本篇内容介绍了“分析Spring循环依赖的坑”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
1. 前言
这两天工作遇到了一个挺有意思的Spring循环依赖的问题,但是这个和以往遇到的循环依赖问题都不太一样,隐藏的相当隐蔽,网络上也很少看到有其他人遇到类似的问题。这里权且称他非典型Spring循环依赖问题。但是我相信我肯定不是第一个踩这个坑的,也一定不是最后一个,可能只是因为踩过的人比较少、鲜有记录罢了。因此这里权且记录一下这个坑,方便后人查看。
正如鲁迅(我)说过,“这个世上本没有坑,踩的人多了,也便成了坑”。
2. 典型场景
经常听很多人在Review别人代码的时候有如下的评论:“你在设计的时候这些类之间怎么能有循环依赖呢?你这样会报错的!”。
其实这句话前半句当然没有错,出现循环依赖的确是设计上的问题,理论上应当将循环依赖进行分层,抽取公共部分,然后由各个功能类再去依赖公共部分。
但是在复杂代码中,各个manager类互相调用太多,总会一不小心出现一些类之间的循环依赖的问题。可有时候我们又发现在用Spring进行依赖注入时,虽然Bean之间有循环依赖,但是代码本身却大概率能很正常的work,似乎也没有任何bug。
很多敏感的同学心里肯定有些犯嘀咕,循环依赖这种触犯因果律的事情怎么能发生呢?没错,这一切其实都并不是那么理所当然。
3. 什么是依赖
其实,不分场景地、笼统地说A依赖B其实是不够准确、至少是不够细致的。我们可以简单定义一下什么是依赖。
所谓A依赖B,可以理解为A中某些功能的实现是需要调用B中的其他功能配合实现的。这里也可以拆分为两层含义:
A强依赖B。创建A的实例这件事情本身需要B来参加。对照在现实生活就像妈妈生你一样。
A弱依赖B。创建A的实例这件事情不需要B来参加,但是A实现功能是需要调用B的方法。对照在现实生活就像男耕女织一样。
那么,所谓循环依赖,其实也有两层含义:
强依赖之间的循环依赖。
弱依赖之间的循环依赖。
讲到这一层,我想大家应该知道我想说什么了。
4. 什么是依赖调解
对于强依赖而言,A和B不能互相作为存在的前提,否则宇宙就爆炸了。因此这类依赖目前是无法调解的。
对于弱依赖而言,A和B的存在并没有前提关系,A和B只是互相合作。因此正常情况下是不会出现违反因果律的问题的。
那什么是循环依赖的调解呢?我的理解是:
将 原本是弱依赖关系的两者误当做是强依赖关系的做法 重新改回弱依赖关系的过程。
基于上面的分析,我们基本上也就知道Spring是怎么进行循环依赖调解的了(仅指弱依赖,强依赖的循环依赖只有上帝能自动调解)。
5. 为什么要依赖注入
网上经常看到很多手撸IOC容器的入门科普文,大部分人只是将IOC容器实现成一个“存储Bean的map”,将DI实现成“通过注解+反射将bean赋给类中的field”。实际上很多人都忽视了DI的依赖调解的功能。而帮助我们进行依赖调解本身就是我们使用IOC+DI的一个重要原因。
在没有依赖注入的年代里,很多人都会将类之间的依赖通过构造函数传递(实际上是构成了强依赖)。当项目越来越庞大时,非常容易出现无法调解的循环依赖。这时候开发人员就被迫必须进行重新抽象,非常麻烦。而事实上,我们之所以将原本的弱依赖弄成了强依赖,完全是因为我们将类的构造、类的配置、类的初始化逻辑三个功能耦合在构造函数之中。
而DI就是帮我们将构造函数的功能进行了解耦。
那么Spring是怎么进行解耦的呢?
6. Spring的依赖注入模型
这一部分网上有很多相关内容,我的理解大概是上面提到的三步:
类的构造,调用构造函数、解析强依赖(一般是无参构造),并创建类实例。
类的配置,根据Field/GetterSetter中的依赖注入相关注解、解析弱依赖,并填充所有需要注入的类。
类的初始化逻辑,调用生命周期中的初始化方法(例如@PostConstruct注解或InitializingBean的afterPropertiesSet方法),执行实际的初始化业务逻辑。
这样,构造函数的功能就由原来的三个弱化为了一个,只负责类的构造。并将类的配置交由DI,将类的初始化逻辑交给生命周期。
想到这一层,忽然解决了我堵在心头已久的问题。在刚开始学Spring的时候,我一直想不通:
为什么Spring除了构造函数之外还要在Bean生命周期里有一个额外的初始化方法?
这个初始化方法和构造函数到底有什么区别?
为什么Spring建议将初始化的逻辑写在生命周期里的初始化方法里?
现在,把依赖调解结合起来看,解释就十分清楚了:
为了进行依赖调解,Spring在调用构造函数时是没有将依赖注入进来的。也就是说构造函数中是无法使用通过DI注入进来的bean(或许可以,但是Spring并不保证这一点)。
如果不在构造函数中使用依赖注入的bean而仅仅使用构造函数中的参数,虽然没有问题,但是这就导致了这个bean强依赖于他的入参bean。当后续出现循环依赖时无法进行调解。
7. 非典型问题
结论?
