这篇文章主要讲解了“Python爬虫怎么绕过登录页面”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Python爬虫怎么绕过登录页面”吧!
前言
很多时候我们做 Python 爬虫时或者自动化测试时需要用到 selenium 库,我们经常会卡在登录的时候,登录验证码是最头疼的事情,特别是如今的文字验证码和图形验证码。文字和图形验证码还加了干扰线,本文就来讲讲怎么绕过登录页面。
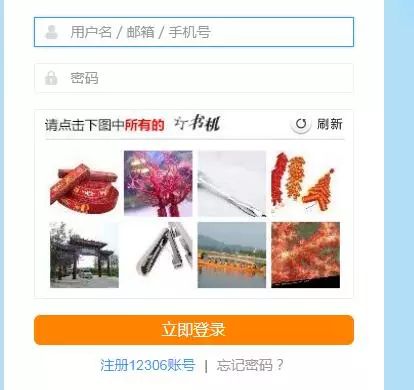
登录页面的验证,比如以下的图形验证码。

还有我们基本都看过的 12306 的图形验证码。
绕过登录基本有两种方法,第一种方法是登录后查看网站的 cookie,请求 url 的时候把 cookie 带上,第二种方法是启动浏览器带上浏览器的全部信息,包括添加的书签和访问网页的 cookie 信息。
第一种 cookie 方法我们要分析别人网站的 cookie 值,找出相应的值然后添加进去,对于我们不熟的网站,他们可能也会做加密或者动态处理,所以有些网站也不是那么好操作。如果是自己公司的网站需要测试,我们可以询问对应的开发那个 cookie 值是区分独立用的值,拿出来放在请求里面就行。
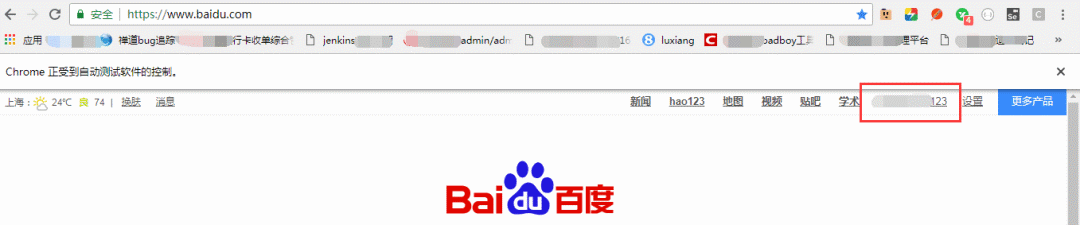
比如我们登录百度账号比较费劲,每次都需要登录也比较繁琐,我们 F12 打开页面调试工具,登录后找到 www.baidu.com 文件,在 cookie 中,我们发现很多值,其中图中圈起来的就是我们要找的值。
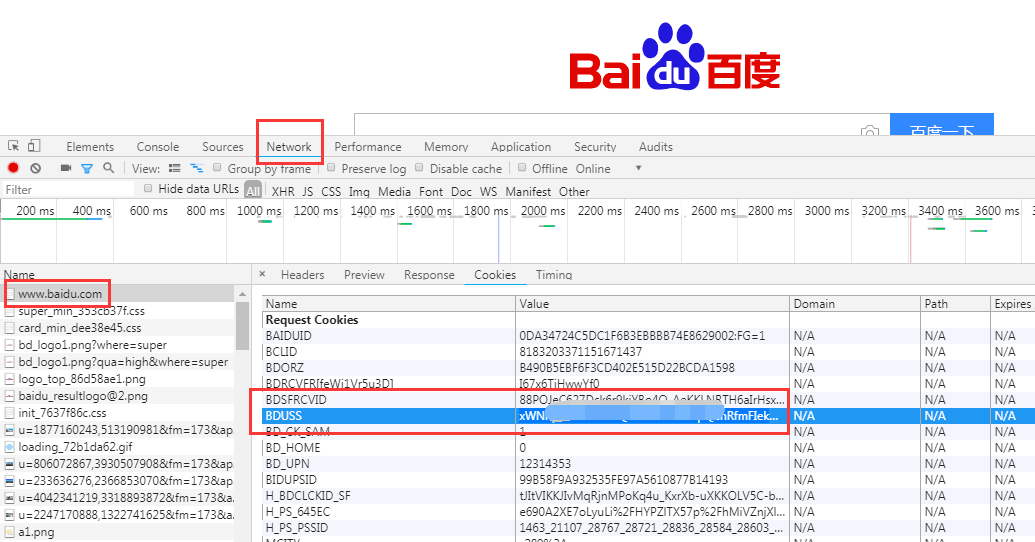
我们在访问 baidu 链接的时候加上这个 cookie 值,这样就是直接登录后的百度账号了。
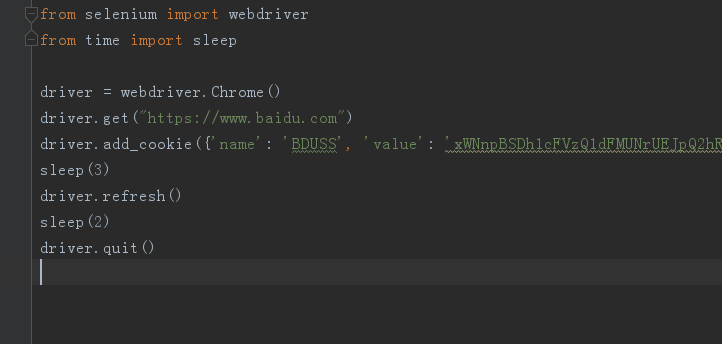
我们要 selenium 启动浏览器时,需要下载后对应的驱动文件并放在 Python 安装的根目录下,比如我会用到谷歌 Chrome 浏览器和 Firefox 火狐浏览器。
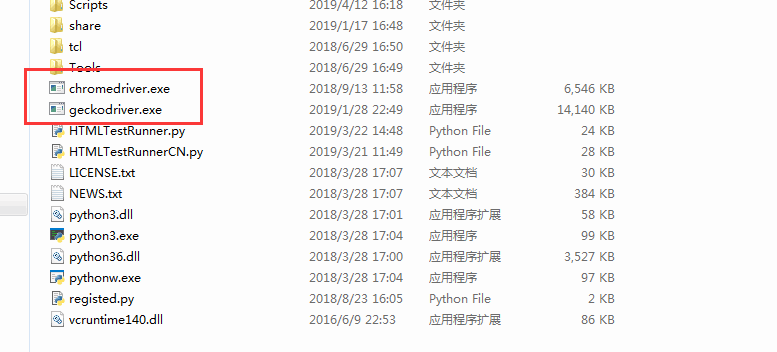 谷歌浏览器驱动下载地址:
谷歌浏览器驱动下载地址:
http://chromedriver.storage.googleapis.com/index.html
火狐浏览器驱动下载地址:
https://github.com/mozilla/geckodriver/releases/
我们每次打开浏览器做相应操作时,对应的缓存和 cookie 会保存到浏览器默认的路径下,我们先查看个人资料路径,以 chrome 为例,我们在地址栏输入 chrome://version/

