大数据处理架构Hadoop
1.概述
1.1 Hadoop 简介
hadoop是apache软件基金会旗下的一个开源分布式计算平台,为用户提供系统底层细节透明的分布式基础架构。hadoop基于java语言
开发。跨平台性能好,可以部署在廉价的计算机集群中。hadoop核心是HDFS(分布式文件系统,解决了海量数据的存储)和mapreduce
(解决了海量数据的处理)。hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据段 处理能力。
2008年4月,hadoop打破当时的世界记录成为最快排序1TB数据的系统,他采用901个节点构成的集群运算,排序时间只用209S。
1.2 Hadoop的发展简史
hadoop最初由apache Lucene项目的创始人Doug Cutting 开发的文本索引库。2002年的时候,Nutch项目(Lucene项目一部分)遇到
了该框架无法扩展到拥有数十亿网页的网络。2003年的时候Google 发布了分布式文件系统GFS的论文,2004年Nutch项目模仿GFS开发了
NDFS(HDFS前身)。2004年,谷歌公司有发布了MapReduce分布式编程思想的论文。2005年Nutch 项目开源了谷歌的MapReduce。
至此。hadoop的两个核心HDFS和MapReduce ,受谷歌论文的影响,成就了hadoop在海量数据处理灵域的头羊领袖地位。2008年一月,
Hadoop正式成为apache顶级的项目。
1.3 hadoop 特性
高可用性 : 采用冗余存储方式
高效性:采用分布式存储和分布式处理,搞笑的处理PB级数据
高可扩展性:hadoop设计目的:高效稳定运行在廉价的计算机集群上。
高容错性:采用冗余数据存储方式。
低成本:采用廉价的计算机集群。
运行在linux平台。
支持多种编程语言。
1.4 hadoop的版本
apache hadoop版本分为两代,第一代hadoop包含0.20x ,0.21.x和0.22.x三个版本。其中,0.20x最后演变成1.0.x,成为稳定版。
0.21.x和0.22.x增加了HDFS HA(高可用)等重要特性。第二代hadoop包含0.23.x和2.x两个版本。
第二代hadoop比第一代hadoop做了较大的改进:主要是拆分了MapReduce的职能,减轻了系统负载。增加了YARN资源调度框架,
mapreduce 运行在YARN框架(负责系统资源的调度的基础上,不在负责系统资源的调度,只专心于分布式计算。做为hadoop另一个核心
的HDFS也增加了 federation 和HA(高可用和热备份)(HDFS中的namenode需要高可用)
apache的各个版本的比较:
除了免费开源apache hadoop版本提供标准,还有一些商业化公司陆续退出hadoop版本。
2014年进入上海的 cloudera 与apache hadoop功能同步部分开源,具有自主研发产品,impala、navigator
hortonwork 与apache 功能同步也完全开源(是apache hadoop平台最大的贡献者。产品:Tez构架,下一代hadoop查询处理框架)
MapR 在apache hadoop基础上修改优化了许多,也形成了自己的 产品。
国产的有 星环。核心组件与apache 同步,底层较多,完全封闭闭源,也又自己的hadoop产品 Inceptor 、Hyperbase.
1.41 hadoop在企业的应用构架分为3层:数据源的流向依次是数据来源 ==》大数据层==》访问层
在大数据层以HDFS分布式存储为基础;分为三部分。分别为访问层的3个功能即:数据分析、数据实时查询、数据挖掘提供运算。
其中大数据层的: mapreduce (hive, pig) 提供了离线数据分析
Hbase(solr redis) 提供了数据的实时查询
Mahout BI分析 完成 数据挖掘
1.5 hadoop生态系统
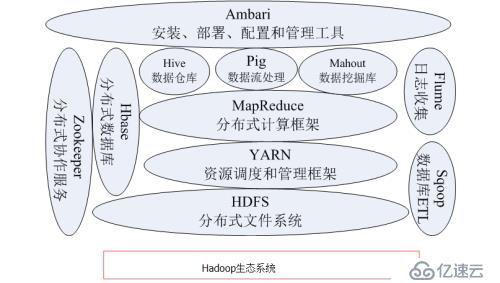
1.51 HDFS
分布式文件系统(Hadoop Distributed File System HDFS)是Hadoop项目的核心。针对谷歌文件系统GFS的开源。
具有处理超大数据、流式处理运行在廉价服务器等优点。在设计之初,吧硬件故障作为常态考虑,保证在部分硬件发生故障的时候
仍能保障整体的可用性和可靠性。此外,HDFS放宽了POSIX(可移植操作系统接口)实现了流的形式访问系统数据。提高系统的
吞吐率。
1.52 HBase
针对谷歌BigTable的开源实现。具有强大的非结构化数据存储能力。采用HDFS作为底层数据存储,与传统数据库基于列的存储
方式不同,HBase是基于行的存储。可横向扩展。是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库。
1.53 MapReduce
针对谷歌的MapReduce的开源实现。是一种编程模型。高度抽象到两个函数上 Map 和 Reduce 。在不了解底层细节情况下开发
并行应用程序,运行在廉价计算机集群,完成海量数据(大于1T)处理核心思想是:将数据分成若干独立的数据块。分发给一个节点
管理下的各个分界点来共同并行完成,最后最后整合各个节点中间结果得到最终结果。
1.54 Hive
基于hadoop的数据仓库工具。针对hadoop文件中的数据集进行数据整理、特殊查询和分析存储。使用类SQL语言的Hive-QL
快速实现简单MapReduce统计。
1.55 Pig
简化了Hadoop常见的工作任务。为hadoop程序提供一种更加接近SQL的接口。在大型数据集中搜索满足某个给定搜索条件的记
录时,Pig 只需要编写一个简单的脚本在集群中自动并行处理与分发,而MapReduce需要编写一个单独程序。
1.56 Mahout
提供可扩展的机器学习领域经典算法。用于数据挖掘。
1.57 Zookeeper
针对谷歌Chubby的一个开源实现、是高效和可靠的协同工作系统,用于构建分布式应用,减轻分布式应用程序所承担的协调任务。
1.58 Flume
是 Cloudera提供的一个高可用的,高可靠的、分布式海量日志采集、聚合和传输的系统。支持日志系统中定制各类数据发送方,
用于收集数据;同时,Flume 提供对数据进行简单处理并写到各种数据接受方的能力。
1.59 Sqoop
SQL-to-Hadoop的缩写。用于Hadoop和关系数据库间交换数据,通过Sqoop可以将数据从mysql 、Oracle、postgresql等关系
型数据中导入Hadoop(可以导入HDFS、HBase和Hive)也可以将数据从hadoop导出到关系数据库。是数据迁移方便
1.510 Ambari
Web工具。支持Apache Hadoop 集群的安装、部署、配置和管理
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





