本篇文章给大家分享的是有关怎么进行Spark WC开发与应用部署的分析,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
Spark WordCount开发
创建的是maven工程,使用的依赖如下:
<dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.10.5</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.2</version> </dependency>
package cn.xpleaf.bigdata.spark.java.core.p1;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* spark Core 开发
*
* 基于Java
* 计算国际惯例
*
* Spark程序的入口:
* SparkContext
* Java:JavaSparkContext
* scala:SparkContext
*
* D:/data\spark\hello.txt
*
* spark RDD的操作分为两种,第一为Transformation,第二为Action
* 我们将Transformation称作转换算子,Action称作Action算子
* Transformation算子常见的有:map flatMap reduceByKey groupByKey filter...
* Action常见的有:foreach collect count save等等
*
* Transformation算子是懒加载的,其执行需要Action算子的触发
* (可以参考下面的代码,只要foreach不执行,即使中间RDD的操作函数有异常也不会报错,因为其只是加载到内存中,并没有真正执行)
*/
public class _01SparkWordCountOps {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName(_01SparkWordCountOps.class.getSimpleName());
/**
* sparkConf中设置的master选择,
* local
* local
* spark作业在本地执行,为该spark作业分配一个工作线程
* local[N]
* spark作业在本地执行,为该spark作业分配N个工作线程
* local[*]
* spark作业在本地执行,根据机器的硬件资源,为spark分配适合的工作线程,一般也就2个
* local[N, M]
* local[N, M]和上面最大的区别就是,当spark作业启动或者提交失败之后,可以有M次重试的机会,上面几种没有
* standalone模式:
* 就是spark集群中master的地址,spark://uplooking01:7077
* yarn
* yarn-cluster
* 基于yarn的集群模式,sparkContext的构建和作业的运行都在yarn集群中执行
* yarn-client
* 基于yarn的client模式,sparkContext的构建在本地,作业的运行在集群
*
* mesos
* mesos-cluster
* mesos-client
*/
String master = "local[*]";
conf.setMaster(master);
JavaSparkContext jsc = new JavaSparkContext(conf);
Integer defaultParallelism = jsc.defaultParallelism();
System.out.println("defaultParallelism=" + defaultParallelism);
/**
* 下面的操作代码,其实就是spark中RDD的DAG图
*/
JavaRDD<String> linesRDD = jsc.textFile("D:/data/spark/hello.txt");
System.out.println("linesRDD's partition size is: " + linesRDD.partitions().size());
JavaRDD<String> wordsRDD = linesRDD.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String line) throws Exception {
// int i = 1 / 0; // 用以验证Transformation算子的懒加载
return Arrays.asList(line.split(" "));
}
});
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String, Integer>(word, 1);
}
});
JavaPairRDD<String, Integer> retRDD = pairRDD.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println("retRDD's partition size is: " + retRDD.partitions().size());
retRDD.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> tuple) throws Exception {
System.out.println(tuple._1 + "---" + tuple._2);