根据上面的分析我们应该得到了以下共识:
通过构造函数传递依赖的做法是有可能造成无法自动调解的循环依赖的。
纯粹通过Field/GetterSetter进行依赖注入造成的循环依赖是完全可以被自动调解的。
因此这样我就得到了一个我认为正确的结论。这个结论屡试不爽,直到我发现了这次遇到的场景:
在Spring中对Bean进行依赖注入时,在纯粹只考虑循环依赖的情况下,只要不使用构造函数注入就永远不会产生无法调解的循环依赖。
当然,我没有任何“不建议使用构造器注入”的意思。相反,我认为能够“优雅地、不引入循环依赖地使用构造器注入”是一个要求更高的、更优雅的做法。贯彻这一做法需要有更高的抽象能力,并且会自然而然的使得各个功能解耦合。
问题
将实际遇到的问题简化后大概是下面的样子(下面的类在同一个包中):
@SpringBootApplication @Import({ServiceA.class, ConfigurationA.class, BeanB.class}) public class TestApplication { public static void main(String[] args) { SpringApplication.run(TestApplication.class, args); } }public class ServiceA { @Autowired private BeanA beanA; @Autowired private BeanB beanB; }public class ConfigurationA { @Autowired public BeanB beanB; @Bean public BeanA beanA() { return new BeanA(); } }public class BeanA { }public class BeanB { @Autowired public BeanA beanA; }首先声明一点,我没有用@Component、@Configuration之类的注解,而是采用@Import手动扫描Bean是为了方便指定Bean的初始化顺序。Spring会按照我@Import的顺序依次加载Bean。同时,在加载每个Bean的时候,如果这个Bean有需要注入的依赖,则会试图加载他依赖的Bean。
简单梳理一下,整个依赖链大概是这样:
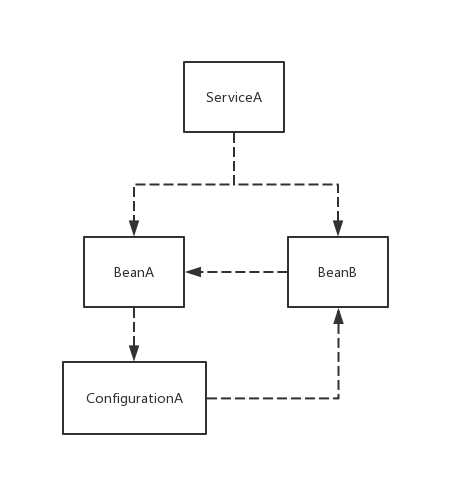
我们可以发现,BeanA,BeanB,ConfigurationA之间有一个循环依赖,不过莫慌,所有的依赖都是通过非构造函数注入的方式实现的,理论上似乎可以自动调解的。
但是实际上,这段代码会报下面的错:
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'beanA': Requested bean is currently in creation: Is there an unresolvable circular reference?
这显然是出现了Spring无法调解的循环依赖了。
这已经有点奇怪了。但是,如果你尝试将ServiceA类中声明的BeanA,BeanB调换一下位置,你就会发现这段代码突然就跑的通了!!!
显然,调换这两个Bean的依赖的顺序本质是调整了Spring加载Bean的顺序(众所周知,Spring创建Bean是单线程的)。
解释
相信你已经发现问题了,没错,问题的症结就在于ConfigurationA这个配置类。
配置类和普通的Bean有一个区别,就在于除了同样作为Bean被管理之外,配置类也可以在内部声明其他的Bean。
这样就存在一个问题,配置类中声明的其他Bean的构造过程其实是属于配置类的业务逻辑的一部分的。也就是说我们只有先将配置类的依赖全部满足之后才可以创建他自己声明的其他的Bean。(如果不加这个限制,那么在创建自己声明的其他Bean的时候,如果用到了自己的依赖,则有空指针的风险。)
这样一来,BeanA对ConfigurationA就不再是弱依赖,而是实打实的强依赖了(也就是说ConfigurationA的初始化不仅影响了BeanA的依赖填充,也影响了BeanA的实例构造)。
有了这样的认识,我们再来分别分析两种初始化的路径。
先加载BeanA
当Spring在试图加载ServiceA时,先构造了ServiceA,然后发现他依赖BeanA,于是就试图去加载BeanA;
Spring想构造BeanA,但是发现BeanA在ConfigurationA内部,于是又试图加载ConfigurationA(此时BeanA仍未构造);
Spring构造了ConfigurationA的实例,然后发现他依赖BeanB,于是就试图去加载BeanB。
Spring构造了BeanB的实例,然后发现他依赖BeanA,于是就试图去加载BeanA。
Spring发现BeanA还没有实例化,此时Spring发现自己回到了步骤2。。。GG。。。
先加载BeanB
当Spring在试图加载ServiceA时,先构造了ServiceA,然后发现他依赖BeanB,于是就试图去加载BeanB;
Spring构造了BeanB的实例,然后发现他依赖BeanA,于是就试图去加载BeanA。
Spring发现BeanA在ConfigurationA内部,于是试图加载ConfigurationA(此时BeanA仍未构造);
Spring构造了ConfigurationA的实例,然后发现他依赖BeanB,并且BeanB的实例已经有了,于是将这个依赖填充进ConfigurationA中。
Spring发现ConfigurationA已经完成了构造、填充了依赖,于是想起来构造了BeanA。
Spring发现BeanA已经有了实例,于是将他给了BeanB,BeanB填充的依赖完成。
Spring回到了为ServiceA填充依赖的过程,发现还依赖BeanA,于是将BeanA填充给了ServiceA。
Spring成功完成了初始化操作。
“分析Spring循环依赖的坑”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





