虽然我们可以在Eclipse下面开发Hadoop应用程序,但是当我们引用了第三方jar文件的时候,把我们编写的程序打成jar包之后,如何能够在Hadoop集群下面运行,是一个我们在程序开发的过程中必须要解决的一个问题,通过搜索资料,在这里把几种可行的解决方案在这里总结一下。
本来打算也一篇的,可是写到后来,发现我太啰嗦了,写的有点太细了,决定分开来写,写成两篇好了。。。。
第一篇:主要写Eclipse下面引入第三方jar,以及打包在集群上运行。
第二篇:主要写Hadoop应用程序如何引入第三方jar,以及对生产环境下应该怎么去引入第三方jar的个人见解,文章链接《Hadoop应用引用第三方jar的几种方式(二)》
===========================================================================================
在这里先说一下Eclipse下面引入第三方jar的方法,这和下面的打成jar包有关系,一般来说有两种方法:一种方法是直接在本地磁盘的目录下,然后引入;另一种方法是在Eclipse工程根目录下面新建lib目录,然后引入。
第一种引入方法
在这里以Hadoop的提供的WordCount进行简单的修改来进行测试。代码如下:
package com.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import com.hadoop.hdfs.OperateHDFS;
public class WordCount {
public static class TokenizerMapper extends
Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//它什么都不做,就是为了测试引入第三方jar的,如果找不到,肯定就会报ClassNotFound异常
OperateHDFS s = new OperateHDFS();
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs =
new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(
otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
我把一个jar包放在的D盘的mylib目录下面,这个jar是上一篇文章《使用Hadoop提供的API操作HDFS》中的类打成的jar包
在工程右键Build Path==》Configure Build Path==》Add External JARs,找到上面目录下的jar文件,即可引入。此时如果在Eclipse下运行WordCount类,程序正确执行,没有问题。
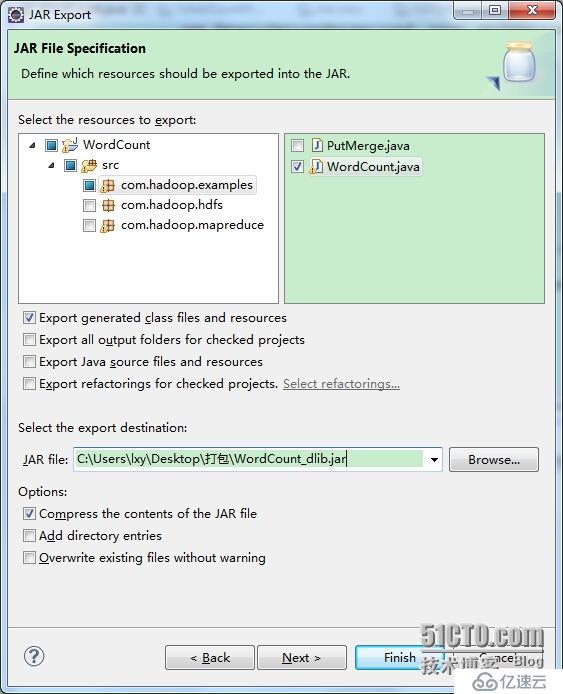
此时对整个工程打包的时候,你可以看到,打包的时候是没有机会选择引入的第三方jar包的,只能选择要打包的类,这里只选择了一个WordCount,打包过程如下所示