}
});
jsc.close();
}
}本地执行,输出结果如下:
defaultParallelism=20 ...... linesRDD's partition size is: 2 retRDD's partition size is: 2 ...... hello---3 you---1 me---1 he---1
package cn.xpleaf.bigdata.spark.java.core.p1;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
import java.util.Arrays;
/**
* spark Core 开发
*
* 基于Java
* 计算国际惯例
*
* Spark程序的入口:
* SparkContext
* Java:JavaSparkContext
* scala:SparkContext
*
* D:/data\spark\hello.txt
*
* lambda表达式的版本
*/
public class _02SparkWordCountOps {
public static void main(String[] args) {
SparkConf conf = new SparkConf();
conf.setAppName(_02SparkWordCountOps.class.getSimpleName());
String master = "local";
conf.setMaster(master);
JavaSparkContext jsc = new JavaSparkContext(conf);
/**
* 下面的操作代码,其实就是spark中RDD的DAG图
* 现在使用lambda表达式,更加简单清晰
*/
JavaRDD<String> linesRDD = jsc.textFile("D:/data/spark/hello.txt");
JavaRDD<String> wordsRDD = linesRDD.flatMap(line -> {return Arrays.asList(line.split(" "));});
JavaPairRDD<String, Integer> pairRDD = wordsRDD.mapToPair(word -> {return new Tuple2<String, Integer>(word, 1);});
JavaPairRDD<String, Integer> retRDD = pairRDD.reduceByKey((v1, v2) -> {return v1 + v2;});
retRDD.foreach(tuple -> {
System.out.println(tuple._1 + "---" + tuple._2);
});
jsc.close();
}
}本地执行,输出结果如下:
you---1 he---1 hello---3 me---1
package cn.xpleaf.bigdata.spark.scala.core.p1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Scala的WordCount统计
*
* java.net.UnknownHostException: ns1
*
* spark系统不认识ns1
* 在spark的配置文件spark-defaults.conf中添加:
* spark.files /home/uplooking/app/hadoop/etc/hadoop/hdfs-site.xml,/home/uplooking/app/hadoop/etc/hadoop/core-site.xml
*/
object _01SparkWordCountOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_01SparkWordCountOps.getClass().getSimpleName}")
.setMaster("local")
val sc = new SparkContext(conf)
val linesRDD:RDD[String] = sc.textFile("D:/data/spark/hello.txt")
/*val wordsRDD:RDD[String] = linesRDD.flatMap(line => line.split(" "))
val parsRDD:RDD[(String, Int)] = wordsRDD.map(word => new Tuple2[String, Int](word, 1))
val retRDD:RDD[(String, Int)] = parsRDD.reduceByKey((v1, v2) => v1 + v2)
retRDD.collect().foreach(t => println(t._1 + "..." + t._2))*/
// 更简洁的方式
linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(t => println(t._1 + "..." + t._2))
sc.stop()
}
}本地执行,输出结果如下:
you...1 he...1 hello...3 me...1
上面的方式其实都是本地执行的,可以把我们的应用部署到Spark集群或Yarn集群上,前面的代码注释也有提到这一点,就是关于Spark作业执行的问题:
