如何解析分布式资源调度框架YARN,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
我们先来了解一下MapReduce 1.x的架构以及存在的问题。
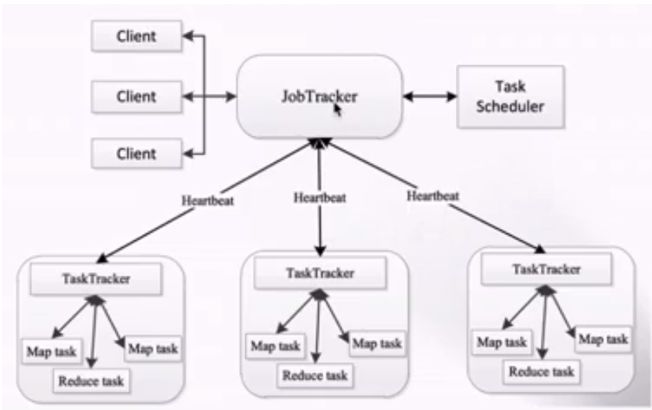
如图所示,1.x的架构也采用的是主从结构:即master-slaves架构,一个JobTracker带多个TaskTracker
JobTracker:负责资源管理和作业调度;Tasktracker 向jobtracker定期汇报本节点的健康状况、资源使用情况、作业执行情况;同时也接收来自JobTracker的命令,负责启动和杀死任务的具体执行。MapReduce作业拆分成Map任务和Task任务,由TaskTracker负责执行和汇报。
这样的架构存在的缺点:
只有一个JobTracker负责集群事务的集中处理,存在单点故障。且压力大不易扩展。
JobTracker需要完成得任务太多,既要维护job的状态又要维护job的task的状态,造成资源消耗过多
仅仅只能支持MR作业。不支持其他计算框架,如spark,storm等。
存在多个集群,如Spark集群,hadoop集群同时存在,不能够统一管理,资源利用率较低,彼此之间没有办法共享资源,运维成本高。
Yet Another Resource Negotiator。是一个操作系统级别的资源调度框架。
MRv2 最基本的想法是将原 JobTracker 主要的资源管理和 Job 调度/监视功能分开作为两个单独的守护进程。有一个全局的ResourceManager(RM)和每个 Application 有一个ApplicationMaster(AM),Application 相当于 MapReduce Job 或者 DAG jobs。ResourceManager和 NodeManager(NM)组成了基本的数据计算框架。ResourceManager 协调集群的资源利用,任何 Client 或者运行着的 applicatitonMaster 想要运行 Job 或者 Task 都得向 RM 申请一定的资源。ApplicatonMaster 是一个框架特殊的库,对于 MapReduce 框架而言有它自己的 AM 实现,用户也可以实现自己的 AM,在运行的时候,AM 会与 NM 一起来启动和监视 Tasks。
reference:https://blog.51cto.com/14048416/2342195
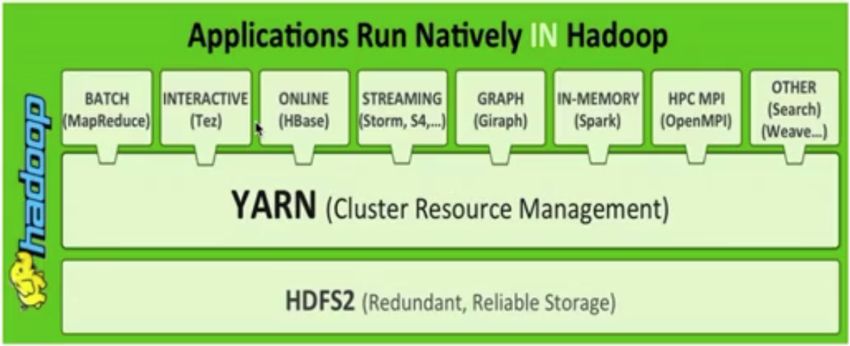
上图显示了YARN的位置:位于HDFS之上,多种应用程序之下。这样多种不同类型的计算框架都可以运行在同一个集群里面,共享同一个HDFS集群上的数据,享受整体的资源调度。也就是 XXX on YARN,例如Spark on YARN,Spark on YARN,MapReduce on Yarn,Storm on YARN,Flink on YARN。好处是与其他计算框架共享集群资源,按自愿需要分配,进而提高集群资源的利用率。
