(1)MapReduce的发展:
MRv1的缺点:
早在 Hadoop1.x 版本,当时采用的是 MRv1 版本的 MapReduce 编程模型。MRv1 版本的实现 都封装在 org.apache.hadoop.mapred 包中,MRv1 的 Map 和 Reduce 是通过接口实现的。
MRv1 只有三个部分: 运行时环境(JobTracker 和 TaskTracker)、编程模型(MapReduce)、 数据处理引擎(MapTask 和 ReduceTask)。可扩展性差:在运行时,JobTracker 既负责资源管理又负责任务调度,当集群繁忙时, JobTracker 很容易成为瓶颈,最终导致它的可扩展性问题。
可用性差:采用了单节点的 Master,没有备用 Master 及选举操作,这导致一旦 Master 出现故障,整个集群将不可用。(单点故障)
资源利用率低:TaskTracker 使用“slot”等量划分本节点上的资源量。slot 分为 Map slot 和 Reduce slot 两种,分别供 MapTask 和 ReduceTask 使用。有时会因为作业刚刚启动等原因导致 MapTask 很多,而 Reduce Task 任 务还没有调度的情况,这时 Reduce slot 也会被闲置。
不能支持多种MapReduce框架:无法通过可插拔方式将自身的 MapReduce 框架替换为其他实现,如 Spark、Storm 等。
2. MRv2的缺点:
MRv2中,重用了 MRv1 中的编程模型和数据处理引擎。但是运行时环境被重构了。JobTracker 被拆分成了通用的:资源调度平台(ResourceManager,简称 RM)、节点管理器(NodeManager)、负责各个计算框架的任务调度模型(ApplicationMaster,简称 AM)。但是由于对 HDFS 的频繁操作(包括计算结 果持久化、数据备份、资源下载及 Shuffle 等)导致磁盘 I/O 成为系统性能的瓶颈,因此只适用于离线数据处理或批处理,而不能支持对迭代式、交互式、流式数据的处理。
(2)Spark的优势:
减少了磁盘的I/O:Spark 允许将 map 端的中间输出和结果存储在内存中,reduce 端在拉取中间结果时避免了大量的磁盘 I/O。Spark 将应用程序上传的资源文件缓冲到 Driver 本地文件服务的内存中,当 Executor 执行任务时直接从 Driver 的内存 中读取,也节省了大量的磁盘 I/O。
增加并行度:park 把不同的环节抽象为 Stage,允许多个 Stage 既可以串行执行,又可以并行执行。
避免重复计算:当 Stage 中某个分区的 Task 执行失败后,会重新对此 Stage 调度,但在重新 调度的时候会过滤已经执行成功的分区任务,所以不会造成重复计算和资源浪费。
可选择的shuffle:Spark 可以根据不同场景选择在 map 端排序或者 reduce 端排序。
灵活的内存管理策略:Spark 将内存分为堆上的存储内存、堆外的存储内存、堆上的执行内存、堆外的执行内存 4 个部分。Spark 既提供了执行内存和存储内存之间是固定边界的实现,又提供了执行内存和存储内存之间是“软”边界的实现。Spark 默认使用“软”边界的实现,执行内存或存储内存中的任意一方在资源不足时都可以借用另一方的内存,最大限度的提高 资源的利用率,减少对资源的浪费。。Spark 由于对内存使用的偏好,内存资源的多寡和使用 率就显得尤为重要,为此 Spark 的内存管理器提供的 Tungsten 实现了一种与操作系统的内存 Page 非常相似的数据结构,用于直接操作操作系统内存,节省了创建的 Java 对象在堆中占 用的内存,使得 Spark 对内存的使用效率更加接近硬件。Spark 会给每个 Task 分配一个配套 的任务内存管理器,对 Task 粒度的内存进行管理。Task 的内存可以被多个内部的消费者消费,任务内存管理器对每个消费者进行 Task 内存的分配与管理,因此 Spark 对内存有着更细粒度的管理
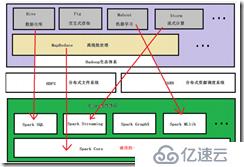
(3)spark生态:
Spark 生态圈以 SparkCore 为核心,从 HDFS、Amazon S3 或者 HBase 等持久层读取数据,以 MESOS、YARN 和自身携带的 Standalone 为资源管理器调度 Job 完成 Spark 应用程序的计算。
SparkShell/SparkSubmit 的批处理
SparkStreaming 的实时处理应用
SparkSQL 的结构化数据处理/即席查询
BlinkDB 的权衡查询
MLlib/MLbase的机器学习、GraphX的图处理和PySpark的数学/科学计算和SparkR的数据分析。
(4)spark特点:
Seed快速高效:Spark 允许将中间输出和结果存储在内存中,节省了大量的磁盘 IO。Apache Spark 使用最先进的 DAG 调度程序,查询优化程序和物理执行引擎,实现批量和流式数据的高性能。同时 Spark 自身的 DAG 执行引擎也支持数据在内存中的计算。Spark 官网声称性能比 Hadoop 快 100 倍。即便是内存不足需要磁盘 IO,其速度也是 Hadoop 的 10 倍以上
Generality:全栈式数据处理:支持批处理、支持交互式查询、支持交互式查询、支持机器学习、支持图计算。
Ease of Use 简洁易用:Spark 现在支持 Java、Scala、Python 和 R 等编程语言编写应用程序,大大降低了使用者的门槛。自带了 80 多个高等级操作符(算子),允许在 Scala,Python,R 的 shell 中进行交互式查询,可 以非常方便的在这些 Shell 中使用 Spark 集群来验证解决问题的方法。
可用性高:Spark 也可以不依赖于第三方的资源管理和调度器,它实现了 Standalone 作为其 内置的资源管理和调度框架,这样进一步降低了 Spark 的使用门槛,使得所有人都可以非常 容易地部署和使用 Spark,此模式下的 Master 可以有多个,解决了单点故障问题。当然,此模式也完全可以使用其他集群管理器替换,比如 YARN、Mesos、Kubernetes、EC2 等。
丰富的数据源支持:Spark 除了可以访问操作系统自身的本地文件系统和 HDFS 之外,还可 以访问 Cassandra、HBase、Hive、Tachyon(基于内存存储) 以及任何 Hadoop 的数据源。这极大地方便了已经 使用 HDFS、HBase 的用户顺利迁移到 Spark。
(5)spark的应用场景:
① Yahoo 将 Spark 用在 Audience Expansion 中的应用,进行点击预测和即席查询等
② 淘宝技术团队使用了 Spark 来解决多次迭代的机器学习算法、高计算复杂度的算法等。 应用于内容推荐、社区发现等
③ 腾讯大数据精准推荐借助 Spark 快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通 PCTR 投放 系统上。
优酷土豆将 Spark 应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等 迭代计算。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。