/** * sparkConf中设置的master选择, * local * local * spark作业在本地执行,为该spark作业分配一个工作线程 * local[N] * spark作业在本地执行,为该spark作业分配N个工作线程 * local[*] * spark作业在本地执行,根据机器的硬件资源,为spark分配适合的工作线程,一般也就2个 * local[N, M] * local[N, M]和上面最大的区别就是,当spark作业启动或者提交失败之后,可以有M次重试的机会,上面几种没有 * standalone模式: * 就是spark集群中master的地址,spark://uplooking01:7077 * yarn * yarn-cluster * 基于yarn的集群模式,sparkContext的构建和作业的运行都在yarn集群中执行 * yarn-client * 基于yarn的client模式,sparkContext的构建在本地,作业的运行在集群 * * mesos * mesos-cluster * mesos-client */
local的多种情况可以自己测试一下。
这里只测试部署standalone和yarn-cluster两种模式,实际上yarn-client也测试了,不过报异常,没去折腾。注意用的是Scala的代码。
其实很显然,这里使用的是Spark离线计算的功能(Spark Core)。
将前面的scala版本的代码修改为如下:
package cn.xpleaf.bigdata.spark.scala.core.p1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Scala的WordCount统计
*
* java.net.UnknownHostException: ns1
*
* spark系统不认识ns1
* 在spark的配置文件spark-defaults.conf中添加:
* spark.files /home/uplooking/app/hadoop/etc/hadoop/hdfs-site.xml,/home/uplooking/app/hadoop/etc/hadoop/core-site.xml
*/
object _01SparkWordCountOps {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName(s"${_01SparkWordCountOps.getClass().getSimpleName}")
//.setMaster("local")
val sc = new SparkContext(conf)
val linesRDD:RDD[String] = sc.textFile("hdfs://ns1/hello")
/*val wordsRDD:RDD[String] = linesRDD.flatMap(line => line.split(" "))
val parsRDD:RDD[(String, Int)] = wordsRDD.map(word => new Tuple2[String, Int](word, 1))
val retRDD:RDD[(String, Int)] = parsRDD.reduceByKey((v1, v2) => v1 + v2)
retRDD.collect().foreach(t => println(t._1 + "..." + t._2))*/
// 更简洁的方式
linesRDD.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).collect().foreach(t => println(t._1 + "..." + t._2))
// collect不是必须要加的,但是如果在standalone的运行模式下,不加就看不到控制台的输出
// 而在yarn运行模式下,是看不到输出的
sc.stop()
}
}主要是做了两处的修改,一是注释掉setMaster("local"),因为现在不是本地跑了,另外是数据来源,选择的是HDFS上的数据文件。
需要注意的是,要想让Spark集群认识ns1(我的Hadoop集群是HA部署方式),其实有两种方式,一种设置环境变量HADOOP_CONF_DIR,但我测试的时候不生效,依然是无法识别ns1;另外一种是需要在Spark的配置文件spark-defaults.conf中添加spark.files /home/uplooking/app/hadoop/etc/hadoop/hdfs-site.xml,/home/uplooking/app/hadoop/etc/hadoop/core-site.xml,即指定Hadoop的配置文件地址,Hadoop HA的配置,就是在这两个文件中进行的配置。我采用第二种方式有效。
上面准备工作完成后就可以将程序打包了,使用普通的打包或者maven打包都可以,注意不需要将依赖一起打包,因为我们的Spark集群环境中已经存在这些依赖了。
关于应用的部署,准确来说是submit,官方文档有很详细的说明,可以参考:http://spark.apache.org/docs/latest/submitting-applications.html
先编写下面一个脚本:
[uplooking@uplooking01 spark]$ cat spark-submit-standalone.sh #export HADOOP_CONF_DIR=/home/uplooking/app/hadoop/etc/hadoop /home/uplooking/app/spark/bin/spark-submit \ --class $2 \ --master spark://uplooking01:7077 \ --executor-memory 1G \ --num-executors 1 \ $1 \