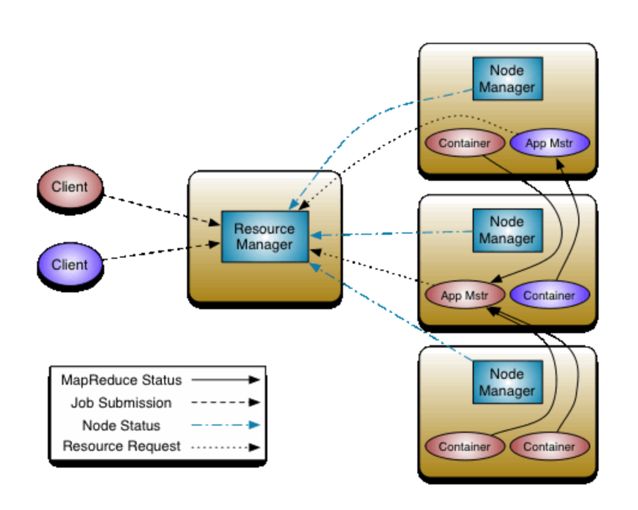
YARN的架构中包含ResourceManager(RM),NodeManager(NM),ApplicationMaster(AM),Container,Client供5种核心组件,依然是一种主从结构,即1个RM+N个NM的形式。它们的作用如下:
1)RM:整个集群同一时间提供服务的只有一个,(生产上多采用一主一备的方式防止故障发生),负责集群资源的统一管理和调度。主要承担的任务由:
处理客户端的请求:提交一个作业,杀死一个作业。
监控NM,如果某个NM发生故障,将该NM上运行的任务告诉AM,由AM决定是否重新运行相应task。
2)NM:整个集群中有多个,负责自身节点资源管理和使用。它承担的任务由:
定时向RM汇报本节点的资源使用情况和自身的健康状况。
接收并处理来自RM的各种命令,比如启动Container运行AM。
处理来自AM的命令,如启动Container运行task。
单个节点的资源管理
3)AM:每个应用程序对应一个AM,(每一个MapReduce作业,每一个Spark作业对应一个),负责对应的应用程序管理。
为应用程序向RM申请资源(core、memory等),之后进行分配
需要与NM进行通信:启动或者停止task,task和AM都是是运行在Container中的。
一个NM可能运行很多task,这些task分属于不同的AM
4)Container
封装了CPU Memory等资源的一个容器,是一个任务运行环境的抽象。
AM运行在Container里面,task也是
5)Client:客户端
发起响应的请求,例如:
提交作业,查看作业运行进度
杀死作业

①客户端提交task 请求到RM
②③RM先到NM上启动1个Container,用来运行AM。
④AM启动之后,注册到RM上。(任务是由AM管理的,注册之后,用户就可以通过RM查询AM上的作业进度)并向NM申请资源(Core Memory),RM给AM分配相应的NM资源,
⑤⑥AM下发指令给相应的的NM,NM启动Container运行task 。
这就是YARN执行的一个基本流程,这是一个通用的流程,MapReduce作业对应MapReduce的Application master,Spark作业对应Spark的Application Master,其他的作业也有相应的Application Master。
我们在前面进行了YARN的配置,参考hadoop中Yarn的配置与使用示例,主要有mapred-site.xml和yarn-site.xml两个配置文件,在启动时有一个start-yarn.sh 命令,就是用来启动RM和NM的(使用stop-yarn.sh停止YARN的进程)。启动YARN之后,我们就可以在web浏览器上可以查看YARN集群的情况。包括当前节点的情况,任务的运行状态等。
关于如何解析分布式资源调度框架YARN问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