此时在Hadoop集群上面运行WordCount_dlib.jar,通过下面的命令运行:
hadoop jar WordCount_dlib.jar com.hadoop.examples.WordCount input outputdlib
不出意外,程序报ClassNotFound异常,结果如下所示

第二种引入方法
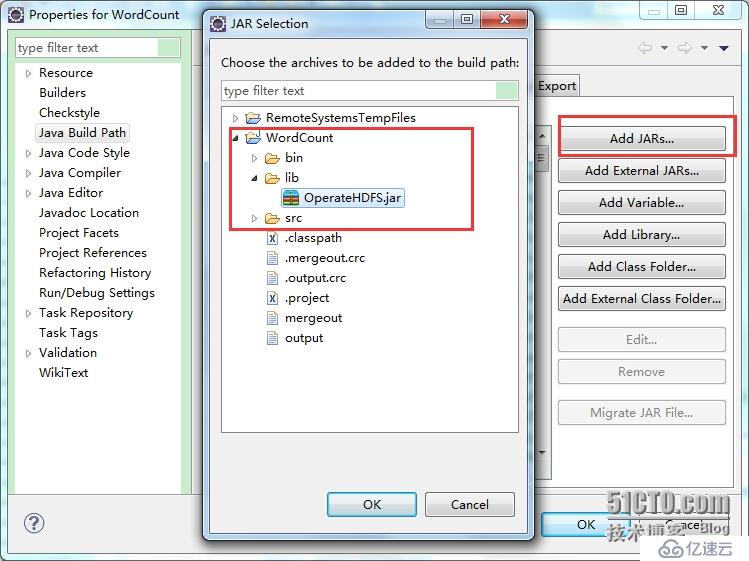
在项目的根目录(如果不是根目录,我没有进行测试是否可行)下新建lib目录(在工程上右键,新建文件夹),名字只能是lib,你换成其他的名字,它不会自动加载的。把上面的jar放到lib下面,然后在工程右键Build Path==》Configure Build Path==》Add JARs,找到工程目录lib下的jar文件,即可引入。此时如果在Eclipse下运行WordCount类,程序正确执行,没有问题。
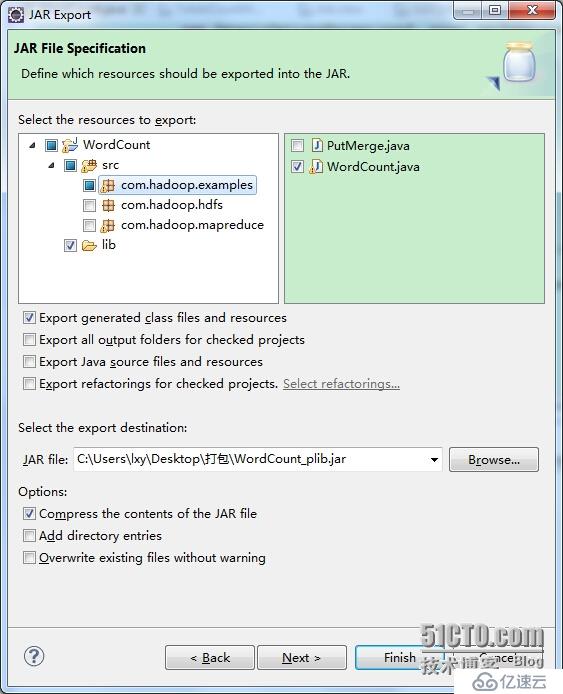
 此时对整个工程打包的时候,你可以看到,打包的时候是可以选择lib下的jar包的,也可以选择要打包的类,这里只选择了一个WordCount,打包过程如下所示
此时对整个工程打包的时候,你可以看到,打包的时候是可以选择lib下的jar包的,也可以选择要打包的类,这里只选择了一个WordCount,打包过程如下所示
此时在Hadoop集群上面运行WordCount_plib.jar,通过下面的命令运行:
hadoop jar WordCount_plib.jar com.hadoop.examples.WordCount input outputplib
程序可以正常运行,结果如下所示,
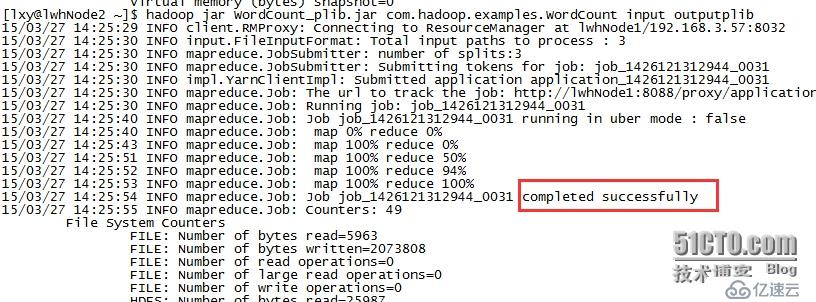
为什么会这样?就是因为WordCount_plib.jar内部有其使用到的jar,它能够自动的加载它内部的lib目录下面的jar。
名字如果存放jar的名字不是lib的话,虽然你也可以该目录下的jar文件一起打进入,但是它会报ClassNotFound的异常,我把lib的名称改成了mylib重新打成WordCount_mylib.jar,进行了测试运行,运行结果如下所示:
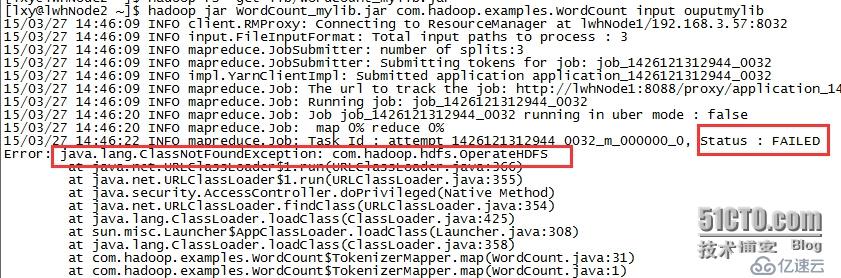
这就是我上面为什么强调,工程的根目录下,一定只能叫做lib才可以的原因。
文章中所涉及到的四个jar文件,我会以附件的放上来的。附件中的文件列表说明:
引入的第三方jar文件:OperateHDFS.jar 第一种方式引入jar包,打成的jar文件:WordCount_dlib.jar 第二种方式引入jar包,打成的jar文件:WordCount_plib.jar 第二种方式引入jar包,但是目录名称不叫做lib,叫做mylib,打成的jar文件WordCount_mylib.jar
文章太长了,剩下的部分再下一篇写。。。。。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。





