Hadoop
Server1.example.com 172.25.23.1 master
Server2.example.com 172.25.23.2 slave
Server3.example.com 172.25.23.3 slave
Server4.example.com 172.25.23.4 slave
Selinux iptables disabled 加解析(节点间可以ping通) sshd enaled
Hadoop1.2.1
一Master上进行存储计算等 单机
useradd -u 900 hadoop
echo westos | passwd --stdin hadoop
su - hadoop
1.安装java (若原来的机子上有java先卸载)
(1)
sh jdk-6u32-linux-x64.bin
mv jdk1.6.0_32 /home/hadoop
ln -s jdk1.6.0_32 java
(2)添加路径
vim .bash_profile
export JAVA_HOME=/home/hadoop/java
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$PATH:$JAVA_HOME/bin
source .bash_profile
2.设置hadoop
tar zxf hadoop-1.2.1.tar.gz
ln -s hadoop-1.2.1 hadoop
3.无密码ssh设置
ssh-keygen
ssh-copy-id 172.25.23.1
ssh 172.25.23.1 测试确保无密码
4.配置文件进行修改
(1)设置从节点
vim hadoop/conf/slave
172.25.23.1
(2)设置主节点
vim hadoop/conf/master
172.25.23.1
(3) 修改java的家路径
vim hadoop/conf/hadoop-env.sh

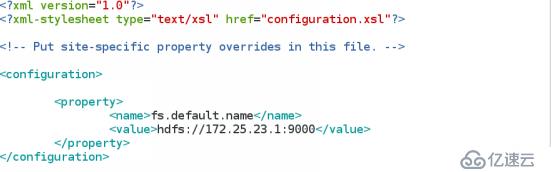
(4) 修改Hadoop核心配置文件core-site.xml配置的是HDFS的地址和端口号指定 namenode
vim hadoop/conf/core-site.xml
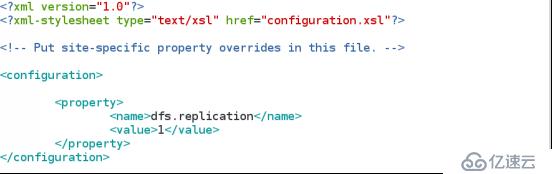
(5) 指定文件保存的副本数
vim hadoop/conf/hdfs-site.xml
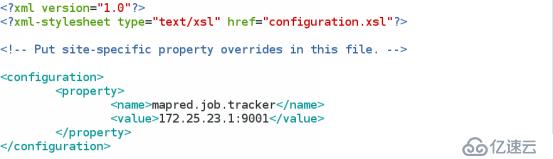
(6) 指定 jobtracker
vim hadoop/conf/mapred-site.xml
5.开启服务
(1) 格式化一个新的分布式文件系统
bin/hadoop namenode -format
(2) 启动 Hadoop 守护进程
bin/start-all.sh = bin/start-dfs.sh + bin/start-mapred.sh
(3) 查看进程
a)jps

b)bin/hadoop dfsadmin -report

7.一些hadoop的常用命令 ( 类似于linux的命令只是在前面增加了hadoop特有的 )
bin/hadoop fs -ls
mkdir input
cp conf/*.xml input
bin/hadoop jar hadoop-examples-1.2.1.jar grep input output 'dfs[a-z.]+'
bin/hadoop fs -cat output/*
bin/hadoop fs -put conf/ input
bin/hadoop fs -get output output
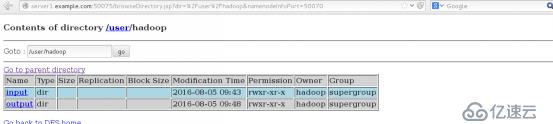
8.浏览 NameNode 和 JobTracker 的网络接口,它们的地址默认为:
NameNode – http://172.25.23.1:50070/
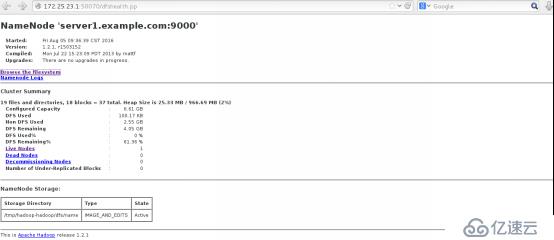
点击Browse the filesystem 下的 /user/hadoop/ 可看到上传的
JobTracker – http://172.25.23.1:50030/