然后执行下面的命令:
[uplooking@uplooking01 spark]$ ./spark-submit-standalone.sh spark-wc.jar cn.xpleaf.bigdata.spark.scala.core.p1._01SparkWordCountOps
因为在程序代码中已经添加了collect Action算子,所以运行成功后可以直接在控制台中看到输出结果:
hello...3 me...1 you...1 he...1
然后也可以在spark提供的UI界面中看到其提交的作业以及执行结果:

先编写下面一个脚本:
[uplooking@uplooking01 spark]$ cat spark-submit-yarn.sh #export HADOOP_CONF_DIR=/home/uplooking/app/hadoop/etc/hadoop /home/uplooking/app/spark/bin/spark-submit \ --class $2 \ --master yarn \ --deploy-mode cluster \ --executor-memory 1G \ --num-executors 1 \ $1 \
执行如下命令:
[uplooking@uplooking01 spark]$ ./spark-submit-yarn.sh spark-wc.jar cn.xpleaf.bigdata.spark.scala.core.p1._01SparkWordCountOps 18/04/25 17:47:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 18/04/25 17:47:39 INFO yarn.Client: Requesting a new application from cluster with 2 NodeManagers 18/04/25 17:47:39 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container) 18/04/25 17:47:39 INFO yarn.Client: Will allocate AM container, with 1408 MB memory including 384 MB overhead 18/04/25 17:47:39 INFO yarn.Client: Setting up container launch context for our AM 18/04/25 17:47:39 INFO yarn.Client: Setting up the launch environment for our AM container 18/04/25 17:47:39 INFO yarn.Client: Preparing resources for our AM container 18/04/25 17:47:40 INFO yarn.Client: Uploading resource file:/home/uplooking/app/spark/lib/spark-assembly-1.6.2-hadoop2.6.0.jar -> hdfs://ns1/user/uplooking/.sparkStaging/application_1524552224611_0005/spark-assembly-1.6.2-hadoop2.6.0.jar 18/04/25 17:47:42 INFO yarn.Client: Uploading resource file:/home/uplooking/jars/spark/spark-wc.jar -> hdfs://ns1/user/uplooking/.sparkStaging/application_1524552224611_0005/spark-wc.jar 18/04/25 17:47:42 INFO yarn.Client: Uploading resource file:/tmp/spark-ae34fa23-5166-4fd3-a4ec-8e5115691801/__spark_conf__6834084285342234312.zip -> hdfs://ns1/user/uplooking/.sparkStaging/application_1524552224611_0005/__spark_conf__6834084285342234312.zip 18/04/25 17:47:43 INFO spark.SecurityManager: Changing view acls to: uplooking 18/04/25 17:47:43 INFO spark.SecurityManager: Changing modify acls to: uplooking 18/04/25 17:47:43 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(uplooking); users with modify permissions: Set(uplooking) 18/04/25 17:47:43 INFO yarn.Client: Submitting application 5 to ResourceManager 18/04/25 17:47:43 INFO impl.YarnClientImpl: Submitted application application_1524552224611_0005 18/04/25 17:47:44 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:44 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: default start time: 1524649663869 final status: UNDEFINED tracking URL: http://uplooking02:8088/proxy/application_1524552224611_0005/ user: uplooking 18/04/25 17:47:45 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:46 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:47 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:48 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:49 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:50 INFO yarn.Client: Application report for application_1524552224611_0005 (state: ACCEPTED) 18/04/25 17:47:51 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:51 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.43.103 ApplicationMaster RPC port: 0 queue: default start time: 1524649663869 final status: UNDEFINED tracking URL: http://uplooking02:8088/proxy/application_1524552224611_0005/ user: uplooking 18/04/25 17:47:52 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:53 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:54 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:55 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:56 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:57 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:58 INFO yarn.Client: Application report for application_1524552224611_0005 (state: RUNNING) 18/04/25 17:47:59 INFO yarn.Client: Application report for application_1524552224611_0005 (state: FINISHED) 18/04/25 17:47:59 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.43.103 ApplicationMaster RPC port: 0 queue: default start time: 1524649663869 final status: SUCCEEDED tracking URL: http://uplooking02:8088/proxy/application_1524552224611_0005/ user: uplooking 18/04/25 17:47:59 INFO util.ShutdownHookManager: Shutdown hook called 18/04/25 17:47:59 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-ae34fa23-5166-4fd3-a4ec-8e5115691801
可以通过yarn提供的Web界面来查看其提交的作业情况:

但是找了日志也没有找到输出的统计结果,所以这种情况下,数据结果的落地就不应该只是输出而已了,可以考虑其它的持久化存储。
总体而言,对比MapReduce,仅仅从Spark Core来看,速度真的是有非常大的提高。
参考下面的图示:
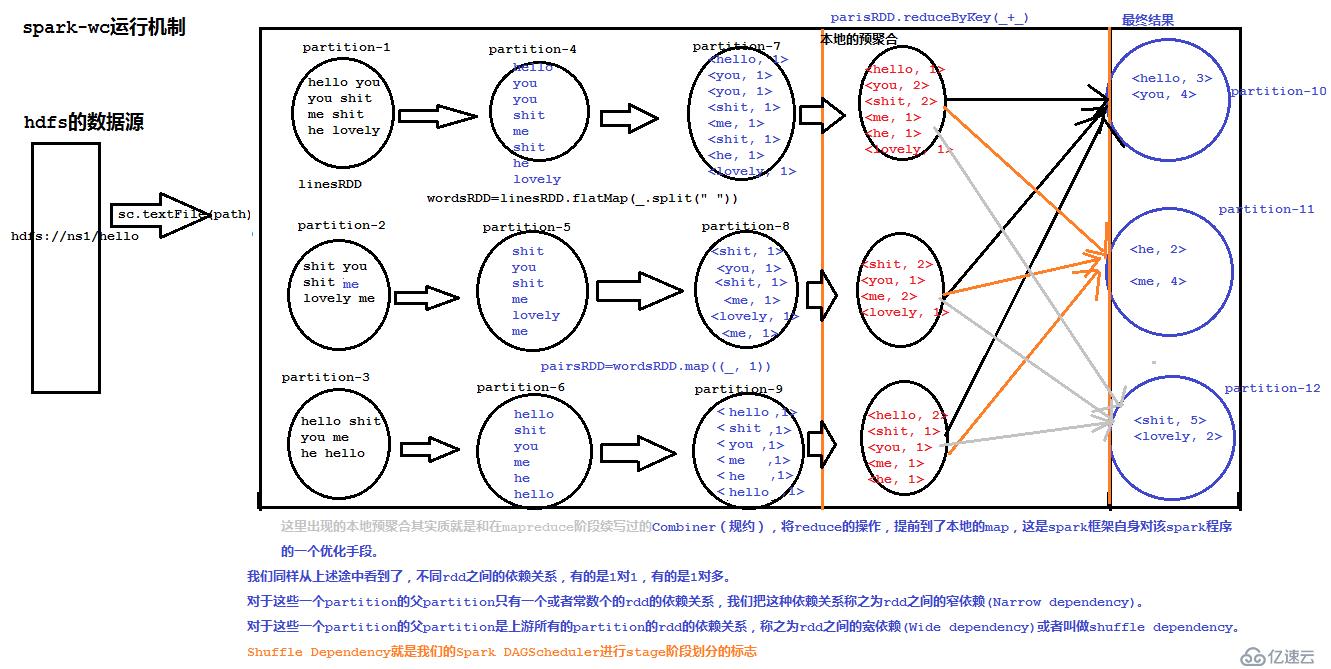
然后,下面是我跑的一个wordcount任务,在spark history server中查看其详细信息,就很容易理解上面所说的stage划分、宽依赖、窄依赖,相信会有一个相对比较清晰的认识: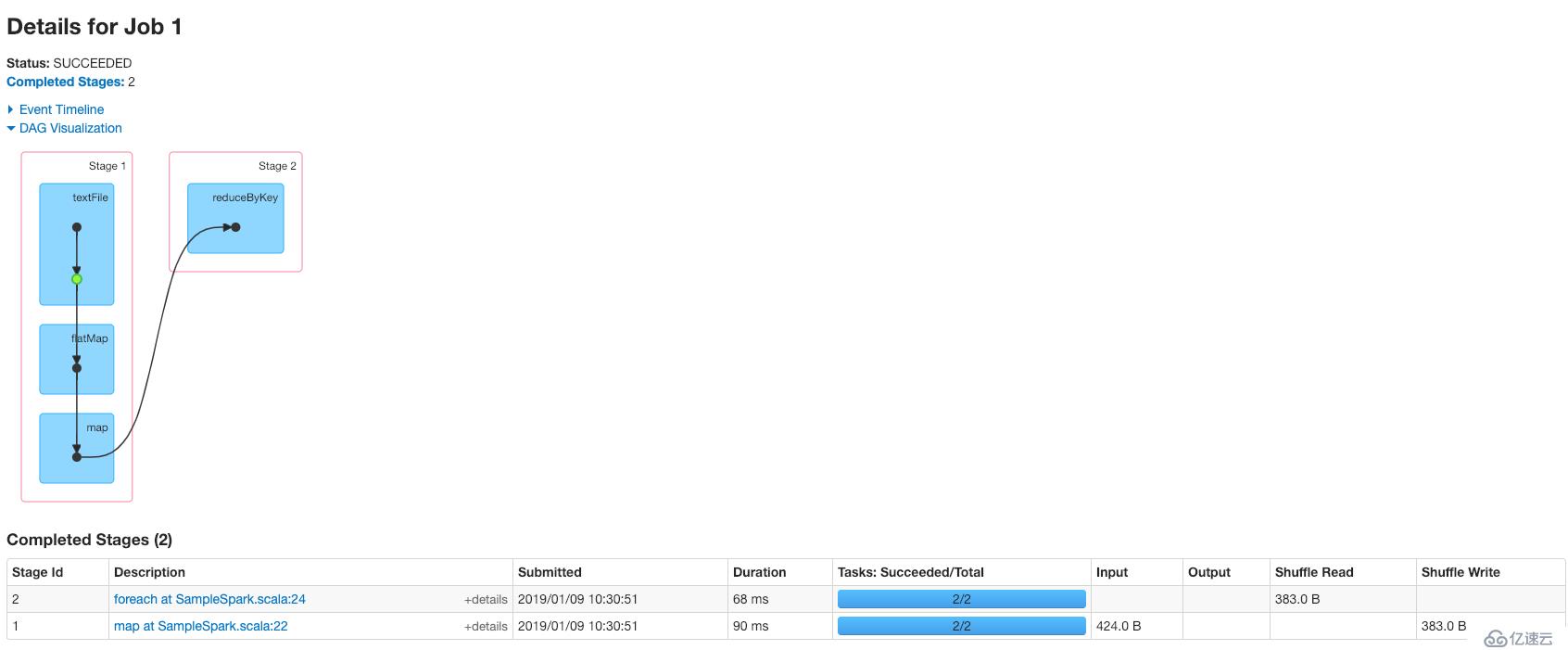
以上就是怎么进行Spark WC开发与应用部署的分析,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





