小编给大家分享一下Python Requests爬虫中如何求取关键词页面,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
import requestsif __name__=='__main__': #step 1:搜索Url url='https://123.sogou.com/' #step 2:发起请求 #get方法会返回一个响应对象 response=requests.get(url=url) #step 3:获取响应数据,text返回的是字符串形式的响应数据 page_text=response.text print(page_text) #step 4:持久化存储 with open('./sogou.html','w',encoding='utf-8') as fp: fp.write(page_text) print("爬取数据结束")import requests
if __name__=='__main__':
#step 1:搜索Url
url='https://123.sogou.com/'
#step 2:发起请求
#get方法会返回一个响应对象
response=requests.get(url=url)
#step 3:获取响应数据,text返回的是字符串形式的响应数据
page_text=response.text
print(page_text)
#step 4:持久化存储
with open('./sogou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
print("爬取数据结束")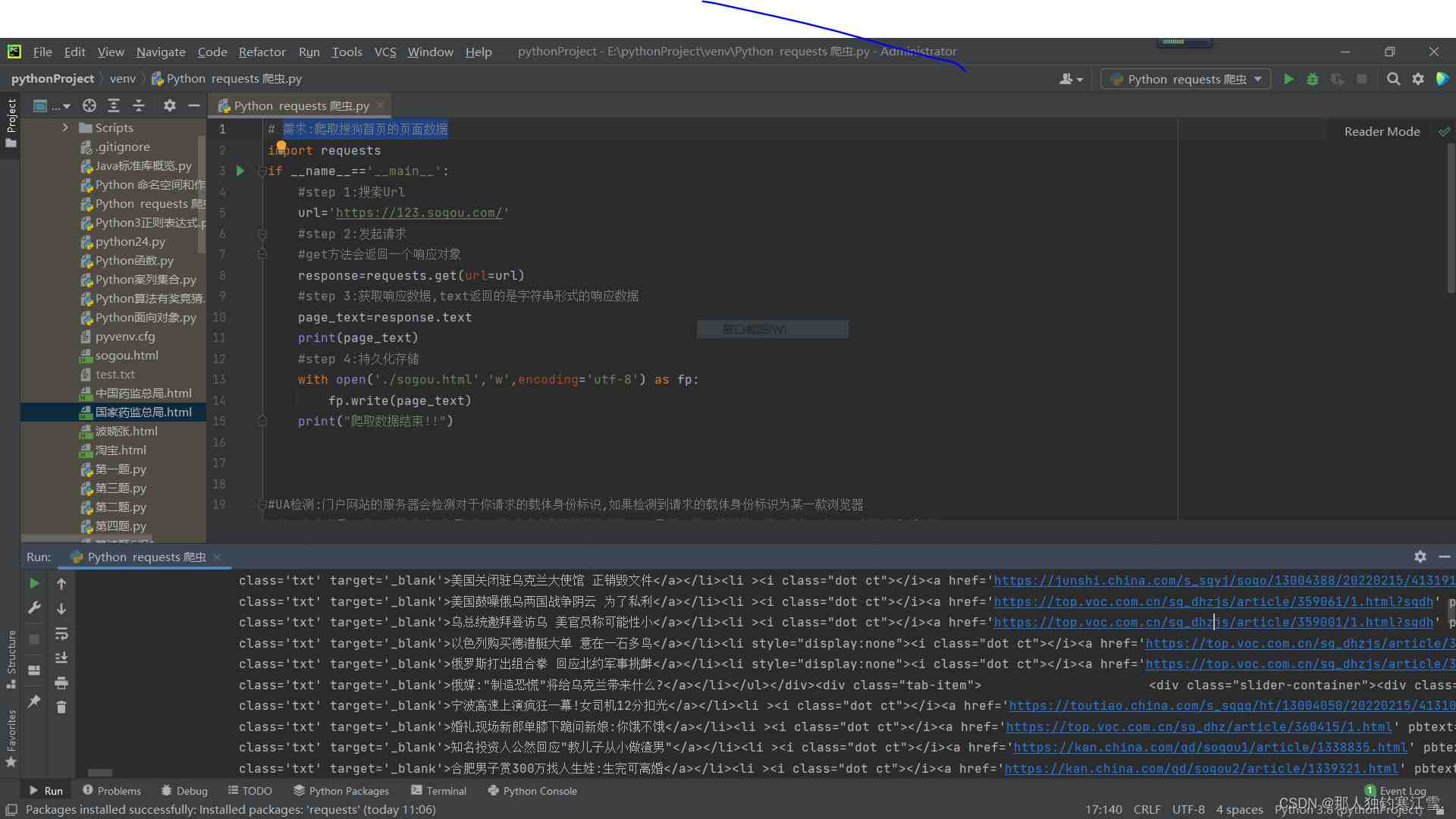
import requests
if __name__=='__main__':
#UA伪装:将对应的User-Agent封装到一个字典中
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.9 Safari/537.36'
}
url='https://www.sogou.com/sie?'
