hbase读写请求
详细解释hbase的读写过程
读请求过程
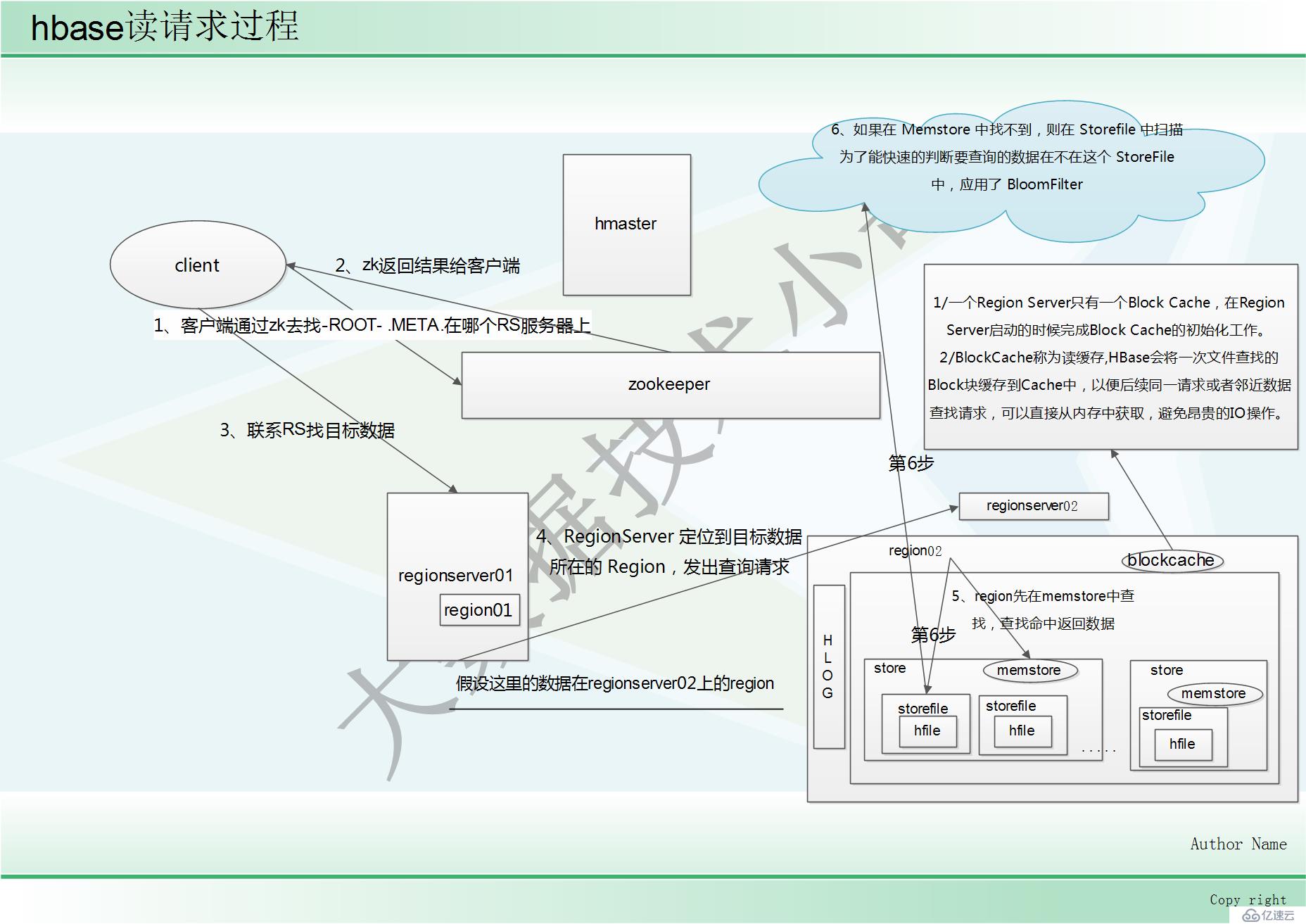
1、客户端通过 ZooKeeper 以及-ROOT-表和.META.表找到目标数据所在的 RegionServer(就是 数据所在的 Region 的主机地址)
2、zk返回结果给客户端
3、联系 RegionServer 查询目标数据
4、RegionServer 定位到目标数据所在的 Region,发出查询请求
5、Region 先在 Memstore 中查找,命中则返回
6、如果在 Memstore 中找不到,则在 Storefile 中扫描 为了能快速的判断要查询的数据在不在这个 StoreFile 中,应用了 BloomFilter
(BloomFilter,布隆过滤器:迅速判断一个元素是不是在一个庞大的集合内,但是他有一个 弱点:它有一定的误判率)
(误判率:原本不存在与该集合的元素,布隆过滤器有可能会判断说它存在,但是,如果 布隆过滤器,判断说某一个元素不存在该集合,那么该元素就一定不在该集合内)
BlockCache
1、BlockCache称为读缓存
2、HBase会将一次文件查找的Block块缓存到Cache中,以便后续同一请求或者邻近数据查找请求,可以直接从内存中获取,避免昂贵的IO操作。
此部分参考链接:https://blog.51cto.com/12445535/2363376
hbase写请求
//深度了解hbase的写请求,请阅读:hbase数据写入流程深度解析 https://blog.51cto.com/12445535/2370653
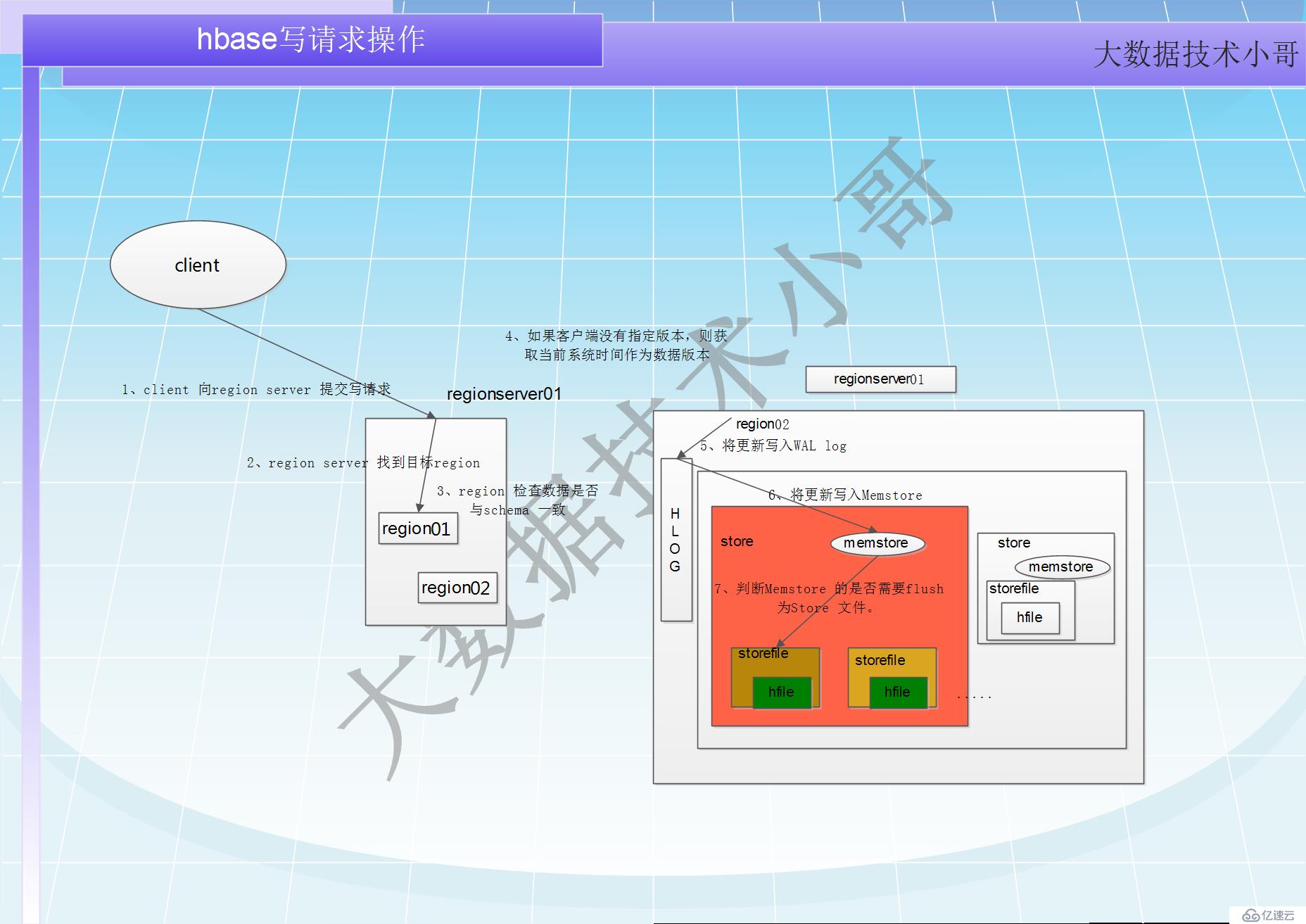
写请求处理过程小结
1 client 向region server 提交写请求
2 region server 找到目标region
3 region 检查数据是否与schema 一致
4 如果客户端没有指定版本,则获取当前系统时间作为数据版本
5 将更新写入WAL log
6 将更新写入Memstore
7 判断Memstore 的是否需要flush 为Store 文件。