图中的个人资料路径就是我们需要的,我们去掉后面的 \Default,然后在路径前加上「–user-data-dir=」就拼接出我们要的路径了。
profile_directory = r'--user-data-dir=C:\Users\xxx\AppData\Local\Google\Chrome\User Data'
接下来,我们启动浏览器的时候采用带选项时的启动,这种方式启动浏览器需要注意,运行代码前需要关闭所有的正在运行 chrome 程序,不然会报错。全部代码如下。

selenium 自动化启动浏览器后我们会发现我之前保存的书签完整在浏览器上方,baidu 账号也是登录的状态。
 启动 Firfox 浏览器绕过登录
启动 Firfox 浏览器绕过登录
Firfox 火狐浏览也可以这样启动它,设置略有不同。
首先,查看配置文件的存储路径,查看方法:帮助–故障排除信息–配置文件夹,把里面的路径复制过来就行。
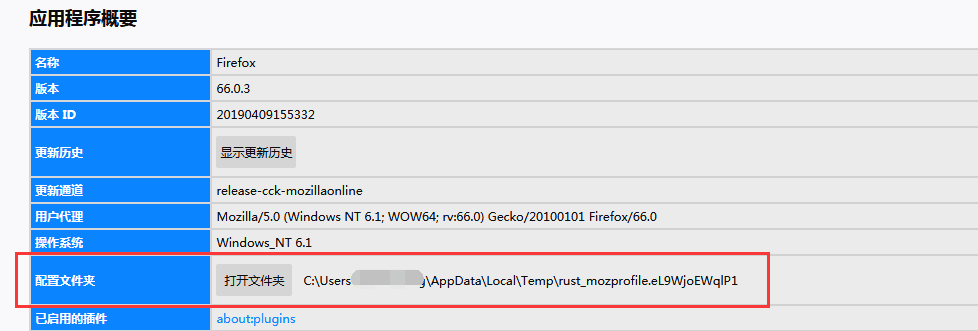
同样,我们把路径放在变量中。
profile_path = <span class="hljs-string">r'C:\Users\guixianyang\AppData\Roaming\Mozilla\Firefox\Profiles\dvm6wqam.default'</span>
我们也在火狐浏览器中登录好百度的账号,用 selenium 自动化启动带配置文件的火狐浏览器,也会发现启动时已经启动了浏览器安装的插件和登录好的百度账号。

文中第一个图是简书登录时的图形验证码,我们登录简书后(cookie 有一定的时效,貌似有 10 天半个月左右),把上面代码中的链接换成简书的,再用上面的方法觉可以实现绕过登录页的图形验证码。
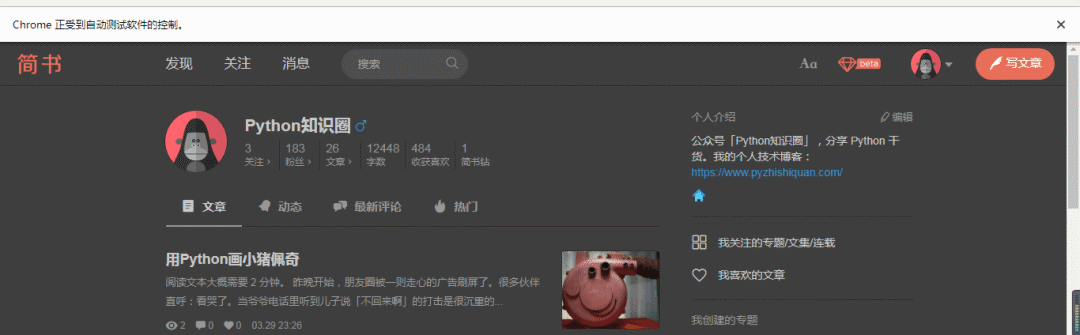
比如我直接打开我的简书个人主页
https://www.jianshu.com/u/52353ffa8b86
自动化启动后也是保留了登录的状态。
网站的登录大门已被打开,接下来就可以做自己想做的事情了,比如爬虫、自动化测试验证之类的。
感谢各位的阅读,以上就是“Python爬虫怎么绕过登录页面”的内容了,经过本文的学习后,相信大家对Python爬虫怎么绕过登录页面这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