二分布式部署
先停掉master上的相关服务bin/stop-all.sh再删掉/tmp/*
slave
1.目录设置
useradd -u 900 hadoop
2.确保master可以和slave无密码连接
yum install -y rpcbind
/etc/init.d/rpcbind start (nfs的一个中介服务用来通知客户端)
3.同步数据 (nfs)
(1) 在master端 (分享节点root下进行)
/etc/init.d/nfs start
vim /etc/exports

exportfs -rv
(2) 在slave端挂载
yum install -y nfs-utils
showmount -e 172.25.23.1

mount 172.25.23.1:/home/hadoop /home/hadoop
Master
1.修改配置文件
(1) vim hadoop/conf/slave
172.25.23.2
172.25.23.3
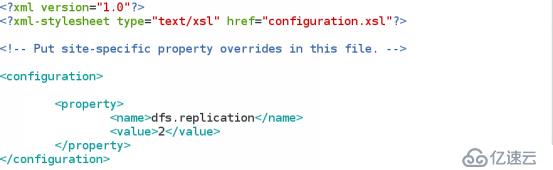
(2) vim hadoop/conf/hdfs-site.xml
datanade保存2份
2.查看master能否与slave进行无密码连接
ssh 172.25.23.2
若需要密码则进行如下操作
(1)进入hadoop用户查看权限显示(正确的应显示为hadoop)

(2)解析是否正确
(3)rpcbind是否开启
(4)若上述都正确则可进行
chkconfig rpcbind on
chkconfig rpcgssd on
chkconfig rpcidmapd on
chkconfig rpcsvcgssd on
reboot

则可无密码连接
3.启动服务
(1) 格式化一个新的分布式文件系统
bin/hadoop namenode -format
(2) 启动 Hadoop 守护进程
bin/start-all.sh
(3) 查看进程
master

slave

(4) 上传文件
bin/hadoop fs -put conf/ input
(5) 访问 172.25.23.150030
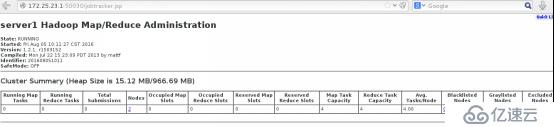
可看到有2个节点
172.25.23.150070
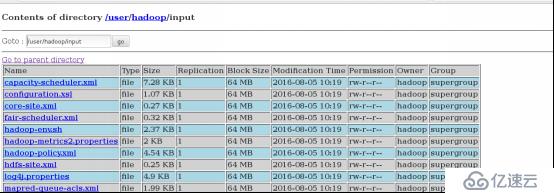
有文件上传
三新增一个从节点(172.25.23.4)且将文件转移
1.新增节点和已经配置好的从节点做相同的设置
yum install -y nfs-utils rpcbind
useradd -u 900 hadoop
/etc/init.d/rpcbind start
vim /etc/hosts
showmount -e 172.25.23.1
mount 172.25.23.1:/home/hadoop /home/hadoop
2.在master端修改slaves
添加 172.25.23.4
3.在新增的从节点上启动服务加入集群
bin/hadoop-daemon.sh start datanode
bin/hadoop-daemon.sh start tasktracker
4.在master上查看
bin/hadoop dfsadmin -report
......

......

可看到新增的节点
5.均衡数据:
bin/start-balancer.sh
1)如果不执行均衡,那么 cluster 会把新的数据都存放在新的 datanode 上,这样会降低 mapred的工作效率
2)设置平衡阈值,默认是 10%,值越低各节点越平衡,但消耗时间也更长bin/start-balancer.sh -threshold 5
6.数据转移删除
(1) vim hadoop/conf/mapred-site.xml
添加如下内容
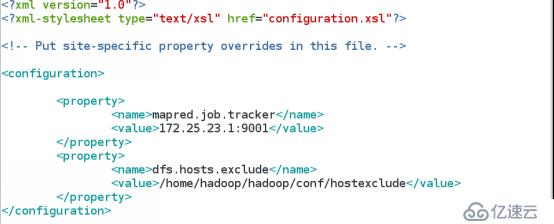
(2) 添加需要删除的主机名
vim /home/hadoop/hadoop/conf/hostexclude
172.25.23.3
(3) bin/hadoop dfsadmin -refreshNodes
此操作会在后台迁移数据,等此节点的状态显示为 Decommissioned,就可以安全关闭了。可以通过bin/hadoop dfsadmin -report查看 datanode 状态
在做数据迁移时,此节点不要参与 tasktracker,否则会出现异常。
(4) 删除tasktracker可在172.25.23.3上直接停止(上边都没有node节点了)
四恢复垃圾文件
1.编辑垃圾文件保留时间
vim hadoop/conf/core-site.xml
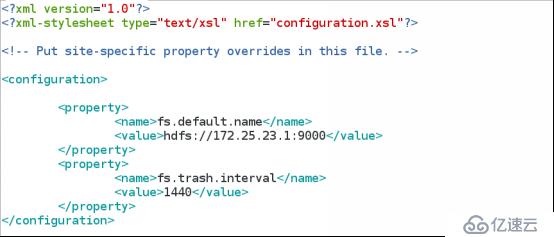
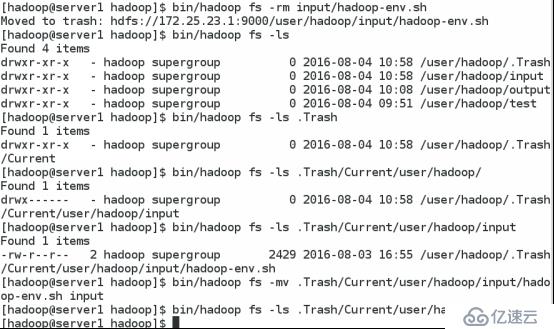
2.测试
删除文件可以发现多出了一个 .Trash目录逐层进入该目录直到找到所删除的文件再将该文件mv到原来所在的目录里。可以发现 .Trash里面已经没有文件了。
Hadoop2.6.4
分布式部署(所有主从节点全部切换到su - hadoop )
一在和1.2.1版本相同的环境目录nfs等都不变
本次配置使用的是1.2.1的机子(里面的host rpcbind nfs 为做修改)在重新配置2.6.4时先停掉所有的1.2.1版的hadoop服务删掉java等链接删除 /tmp/下的文件等
二Java配置
2.6.4的版本要求6或7的java版本
1.下载java安装包 (在hadoop的家目录下)
jdk-7u79-linux-x64.tar.gz
tar zxf jdk-7u79-linux-x64.tar.gz
ln -s jdk1.7.0_79/ java
2.配置java路径 (同1.2的配置相同)
3.查看 版本号java -version