Hbase 在做数据插入操作时,首先要找到 RowKey 所对应的的 Region,怎么找到的?其实这 个简单,因为.META.表存储了每张表每个 Region 的起始 RowKey 了。
建议:在做海量数据的插入操作,避免出现递增 rowkey 的 put 操作
如果 put 操作的所有 RowKey 都是递增的,那么试想,当插入一部分数据的时候刚好进行分 裂,那么之后的所有数据都开始往分裂后的第二个 Region 插入,就造成了数据热点现象。
写请求过程 //细节描述
上面提到,hbase 使用MemStore 和StoreFile 存储对表的更新。
1、数据在更新(写)时首先写入Log(WAL log)和内存(MemStore)中,MemStore 中的数据是排序的,当MemStore 累计到一定阈值时,就会创建一个新的MemStore,并且将老的MemStore 添加到flush 队列,由单独的线程flush 到磁盘上,成为一个StoreFile。
2、于此同时,系统会在zookeeper 中记录一个redo point,表示这个时刻之前的变更已经持久化了。(minor compact)
3、当系统出现意外时,可能导致内存(MemStore)中的数据丢失,此时使用Log(WAL log)来恢复checkpoint 之后的数据。
4、前面提到过StoreFile 是只读的,一旦创建后就不可以再修改。因此Hbase 的更新其实是不断追加的操作。
5、当一个Store 中的StoreFile 达到一定的阈值后,就会进行一次合并(major compact),将对同一个key 的修改合并到一起,形成一个大的StoreFile,当StoreFile 的大小达到一定阈值后,又会对StoreFile 进行split,等分为两个StoreFile。
6、由于对表的更新是不断追加的,处理读请求时,需要访问Store 中全部的StoreFile 和MemStore,将他们的按照row key 进行合并,由于StoreFile 和MemStore 都是经过排序的,并且StoreFile 带有内存中索引,合并的过程还是比较快。
提示:
Client 写入 -> 存入 MemStore,一直到 MemStore 满 -> Flush 成一个 StoreFile,直至增长到 一定阈值 -> 触发 Compact 合并操作 -> 多个 StoreFile 合并成一个 StoreFile,同时进行版本 合并和数据删除 -> 当 StoreFiles Compact 后,逐步形成越来越大的 StoreFile -> 单个 StoreFile 大小超过一定阈值后,触发 Split 操作,把当前 Region Split 成 2 个 Region,Region 会下线, 新 Split 出的 2 个孩子 Region 会被 HMaster 分配到相应的 HRegionServer 上,使得原先 1 个 Region 的压力得以分流到 2 个 Region 上由此过程可知,HBase 只是增加数据,有所得更新 和删除操作,都是在 Compact 阶段做的,所以,用户写操作只需要进入到内存即可立即返 回,从而保证 I/O 高性能。
写入数据的过程补充:
工作机制:每个 HRegionServer 中都会有一个 HLog 对象,HLog 是一个实现 Write Ahead Log 的类,每次用户操作写入 Memstore 的同时,也会写一份数据到 HLog 文件,HLog 文件定期 会滚动出新,并删除旧的文件(已持久化到 StoreFile 中的数据)。当 HRegionServer 意外终止 后,HMaster 会通过 ZooKeeper 感知,HMaster 首先处理遗留的 HLog 文件,将不同 Region 的 log数据拆分,分别放到相应 Region 目录下,然后再将失效的 Region(带有刚刚拆分的 log) 重新分配,领取到这些 Region 的 HRegionServer 在 load Region 的过程中,会发现有历史 HLog 需要处理,因此会 Replay HLog 中的数据到 MemStore 中,然后 flush 到 StoreFiles,完成数据 恢复。
参考链接为:https://www.cnblogs.com/qingyunzong/p/8692430.html
http://hbasefly.com/2016/03/23/hbase_writer/
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