#处理url携带的参数:封装到字典中
kw=input('enter a word:')
param={
'query':kw
}
#对指定的url发起的请求对应的url是携带参数的,并且请求过程中处理了参数
response=requests.get(url=url,params=param,headers=headers)#headers是伪装 params输入关键词
page_text=response.text#以文本的形式输出
fileName=kw+'.html'#存储为网页形式
with open(fileName,'w+',encoding='utf-8') as fp:
fp.write(page_text)#写入fp
print(fileName,"保存成功!!")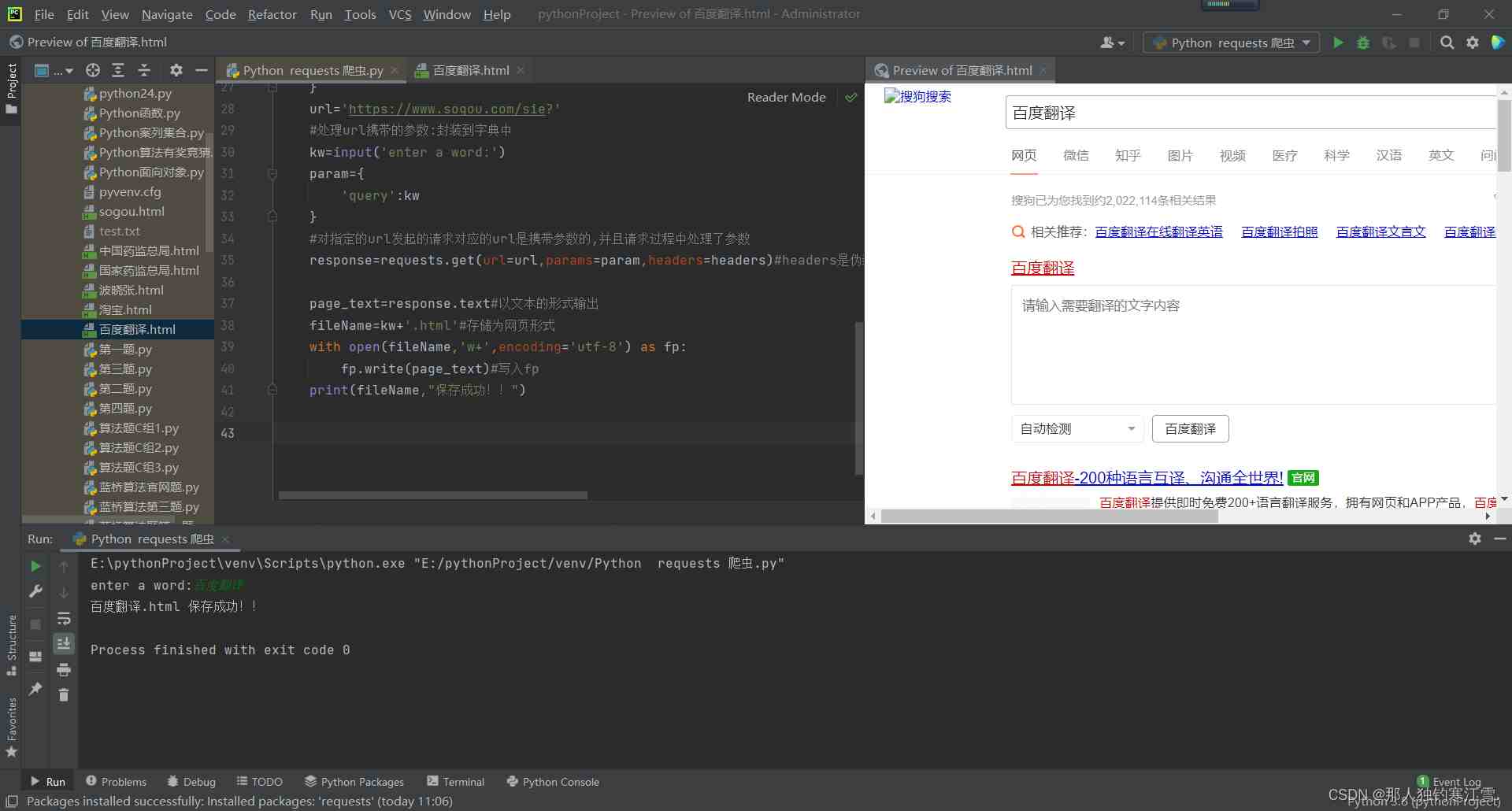
以上是“Python Requests爬虫中如何求取关键词页面”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





