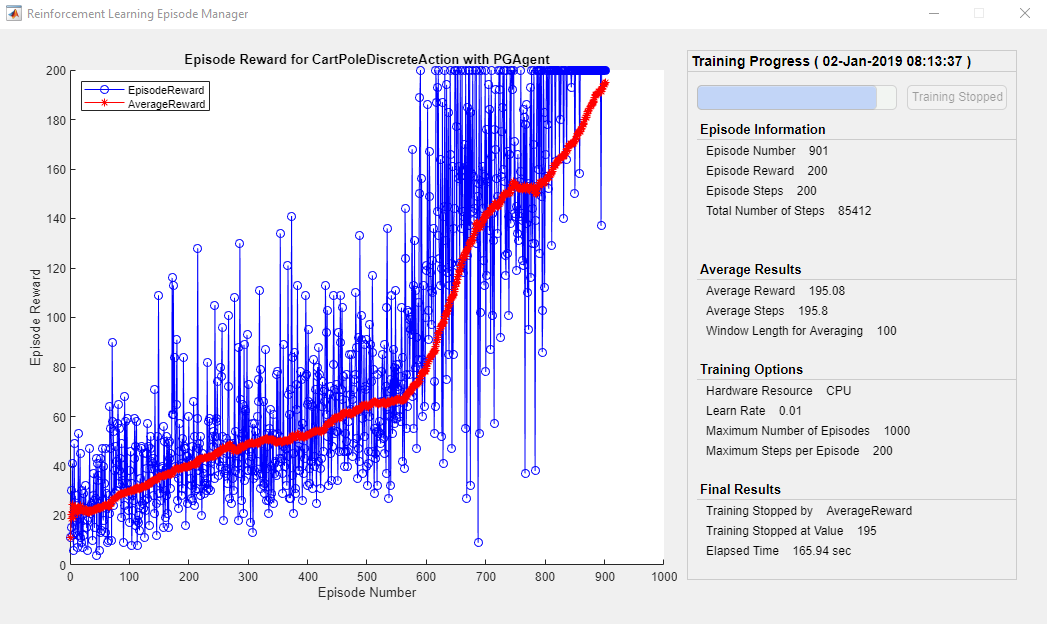
这个对比只是直观指出不同,可能PG方法并不适合这样的环境,这里主要记录的是两个方法的输入输出,在下次建立模型的时候可以参考:
DQN的输入是state和action一起,输出对应的是action的确切值
PG的输入是state,输出对应的是env的ActionInfo
以上就是“DQN与PG多角度实例比较分析”这篇文章的所有内容,感谢各位的阅读!相信大家阅读完这篇文章都有很大的收获,小编每天都会为大家更新不同的知识,如果还想学习更多的知识,请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