三Hadoop的配置
cd hadoop/etc/hadoop
1. vim core-site.xml

2. vim hdfs-site.xml

3. cp mapred-site.xml.template mapred-site.xml
vim mapred-site.xml

4. vim yarn-site.xml

5. vim yarn-env.sh

6. vim etc/hadoop/hadoop-env.sh

7. vim slaves
172.25.23.2
172.25.23.3
172.25.23.4
四启动服务
1.格式化
tar xf hadoop-native-64-2.6.0.tar -C hadoop/lib/native lib中最好将原来的另外保存或删除将库文件改成64位的
bin/hdfs namenode -format
2.开启服务
sbin/start-dfs.sh sbin/start-yarn.sh
3.查看进程
master

slave

五、上传文件
1.创建保存的目录( V1版本是自动创建的 )
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop
2.上传文件
mkdir input
cp etc/hadoop/*.xml input
bin/hdfs dfs -put input
bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input output bin/hadoop jar hadoop-examples-1.2.1.jar wordcount input output
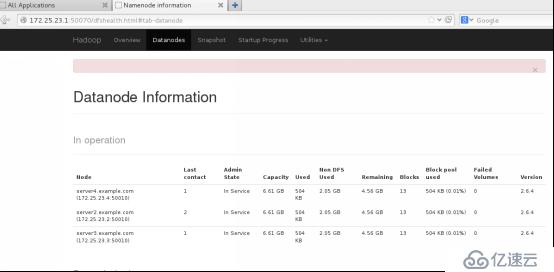
3.访问
172.25.23.1:8088

172.25.23.1:50070
将后面的.jsp改成 .html即可访问该页面
问题
1.datanade没有启动
在关闭节点时会发现 no datanade to stop 。
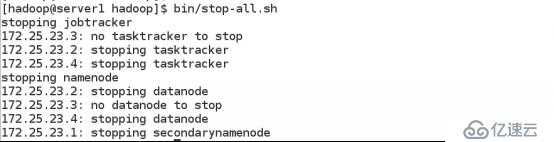
每次格式化后都会创建一个namenodeID而tmp下包含了上次的IDnamenode - format清除了namenode下的数据但是没有清空datanade下的数据导致启动失败因此每次格式化后都要清除掉主从节点下的/tmp/*的所有数据。
2.namenode in safe mode
执行bin/hadoop dfsadmin -safemode leave 即可
3.Exceeded MAX_FAILED_UNIQUE_FETCHES
这是因为程序中打开的文件太多了一般系统默认普通用户不得超过1024
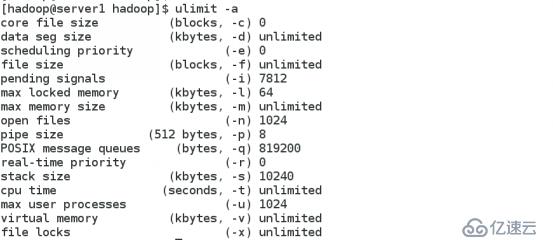
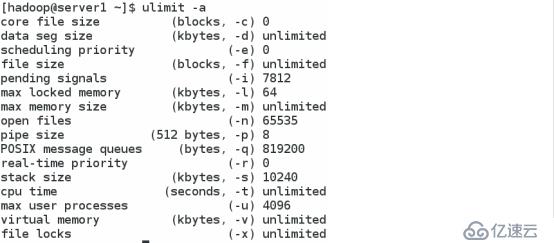
可以切换到root修改 /etc/security/limits.conf
添加 hadoop - nproc 4096
hadoop - nofile 65535
- 可代表的是软链接和硬链接 再切换到 hadoop 查看
4. vim hadoop/conf/core-site.xml
(在2.6.4下配置hadoop.tmp.dir参数)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://172.25.23.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/tmp/namedir</value>
</property>
<property>
<name>dfs.datanade.data.dir</name>
<value>/home/hadoop/tmp/datadir</value>
</property>
</configuration>
若没有配置这些参数则默认的临时目录是在/tmp/下而/tmp/目录每次重启都会清空必须重新format才可以
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





